Distributed SQL Tips and Tricks for PostgreSQL and Oracle DBAs – July 24, 2020
July 24, 2020
Welcome to this week’s tips and tricks blog where we explore both beginner and advanced YugabyteDB topics for PostgreSQL and Oracle DBAs. First things first, for those of you who might be new to either distributed SQL or YugabyteDB.
What is Distributed SQL?
Distributed SQL databases are becoming popular with organizations interested in moving data infrastructure to the cloud or cloud native environments. This is often motivated by the desire to reduce TCO or move away from the horizontal scaling limitations of monolithic RDBMS like Oracle, PostgreSQL, MySQL, and SQL Server. The basic characteristics of Distributed SQL are:
- They must have a SQL API for querying and modeling data, with support for traditional RDBMS features like foreign keys, partial indexes, stored procedures, and triggers.
- Smart distributed query execution so that query processing is pushed closer to the data as opposed to data being pushed over the network and thus slowing down query response times.
- Should support automatic and transparent distributed data storage. This includes indexes which should be sharded across multiple nodes of the cluster so that no single node becomes a bottleneck. Data distribution ensures high performance and high availability.
- Distributed SQL systems should also provide for strongly consistent replication and distributed ACID transactions.
For a deeper discussion about what Distributed SQL is, check out, “What is Distributed SQL?”
What’s YugabyteDB?
YugabyteDB is an open source, high-performance distributed SQL database built on a scalable and fault-tolerant design inspired by Google Spanner. YugabyteDB is PostgreSQL wire compatible, cloud native, offers deep integration with GraphQL projects, plus supports advanced RDBMS features like stored procedures, triggers, and UDFs.
Got questions? Make sure to ask them in our YugabyteDB Slack channel. Ok, let’s dive in…
What are the equivalents to Oracle’s IDENTITY and PostgreSQL’s SERIAL columns in YugabyteDB?
The release of Oracle 12c introduced a direct equivalent to the auto numbering and identity functionality that was already supported in other databases for many years.
Oracle supports two alternatives in this regard including the ability to create IDENTITY columns and support for sequence pseudocolumns as default values. In a nutshell, we can think of Oracle’s IDENTITY columns as functionally equivalent to MySQL’s AUTO_INCREMENT, SQL Server’s IDENTITY, and PostgreSQL’s SERIAL pseudo-type.
Let’s take a look at a simple example in Oracle.
CREATE TABLE motorcycle_manufacturers
(
manufacturer_id NUMBER GENERATED BY DEFAULT AS IDENTITY
START WITH 5 PRIMARY KEY,
manufacturer_name VARCHAR2(50) NOT NULL
);
In the example above we are creating a table in which the first motorcycle manufacturer inserted will be assigned a manufacturer_id of “5” while the next one will be assigned “6” and so on. The START WITH clause in the primary key specification is what tells the database what number to start with.
In YugabyteDB the above example can be accomplished in two ways just as it would be in PostgreSQL. The first possible solution is to use GENERATED BY DEFAULT AS IDENTITY or GENERATED ALWAYS AS IDENTITY in the PRIMARY KEY specification. As shown in the example below.
CREATE TABLE motorcycle_manufacturers ( manufacturer_id INT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY, manufacturer_name VARCHAR(50) NOT NULL );
A second example is to use the SERIAL pseudo-type.
CREATE TABLE motorcycle_manufacturers ( manufacturer_id SERIAL PRIMARY KEY, manufacturer_name VARCHAR(50) NOT NULL );
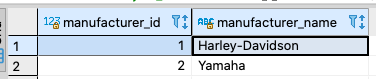
Using the SERIAL example, let’s insert two records which by default will auto increment by 1.
INSERT INTO motorcycle_manufacturers (manufacturer_id, manufacturer_name) VALUES (default, 'Harley-Davidson'), (default, 'Yamaha'); SELECT * FROM motorcycle_manufacturers;
Next, let’s create a sequence that we can reference so the next motorcycle manufacturers that get inserted will be incremented by 1 off an initial value of 50.
CREATE SEQUENCE mcm_sequence
start 50;
INSERT INTO motorcycle_manufacturers
(manufacturer_id, manufacturer_name)
VALUES
(nextval('mcm_sequence'), 'Royal Enfield'),
(nextval('mcm_sequence'), 'Triumph');
SELECT * FROM motorcycle_manufacturers;

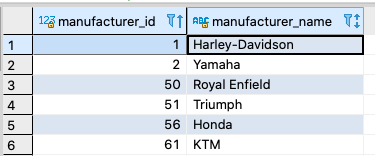
Finally, let’s alter the sequence so that the next motorcycle manufacturers that get inserted will be incremented by 5 from the last manufacturer_id value of 51.
ALTER SEQUENCE mcm_sequence
increment 5;
INSERT INTO motorcycle_manufacturers
(manufacturer_id, manufacturer_name)
VALUES
(nextval('mcm_sequence'), 'Honda'),
(nextval('mcm_sequence'), 'KTM');
SELECT * FROM motorcycle_manufacturers;
What are the equivalents to Oracle’s NUMBER and PostgreSQL’s DECIMAL and NUMERIC data types in YugabyteDB?
All databases have to deal with large numbers with varying degrees of precision and scale. For review:
- Precision: Is the total number of digits in a decimal number, both before and after the decimal point.
- Scale: Is the total number of digits after the decimal point in a number.
In Oracle, the NUMBER datatype stores fixed and floating-point numbers. Oracle supports up to 38 digits of precision and scale that can range between -84 to 127. In YugabyteDB, the functional equivalent to Oracle’s NUMERIC datatype is going to be exactly the same as PostgreSQL’s DECIMAL and NUMERIC datatypes. Both of these datatypes support up to 131,072 digits before the decimal point; up to 16,383 digits after the decimal point.
How does YugabyteDB handle Oracle’s TIMESTAMP WITH TIME ZONE datatype?
In Oracle, the TIMESTAMP WITH TIME ZONE datatype is a variant of TIMESTAMP that includes a time zone offset or time zone region name in its value. The time zone offset is the difference (in hours and minutes) between local time and UTC.
TIMESTAMP [(fractional_seconds_precision)] WITH TIME ZONE
In Oracle, the examples below are acceptable values for this datatype::
TIMESTAMP '2020-07-12 08:30:00.00 -07:00' TIMESTAMP '2020-07-12 8:30:00 US/Pacific' TIMESTAMP '2020-07-12 08:30:00 US/Pacific PDT'
In YugabyteDB, as in PostgreSQL, these values are stored in the database as UTC and converted to the current session’s time zone when selected. If retaining the original time zone information is necessary, it needs to be stored separately.
To find your current time and time zone execute the following:
SELECT now( );
Result:
2020-07-12 20:04:01.991809-07
In YugabyteDB, to figure out what the -07 UTC offset denotes, use the following:
SELECT * FROM pg_timezone_names WHERE utc_offset = '-07:00' AND is_dst;
Results:
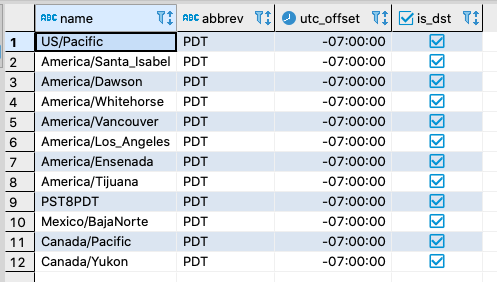
The result set tells us we are in the PDT time zone. To keep things simple, let’s change our session’s time zone to UTC.
SET TIME ZONE 'UTC'; SELECT now( );
Result:
2020-07-13 03:30:49.376552+00
Notice that the +00 offset tells us that our time zone has been set to UTC.
In YugabyteDB there are two data types, timestamp and timestampz, that store date and time in a single field.
- timestamp does not convert the value to UTC
- timestamptz converts the value to UTC
As an example, run the following query:
SELECT '2020-07-12 20:04:01.991809-07:00'::timestamp as "Timestamp without time zone", '2020-07-12 20:04:01.991809-07:00'::timestamptz as "Timestamp with time zone";
Results:
Timestamp without time zone
2020-07-12 20:04:01.991809
Timestamp with time zone
2020-07-13 03:04:01.991809+00
Note that the timestamp data type ignores the -7:00 offset from the original value while the timestamptz data type takes into account the offset.
What is the difference between YugabyteDB’s open source license and PostgreSQL’s?
Both YugabyteDB and PostgreSQL are open source databases with permissive licenses. PostgreSQL is released under the PostgreSQL License, which is similar to the BSD or MIT licenses. YugabyteDB is released under the Apache 2.0 License. A blog worth pursuing if you’d like to understand the subtleties between these open source licenses is “Apache license 2.0, MIT license or BSD license : Who is the fairest of them all?” by Anner Mazur. If you’d like to learn more about what motivated Yugabyte to double down on open source, check out:
- “Why We Changed YugabyteDB Licensing to 100% Open Source”
- “100% Committed to Open Source, YugabyteDB Community Update – June 11, 2020”
New Documentation, Blogs, Tutorials, and Videos
New Blogs
- Porting Oracle to YugabyteDB
- Getting Started with Longhorn Distributed Block Storage and Cloud Native Distributed SQL
- Announcing YugabyteDB 2.2 – Distributed SQL Made Easy
- Polymorphism in SQL part one – anyelement and anyarray
- Polymorphism in SQL part two – variadic functions
New Videos
- What’s New in YugabyteDB 2.2
- Distributed SQL Meets PostgreSQL
- Getting Started with Hasura GraphQL & YugabyteDB on GKE
- Getting Started with YugabyteDB on GKE with Helm 3
New and Updated Docs
ICYMI, to support the release of YugabyteDB 2.2, we published these new docs:
- Transactional distributed backups – YSQL
- Transactional distributed backups – YCQL
- Online index builds: Simple and unique indexes for YCQL
- Online index builds: Simple indexes for YSQL
- Deferred constraints: YSQL now supports DEFERRABLE INITIALLY IMMEDIATE and DEFERRABLE INITIALLY DEFERRED clauses on foreign keys
- Colocated tables: Database-level colocation for YSQL
- Benchmark YugabyteDB using TPC-C
Upcoming Events
- July 29 @ 10am PT [1pm ET] – Webinar: Introduction to SQL; if you need a relational database, but you never learned SQL, then this webinar is for you.
- Aug 7 @ 11:30 PT [2:30pm ET] – YugabyteDB Community Q&A, Topic: Cloud Native
- Aug 12 @ 10am PT [1pm ET] – Webinar: Geo-distributed SQL databases: 9 techniques to reduce cross-region latency
- Aug 17 – 20 – KubeCon + CloudNativeCon Europe 2020 Virtual
Get Started
Ready to start exploring YugabyteDB features? Getting up and running locally on your laptop is fast. Visit our quickstart page to get started.

 When Node Is Lost and Then Brought Back Into Cluster?")
