Develop IoT Apps with Confluent Kafka, KSQL, Spring Boot & Distributed SQL
May 23, 2019
In our previous post “5 Reasons Why Apache Kafka Needs a Distributed SQL Database”, we highlighted why Kafka-based data services need a distributed SQL database like YugabyteDB as their highly scalable, long-term persistent data store. In this post, we show how Confluent Kafka, KSQL, Spring Boot and YugabyteDB can be integrated to develop an application for managing Internet-of-Things (IoT) sensor data.
The Scenario – IoT-Enabled Fleet Management
A trucking company wants to track its fleet of IoT-enabled vehicles that are delivering shipments across the country. The vehicles are of different types (such as 18 Wheelers, buses, large trucks) and follow 3 delivery routes (Route-37, Route-82, Route-43). In particular, the company wants to track:
- Overall distribution of the vehicle types per delivery route.
- Most recent (say, in the past 30 seconds) subset of these vehicle types per shipment delivery route.
- List of vehicles near road closures, so that they can predict delays in deliveries.
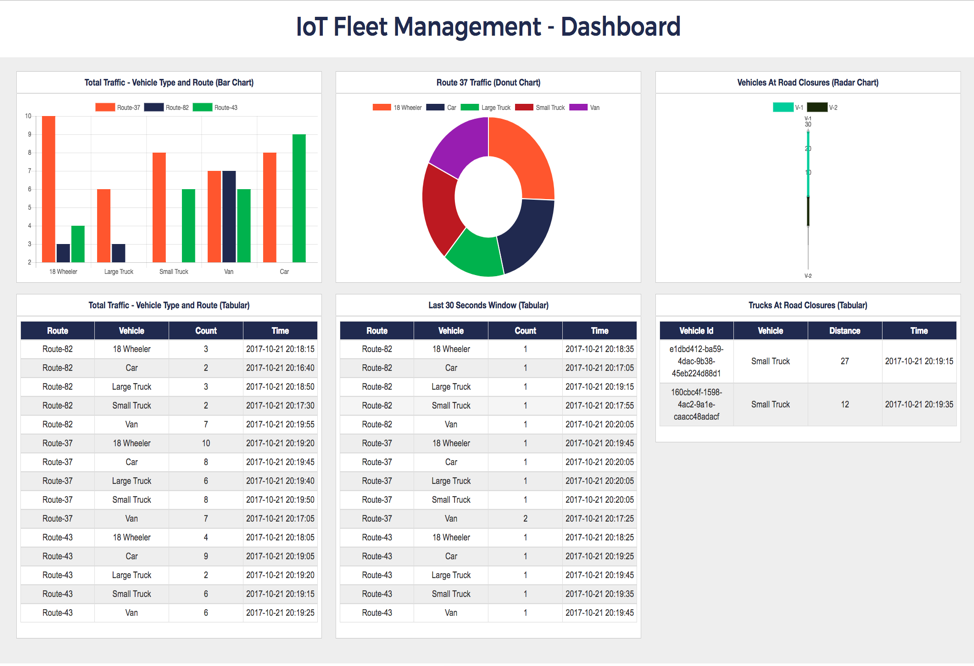
Below is a snapshot of the real-time, auto-refreshing dashboard that this app will render to the end user to visualize the above three tracking aspects.
Application Architecture
In addition to Confluent Kafka as the streaming platform, the application has the following components:
- Data Store: YugabyteDB for storing raw events from a Kafka stream as well as the aggregates from the KSQL Data Processor.
- Data Producer: Program to simulate vehicle events being written into the Kafka stream.
- Data Processor: KSQL reading from Data Producer, computing the aggregates and storing results in the Data Store.
- Data Dashboard: Spring Boot app using web sockets, jQuery and Bootstrap to display output of Data Processor.
Below is the architectural diagram showing how these components fit together. We refer to this as the Confluent Kafka, KSQL and YugabyteDB stack or CKY stack.

We will now look at each of these components in detail.
Data Store
This layer stores all the user data. YugabyteDB is used as the database and Yugabyte Cloud Query Language (YCQL) is used as the database API. All the data is stored in the keyspace TrafficKeySpace. There is a Origin_Table table for storing the raw events.
CREATE TABLE TrafficKeySpace.Origin_Table ( vehicleId text, routeId text, vehicleType text, longitude text, latitude text, timeStamp timestamp, speed double, fuelLevel double, PRIMARY KEY ((vehicleId), timeStamp) ) WITH default_time_to_live = 3600;
Note the default_time_to_live value set to 3600 seconds to ensure that raw events get auto-deleted after 1 hour. This is to ensure that the raw events do not consume up all the storage in the database and are efficiently deleted from the database a short while after their aggregates have been computed.
There are three tables that hold the data to be used for the user-facing display:
Total_Trafficfor the lifetime traffic informationWindow_Trafficfor the last 30 seconds of traffic andpoi_trafficfor the traffic near a point of interest (road closures).
The data processor constantly updates these tables, and the dashboard reads from them.
Below are the schemas for these tables.
CREATE TABLE TrafficKeySpace.Total_Traffic ( routeId text, vehicleType text, totalCount bigint, timeStamp timestamp, recordDate text, PRIMARY KEY (routeId, recordDate, vehicleType) ); CREATE TABLE TrafficKeySpace.Window_Traffic ( routeId text, vehicleType text, totalCount bigint, timeStamp timestamp, recordDate text, PRIMARY KEY (routeId, recordDate, vehicleType) ); CREATE TABLE TrafficKeySpace.Poi_Traffic( vehicleid text, vehicletype text, distance bigint, timeStamp timestamp, PRIMARY KEY (vehicleid) );
Data Producer
This contains the program that generates simulated test data and publishes it to the Kafka topic iot-data-event. This emulates the data received from the connected vehicles using a message broker in the real world.
A single data point is a JSON payload and looks as follows:
{
"vehicleId":"0bf45cac-d1b8-4364-a906-980e1c2bdbcb",
"vehicleType":"Taxi",
"routeId":"Route-37",
"longitude":"-95.255615",
"latitude":"33.49808",
"timestamp":"2017-10-16 12:31:03",
"speed":49.0,
"fuelLevel":38.0
}The Kafka Connect YugabyteDB Sink Connector reads the above iot-data-event topic, transforms each such event into a YCQL INSERT statement and then calls YugabyteDB to persist the event in the TrafficKeySpace.Origin_Table table.
Data Processor
KSQL is the streaming SQL engine for Apache Kafka. It provides an easy-to-use yet powerful interactive SQL interface for stream processing on Kafka, without the need to write code in programming languages such as Java or Python. It supports a wide range of streaming operations, including data filtering, transformations, aggregations, joins, windowing, and sessionization.
The first step in using KSQL is to create a STREAM from the raw events of iot-data-event as shown below.
CREATE STREAM traffic_stream (
vehicleId varchar,
vehicleType varchar,
routeId varchar,
timeStamp varchar,
latitude varchar,
longitude varchar)
WITH (
KAFKA_TOPIC='iot-data-event',
VALUE_FORMAT='json',
TIMESTAMP='timeStamp',
TIMESTAMP_FORMAT='yyyy-MM-dd HH:mm:ss');
Various aggregations/queries can now be run on the above stream with results of each type of query stored in a new Kafka topic of its own. This application uses 3 such queries/topics. Thereafter, the Kafka Connect YugabyteDB Sink Connector reads these 3 topics and persists the results into the 3 corresponding tables in YugabyteDB.
CREATE TABLE total_traffic
WITH ( PARTITIONS=1,
KAFKA_TOPIC='total_traffic',
TIMESTAMP='timeStamp',
TIMESTAMP_FORMAT='yyyy-MM-dd HH:mm:ss') AS
SELECT routeId,
vehicleType,
count(vehicleId) AS totalCount,
max(rowtime) AS timeStamp,
TIMESTAMPTOSTRING(max(rowtime), 'yyyy-MM-dd') AS recordDate
FROM traffic_stream
GROUP BY routeId, vehicleType;
CREATE TABLE window_traffic
WITH ( TIMESTAMP='timeStamp',
KAFKA_TOPIC='window_traffic',
TIMESTAMP_FORMAT='yyyy-MM-dd HH:mm:ss',
PARTITIONS=1) AS
SELECT routeId,
vehicleType,
count(vehicleId) AS totalCount,
max(rowtime) AS timeStamp,
TIMESTAMPTOSTRING(max(rowtime), 'yyyy-MM-dd') AS recordDate
FROM traffic_stream
WINDOW HOPPING (SIZE 30 SECONDS, ADVANCE BY 10 SECONDS)
GROUP BY routeId, vehicleType;
CREATE STREAM poi_traffic
WITH ( PARTITIONS=1,
KAFKA_TOPIC='poi_traffic',
TIMESTAMP='timeStamp',
TIMESTAMP_FORMAT='yyyy-MM-dd HH:mm:ss') AS
SELECT vehicleId,
vehicleType,
cast(GEO_DISTANCE(cast(latitude AS double),cast(longitude AS double),33.877495,-95.50238,'KM') AS bigint) AS distance,
timeStamp
FROM traffic_stream
WHERE GEO_DISTANCE(cast(latitude AS double),cast(longitude AS double),33.877495,-95.50238,'KM') < 30;
The Kafka Connect YugabyteDB Sink Connector is used for storing both the raw events as well as the aggregate data (that’s generated using KSQL). It computes the following:
- A breakdown by vehicle type and the shipment route across all the vehicles and shipments done so far.
- Compute the above breakdown only for active shipments. This is done by computing the breakdown by vehicle type and shipment route for the last 30 seconds.
- Detect the vehicles which are within a 20 mile radius of a given Point of Interest (POI), which represents a road-closure.
Data Dashboard
This is a Spring Boot application which queries the data from YugabyteDB and pushes the data to the webpage using Web Sockets and jQuery. The data is pushed to the web page in fixed intervals so data will be refreshed automatically. The main UI page uses bootstrap.js to display the dashboard containing charts and tables.
We create entity classes for the three tables Total_Traffic, Window_Traffic and poi_traffic, and Data Access Object (DAO) interfaces for all the entities extending CassandraRepository. For example, we create the DAO class for TotalTrafficData entity as follows.
@Repository
public interface TotalTrafficDataRepository extends CassandraRepository<TotalTrafficData>{
@Query("SELECT * FROM traffickeyspace.total_traffic WHERE recorddate = ?0 ALLOW FILTERING")
Iterable<TotalTrafficData> findTrafficDataByDate(String date);In order to connect to YugabyteDB cluster and get connection for database operations, we also write a DatabaseConfig class.
Note that currently the Dashboard does not access the raw events table and relies only on the data stored in the aggregates tables.
Summary
This application is a blueprint for building IoT applications using Confluent Kafka, KSQL, Spring Boot and YugabyteDB. While this post focused on a local cluster deployment, the Kafka brokers and YugabyteDB nodes can be horizontally scaled in a real cluster deployment to get more application throughput and fault tolerance. The instructions to build and run the application, as well as the source code can be found in the yb-iot-fleet-management GitHub repo.
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.

")
