A Step-by-Step Guide to Building Geo-Distributed Applications
November 14, 2022
A geo-distributed application is designed to work across multiple availability zones and regions, ensuring high-availability, performance, and compliance. It must:
- Withstand various cloud outages (including major cloud incidents)
- Serve user requests at low latency regardless of user location
- Comply with data residency requirements
To design and implement geo-distributed applications, software engineers need to select the right components (building blocks if you will) from the very beginning:
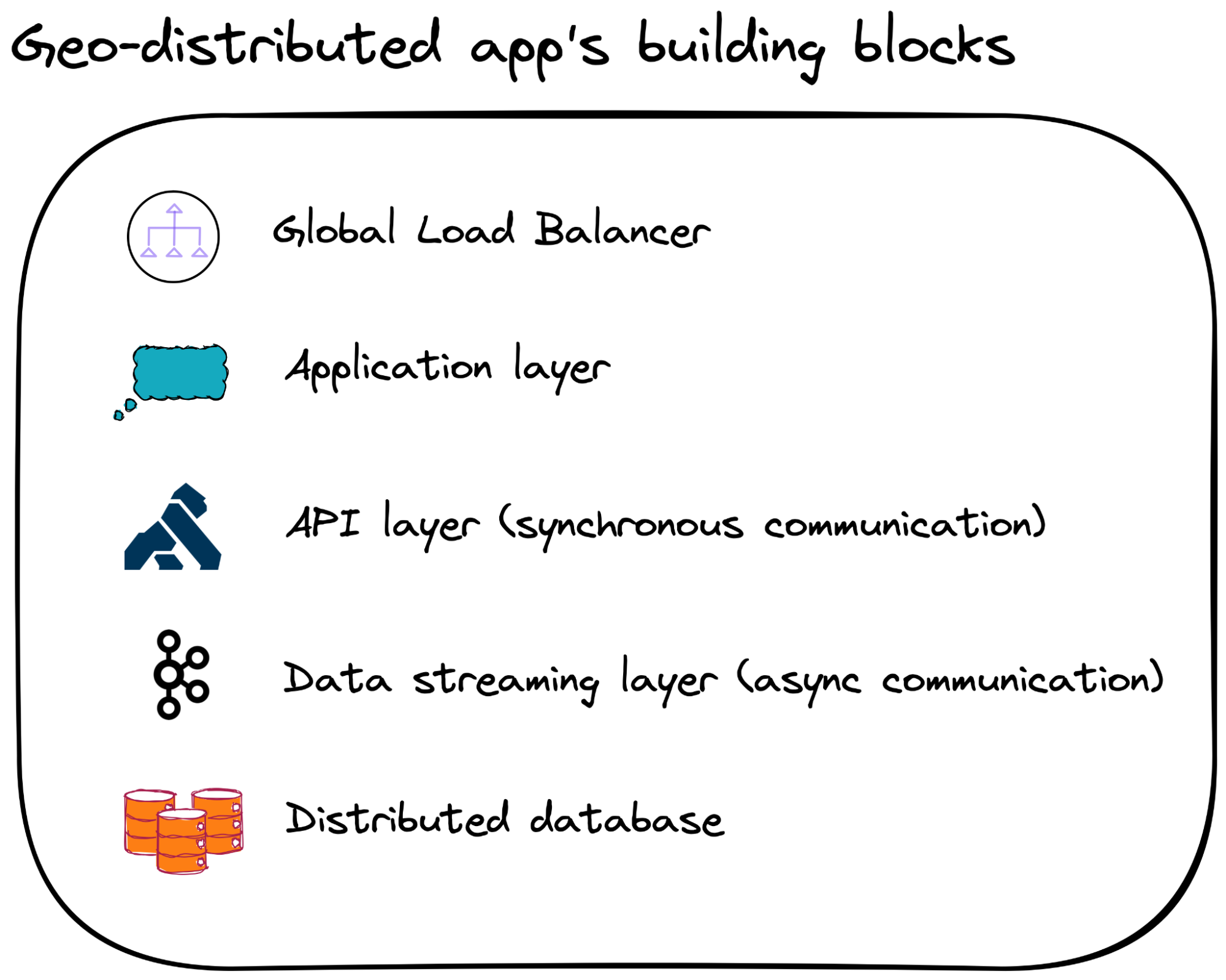
At first glance, the building blocks of a geo-distributed app are not much different from a regular application that functions within a single availability zone. But, there is one distinguishing characteristic. All of the components of a geo-distributed app have to be distributed. This means that they span distant location and can scale horizontally.
Let’s look at a Slack-like messenger app as an example. This step-by-step guide demonstrates how to implement this geo-distributed solution, considering all components.
We’ll start with a distributed application and API layers, continue with a distributed SQL database, and finish with a global cloud load balancer.
Step 1: Deploy Application Instances Across Zones and Regions
The instances of our Slack-like messenger application need to span multiple availability zones and regions. They’re stateless, serving user traffic, keeping user session information, and making sure access is authorized.
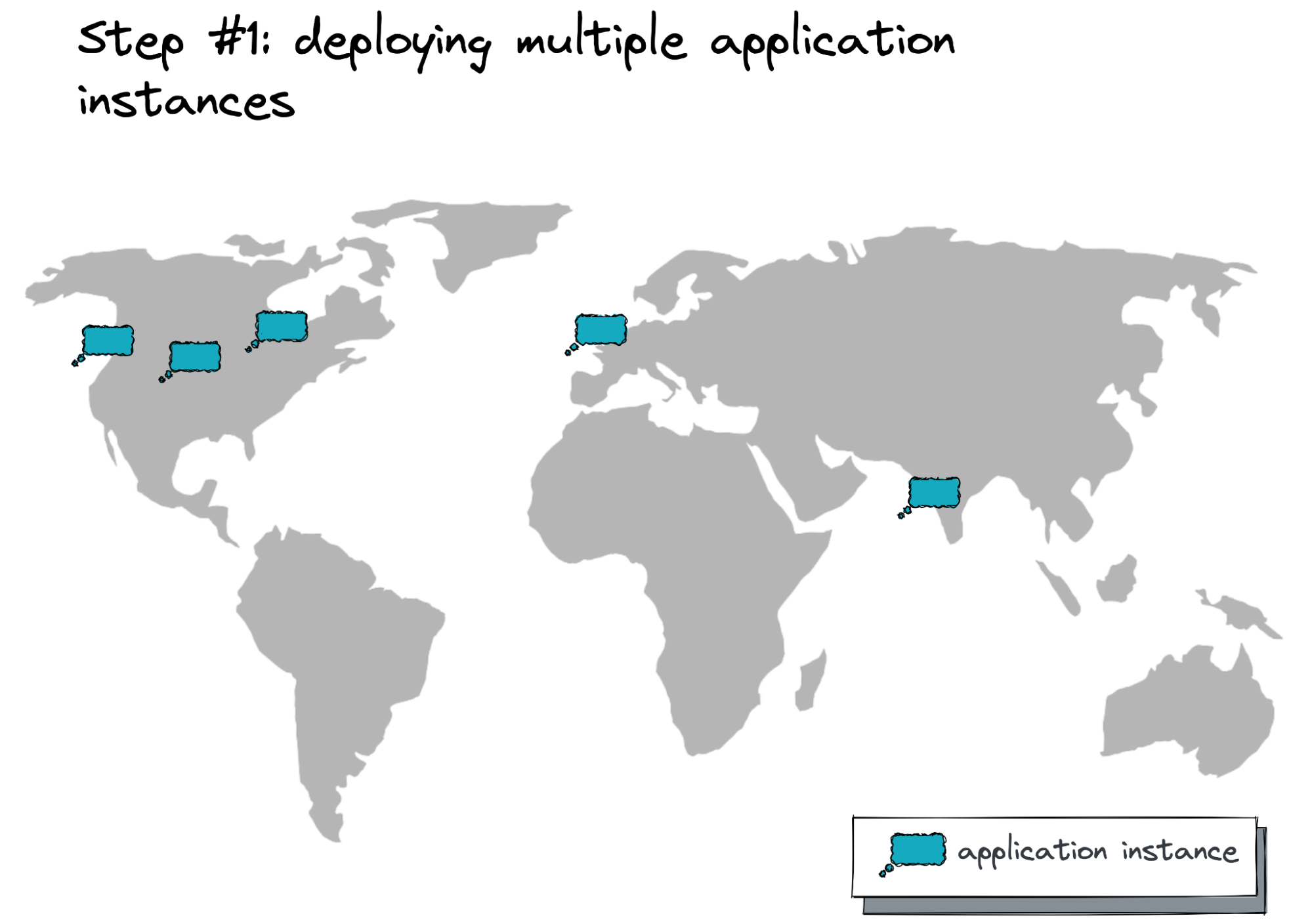
This step is the most straightforward one. We need to select the cloud regions closest to (most of) our customers and run the app instances there. Refer to these recent blogs for detailed instructions on how to create and automate the deployment of Java application instances across cloud regions.
- How to Build a Multi-Zone Java App in Days With Vaadin, YugabyteDB, and Heroku
- Automating Java Application Deployment Across Multiple Cloud Regions
Step 2: Configure Distributed API Layer
Generally, applications are no longer architected and developed as a monolith. Our Slack-like messenger is no exception. It comprises multiple microservices, each of which fulfills a particular function.
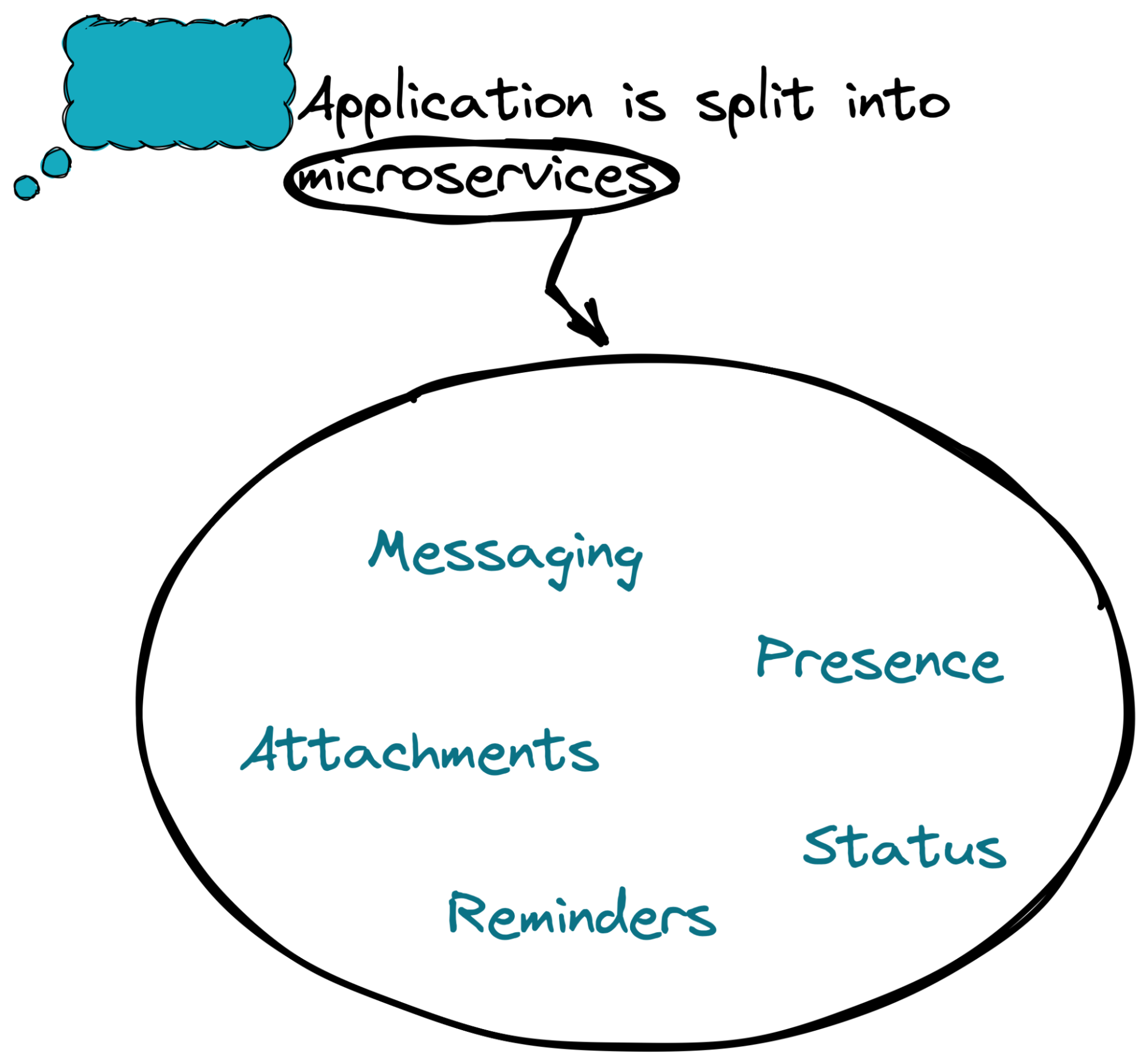
For example, the Messaging microservice implements the key functionality that every messenger app must possess—the ability to send messages across channels and workspaces.
The Attachments microservice uploads pictures and other files.
Finally, the Reminders microservice comes in handy when a user wants to ignore a message for now but return to it later.
All these microservices need to be able to communicate with each other via an API layer. This API layer also needs to span multiple zones and regions.
I built our sample Slack-like messenger’s API layer on Kong Gateway‚ an open-source, flexible, and secure API layer that can work in the cloud environment of choice.
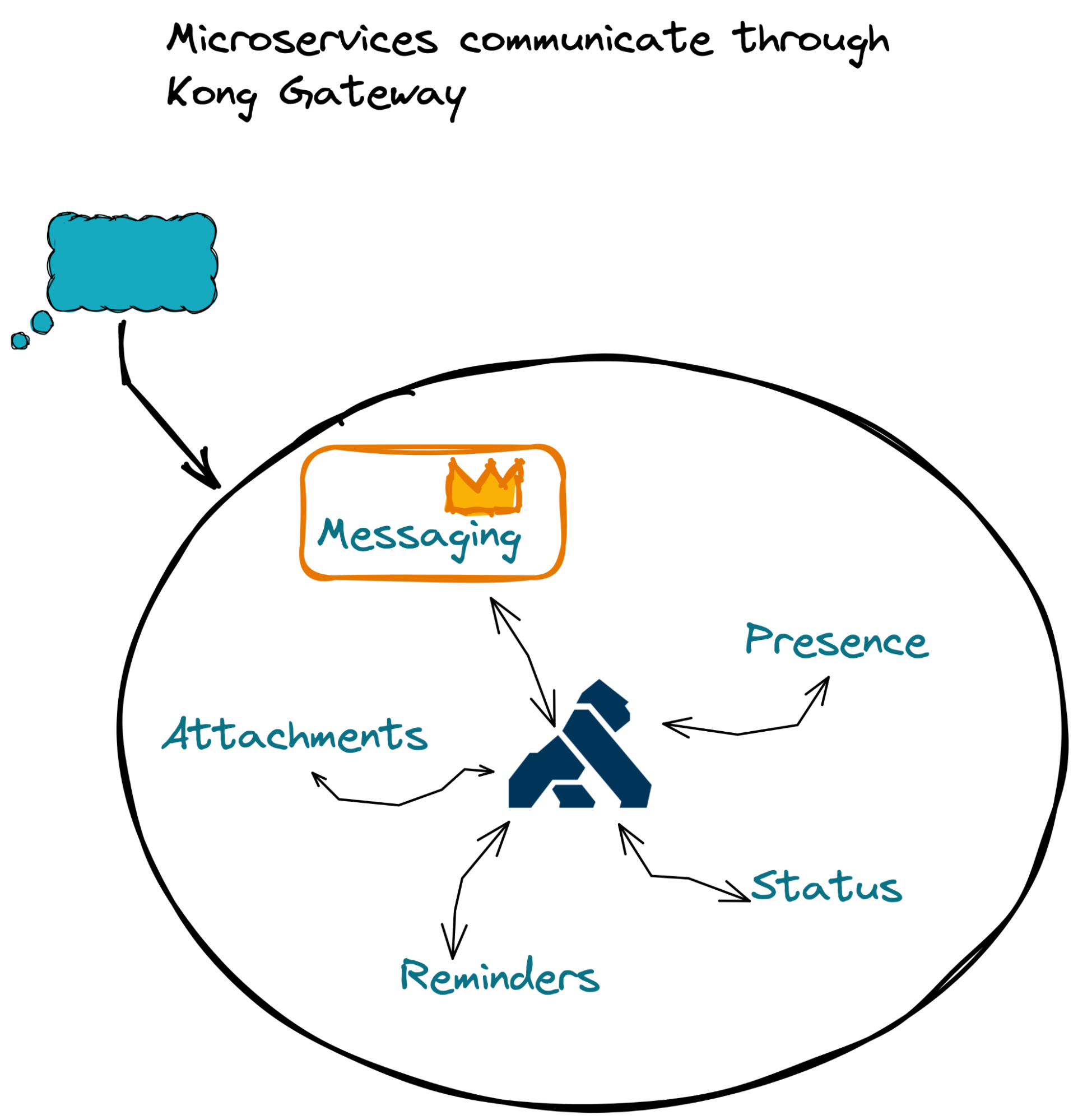
Review one of my previously written blogs that provides instructions on how to enable Kong Gateway for a geo-distributed application.
Step 3: Deploy Distributed Database
There is no silver bullet for a distributed database spanning multiple availability zones and regions. Each approach comes with its own set of advantages and disadvantages.
Our Slack-like messenger example uses YugabyteDB, an open-source distributed SQL database designed for geographically distributed applications.
When it comes to multi-availability zone and multi-region deployments, YugabyteDB supports several options.
We can deploy a single cluster that stretches across multiple regions in close proximity (i.e the US West and East zones) and attach read replica nodes to distant locations (i.e. Europe and Asia). Alternatively, we can configure multiple standalone YugabyteDB clusters in every distant location—one cluster in the US, another in Europe, and the last in Asia—and then enable asynchronous replication between them if necessary.
YugabyteDB supports a geo-distributed mode of deployment so that data is automatically pinned to and served from various geographies with low latency.
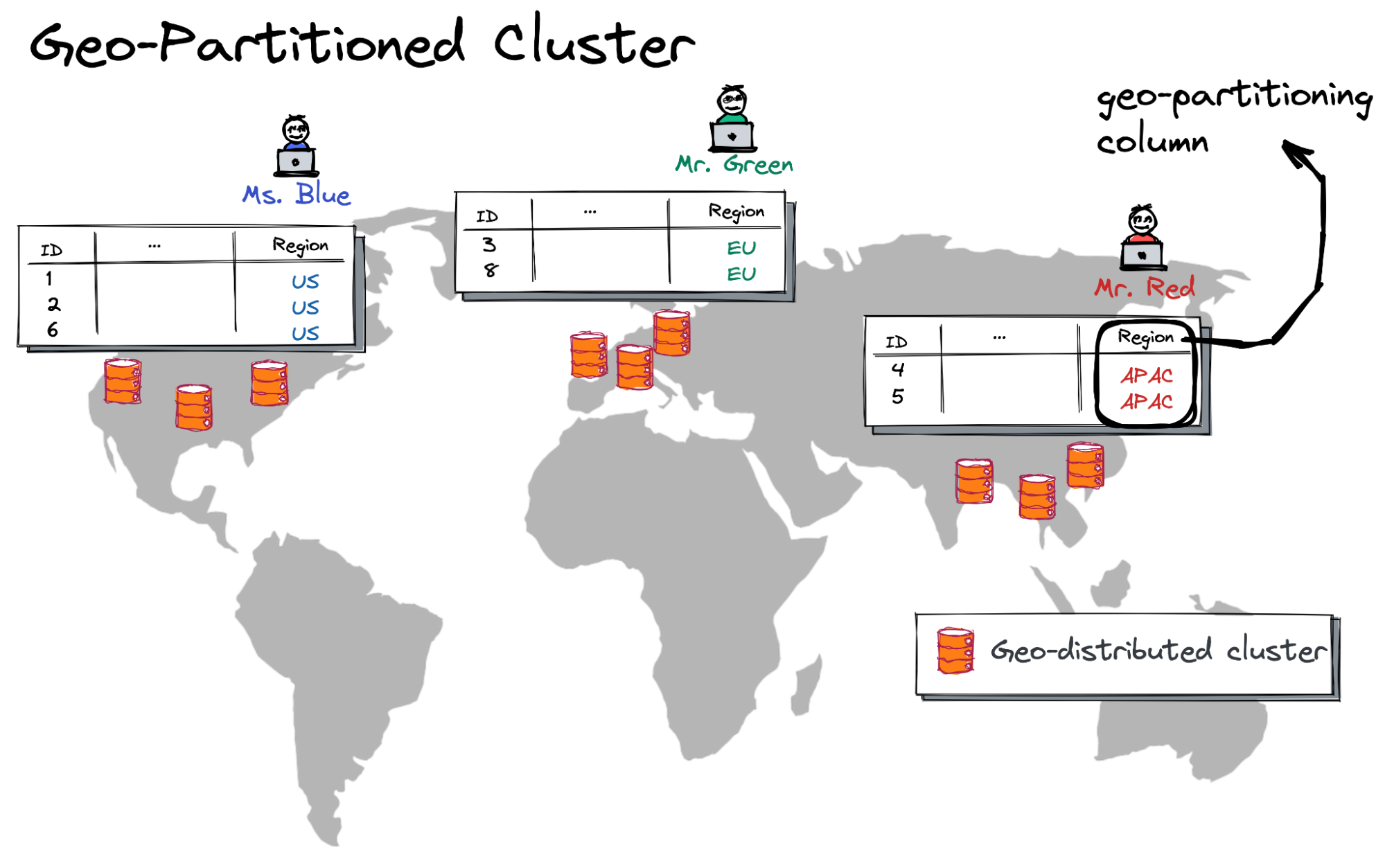
A custom geo-partitioning column (the “Region” column in the picture above) lets the database decide a target row location. For instance, if the Region column is set to EU, then a row will be placed in a group of nodes from the European Union. This also ensures compliance with local data residency requirements.
Refer to the following blogs for more detail and step-by-step instructions for multi-region YugabyteDB deployments.
- Exploring Multi-Region Database Deployment Options
- Geo-Distributed Microservices and Their Database: Fighting the High Latency
Step 4: Enable Global Cloud Load Balancer
After deploying multiple application instances in different cloud locations, we need to enable a global cloud load balancer.
Without a load balancer, we would need to decide which application instance has to serve a particular user request. This is way too complicated and can quickly become unmanageable.
Every cloud environment comes with a global cloud load balancer that can intercept a user request at the nearest PoP (point-of-presence) and then forward the request to an application instance closest to the user.
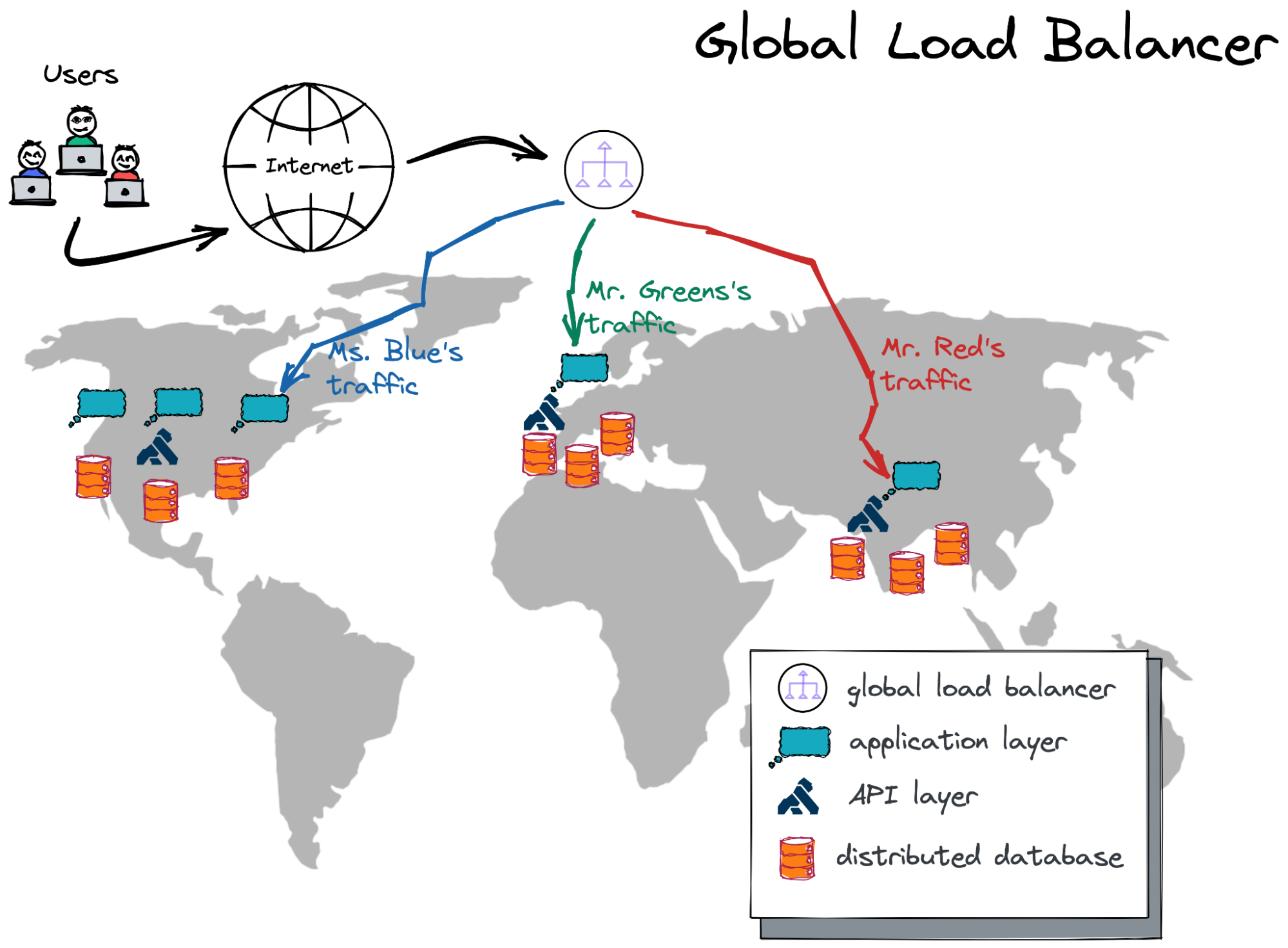
Check out a blog I recently wrote that has detailed instructions on enabling the global load balancer for a geo-distributed application.
Step 5: Run and Test
So now you have a geo-distributed application functioning in the cloud regions of your choice. The application:
- Tolerates cloud outages
- Processes user requests at high speed via application instances and database nodes closest to the user
- Complies with data residency requirements by storing data in the required geographic locations
The source code for the sample Slack-like messenger is in our Github YugabyteDB Samples space, designed specifically to hold YugabyteDB code samples, examples and applications for doers, builders, and disruptors.
Try it out by running the messenger on your local machine or in a geo-distributed mode in Google Cloud.
Final Words of Advice
Most of us don’t need to run an application across multiple cloud regions or continents on day one. But, that doesn’t mean that the principles of geo-distributed application design are not applicable.
Geo-distributed applications run within a single cloud region, but across multiple availability zones. So, as you start building geo-distributed apps you need to ensure your application and API layers with database nodes can run in various availability zones. Your application will be more robust, reliable, and performant.

Then, when the day comes to scale to other geographies, you just have an operational task on your to-do list—not a series of architectural changes. Start small the right way, and it will allow you to grow big faster!
Get Started
Do you have an app ready for breakout growth? Register today for a $10,000 credit and get started using the best distributed SQL database in the cloud for your geo-distributed, cloud native application. Or sign up for a YugabyteDB Managed account and create a free cluster—perfect for learning, testing and non-production use cases.


