Why We Changed YugabyteDB Licensing to 100% Open Source
July 16, 2019
We are excited to announce that YugabyteDB is now 100% open source under the Apache 2.0 license. This means previously closed-source, commercial, enterprise features such as Distributed Backups, Data Encryption, and Read Replicas are now available in the open source project and are completely free to use. The same applies to upcoming new features like Change Data Capture and 2 Data Center Deployments. The result of this change is that we no longer have a Community Edition and an Enterprise Edition of YugabyteDB. There is only one edition of YugabyteDB now and that is fully open source. Additionally, we are announcing the release of our previously closed-source management software under a source available, free-trial-only license from the Polyform Project. These changes are effective as of the 1.3 release that became generally available today.
“Developers increasingly turn to PostgreSQL as a logical Oracle alternative as they move away from the monolithic database for microservices-based applications running on multiple clouds. However, PostgreSQL was not built for dynamic cloud platforms and open source alternatives are restricted. YugabyteDB fills this gap by supporting PostgreSQL’s feature depth for modern cloud infrastructure. And by making the database 100% open source, YugabyteDB removes other roadblocks to adoption and has made itself very attractive to developers building business-critical applications and operations engineers running them on cloud-native platforms.”
— Matt Asay, columnist and Head of Developer Ecosystem at Adobe
Industry observers and open source experts will note that our change goes against the recent trend of database and data infrastructure companies abandoning open source licenses for some or all of their core project. The following image summarizes how our change compares against the changes made by MongoDB, Cockroach Labs, Confluent (the primary commercial company behind Apache Kafka), and Elastic in 2018-2019.
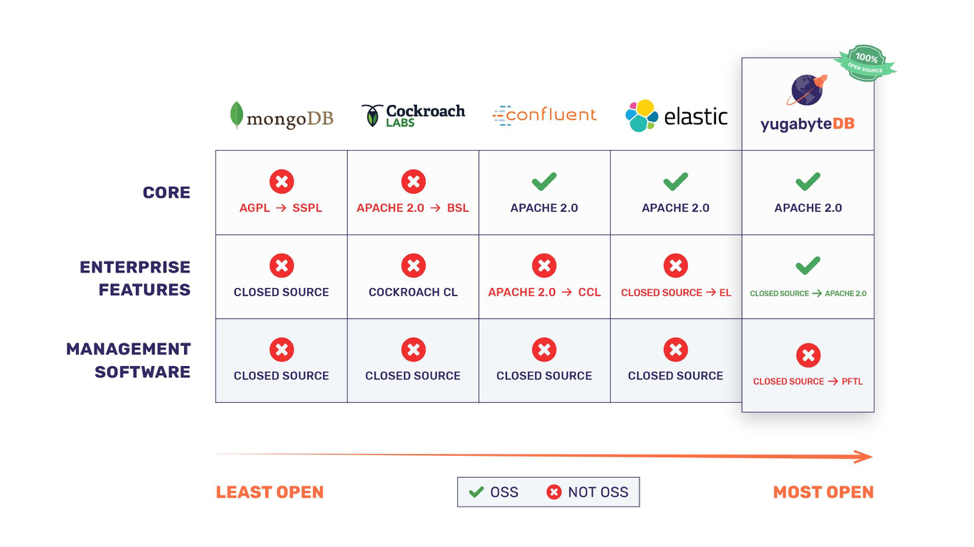
This post details our reasoning behind the change in the context of our goals for the YugabyteDB open source project and also Yugabyte as a commercial OSS company.
Why Open Source At All?
Over the years, open source has proven to be the most successful approach to develop and distribute business-critical infrastructure software. On day 1, it removes a user’s barrier to entry because the software comes with absolute freedom, thus making exponential adoption growth a real possibility. This adoption then powers the rapid feedback loop necessary for high-velocity, collaborative, community-driven development of feature-rich software while maintaining high quality and reliability. Security hardening, ecosystem integrations, extensibility frameworks, and other enterprise features naturally get stronger as a result of this approach.
Can proprietary infrastructure software with a freemium tier achieve the same? Yes it can, but it would take a significantly longer period of time for the software to mature to the same level. Also, the loss of collaborative development and slower feedback loop means that there is a higher probability of the software never achieving market traction and thus fading away into oblivion.
Recent Open Source Licensing Changes
As we previously outlined in “Building a High Growth Business by Monetizing Open Source Software”, open source software and for-profit motive are not at odds with each other. A healthy commercial business is a must-have for continued investment in open source, especially in the context of single-vendor OSS projects. The net result is still more OSS than otherwise possible! To the purists who say OSS projects should never be led by a single vendor, we ask if they can imagine a world without MongoDB, Elastic, Confluent, Databricks, InfluxData, HashiCorp, and many more commercial OSS companies.
There are three non-mutually-exclusive models of monetizing open source infrastructure software.
- Services, Support, and Training
- Open Core
- Managed Service
While #1 and #3 are clearly understood, the open core monetization model is where much of the recent licensing debate has focused on. For database and data infrastructure companies, open core has traditionally meant reserving a certain class of “enterprise” features for a separate commercial edition. This class of features usually includes add-on capabilities such as the ability to build new data models, backup the data stored, secure data in-flight and at rest through encryption, multi-datacenter replication, and more. Management software that sits outside the core and offers automated cluster creation, scaling, upgrades, backups, and monitoring is also usually included in this class. A managed cloud service can be thought of as hosted management software with built-in cloud infrastructure orchestration. With this background information in hand, we are ready to analyze the recent licensing changes of the four companies we described earlier. We will see that each case is unique in its own right even though they all look the same to the casual observer.
MongoDB: AGPL to SSPL for Core DB
In October 2018, MongoDB changed the license of its core database from AGPL to SSPL. Since SSPL is not a OSI-approved license, this change essentially meant that MongoDB is now proprietary software. While AWS offering a competing DB-as-a-Service was cited as the reason, the reality is that this change was never about AWS. As the January 2019 launch of MongoDB-compatible AWS DocumentDB proved, MongoDB’s original AGPL license had indeed served the purpose of deterring AWS from hosting MongoDB as-is. MongoDB’s innovation has always been in its query language. AWS had to rebuild a server for that query language and run it on an Aurora-like storage architecture. This was a repeat of the approach followed by Azure Cosmos DB for its MongoDB-compatible API launch in 2017. It is unimaginable that the smart people at MongoDB did not understand these dynamics. We believe they still went ahead with SSPL because they wanted to hurt the multiple smaller MongoDB hosting providers that have sprung up over the years and migrate that portion of the managed cloud business over to their own Atlas service. No surprise that mLab, arguably the largest of such providers, agreed to get acquired by MongoDB only a week before the SSPL announcement. But what about the blowback from the open source community? Simple answer is that MongoDB is now big enough that it no longer has to pretend it cares about the spirit and ethics of open source.
Cockroach Labs: Apache 2.0 to BSL for Core DB
In June 2019, Cockroach Labs changed the license of its core database from Apache 2.0 to Business Source License (BSL) that was first created/adopted by MariaDB in 2016. BSL too is not approved by OSI and hence CockroachDB is now proprietary software. Again the reason provided was the threat of AWS offering a competing managed cloud service. However, the reality is that CockroachDB is not yet at the levels of adoption where AWS would be interested. So why did Cockroach Labs make the change? We believe the answer lies in the fact that painting AWS as a threat is good for press coverage and calling out Amazon Aurora, the fastest growing AWS service, as competition is good for market positioning. And what about open source community blowback? The calculation here seems to be that the number of detractors would be small and new users would not necessarily care once the brouhaha dies down.
Confluent: Apache 2.0 to CCL for Enterprise Features
Confluent is the primary commercial company behind Apache Kafka, a massively popular streaming platform. In December 2018, it announced that it is changing the licensing of some of its enterprise features from Apache 2.0 to Confluent Community License (CCL). CCL is a source available license that disallows features to be used by a managed service that competes with Confluent’s commercial offerings. Since Apache Kafka is an Apache 2.0-licensed OSS project managed by the Apache Source Foundation (ASF), it can be hosted by any cloud provider without issues. AWS had already announced its Managed Streaming for Kafka (MSK) service in November 2018 before the Confluent announcement. So Confluent’s stated rationale of disallowing AWS from profiting off Confluent-developed enterprise features indeed makes sense.
Elastic: Closed Source to Elastic License for Enterprise Features
AWS has been offering its Elasticsearch service since Oct 2015. So AWS was not the stated reason for Elastic’s licensing changes in Feb 2018. Elastic released the source code for X-Pack, its previously closed-source commercial software, under a new source available license called Elastic License (EL). Elastic did so to promote the collaborative development and rapid feedback loop that we previously mentioned. Both Apache 2.0 (aka OSS) and Elastic License code reside in the same GitHub repo and build targets are available to build pure OSS code as well as the OSS+EL code. Like all recent source available licenses, Elastic License disallows competition from managed services.
DB Monetization is Dead, Long Live DBaaS Monetization
Keeping aside the recent licensing trends for a minute, can we learn anything from the history of OSS DB monetization? Yes we can. First is to understand the reasons behind the success of Amazon Aurora in monetizing the massive adoption of both PostgreSQL and MySQL. Second would be to do the same for MongoDB Atlas which has successfully monetized the massive adoption of MongoDB. Databricks and AWS EMR monetization of Apache Spark are other examples from the data analytics market. In all cases, efforts to monetize the OSS directly were marginally successful but efforts to monetize the cloud service have been wildly successful. The insight here is users take a long time to build trust with a business-critical DB but once that trust is established, they are willing to pay top $$$ for the convenience of the cloud DB-as-a-Service (DBaaS) especially when their adoption reaches scale.
We at Yugabyte believe that if AWS wants to build a managed service based on an OSS project, there is almost nothing that can be done to stop it — competition from AWS is simply the price to pay for developing OSS. Restrictive licensing including AGPL can slow down AWS but cannot stop it so the real impact of such licensing is lower user adoption. And even if AWS builds a service, that becomes a great validation of the staying power of the OSS project and gives users more confidence that their investment will remain protected through multi-party competition. But this means that a commercial OSS company now has to compete with AWS on the merits of an exceptional DBaaS experience and not on the merits of the core OSS DB. The company to emulate here is Elastic which highlights its differentiation against AWS in excellent detail here.
OSS Projects vs. Commercial Products
Given the above insights, we decided to not only make YugabyteDB 100% OSS but also draw a clear line of separation between the OSS DB project and our commercial DBaaS offerings. Effective immediately, the self-managed DBaaS features of the previous Enterprise Edition are rebranded into our Yugabyte Platform offering. We are also announcing the Early Access Program for Yugabyte Cloud, our fully-managed DBaaS offering on AWS and Google Cloud.

The source code for Yugabyte Platform is now available in the same GitHub repository as YugabyteDB under the Polyform Free Trial License 1.0 (PFTL). Given the free-trial-only usage restriction PFTL imposes on users, it does not meet the definition of Open Source and hence Yugabyte Platform should be treated as proprietary software. The default build target in the GitHub repository generates only the OSS binary to ensure that users who are not interested in the PFTL-based commercial DBaaS features can continue to have a frictionless experience. For users interested in collaborating with the committers on the commercial features, this change allows a more open forum to work together including discussing issues, offering design feedback and even submitting their own fixes upstream. This approach is similar to that of Elastic with the notable exception that YugabyteDB’s enterprise features are OSS while Elastic’s are not.
Default DB for Multi-Cloud
We have never been shy of acknowledging our ambition of becoming the Default DB for Multi-Cloud. However, many before us have tried and failed to do so. What makes us different? The difference lies in the truly world-class strength of our team and the clarity with which we as a team are pursuing our ambition. We see three essential execution vectors to achieving our ambition.
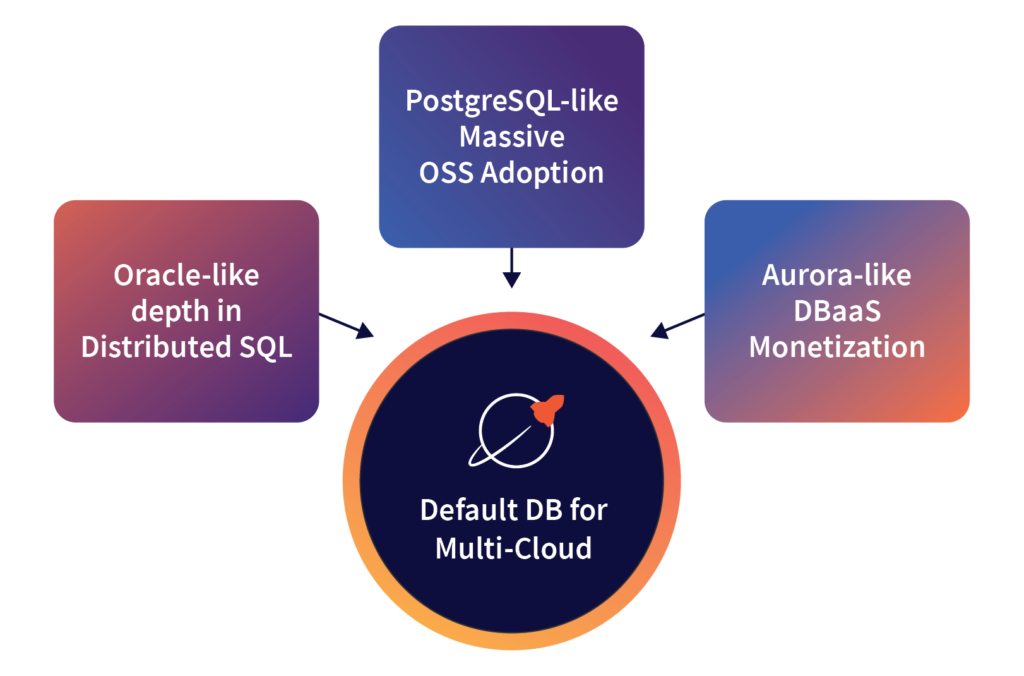
1. Oracle-like Depth in Distributed SQL
With so many ex-Oracle database engineers in the team, it is clear to us that application developers will give Oracle-like importance to a new database only if the client language of the database provides Oracle-like data modeling agility while ensuring high-performance queries. This is where Yugabyte SQL (YSQL) comes in. YSQL reuses PostgreSQL’s query layer as-is but runs on top of DocDB, YugabyteDB’s Google Spanner-inspired distributed document store. This combination gives YSQL two unique strengths that ensure an Oracle-like depth can be experienced by developers.
- Support for a wide-range of existing PostgreSQL constructs such as stored procedures, functions, triggers, extensions and more. This covers the “SQL” depth aspect of Distributed SQL where existing enterprise-grade SQL is designed to work on distributed storage architecture with high performance and reliability.
- Upcoming support for new SQL constructs to define co-partitioned tables, row-level geo-partitioning as well as enhancements to SQL drivers for topology-aware routing to ensure high performance queries. This covers the “Distributed” depth aspect of Distributed SQL where SQL gets enhanced to exploit the underlying distributed storage architecture to the maximum potential.
2. PostgreSQL-like Massive OSS Adoption
Simply having Oracle-like depth in Distributed SQL is not enough. Developers must be able to experience this depth in the context of their own applications. This means delivering broad as well as deep integrations with application development frameworks, object relational mappers as well as installers for any cloud infrastructure. Developer evangelism efforts to bring the benefits of these integrations to the respective communities have to be undertaken. PostgreSQL has become massively popular over the years by following this approach. As a distributed incarnation of PostgreSQL, we are well positioned to execute a similar adoption approach.
3. Aurora-like DBaaS Monetization
Without an effective monetization strategy that enables continuous re-investment into the OSS project, the OSS project risks atrophy in the long run. As we highlighted previously, DBaaS-driven monetization is the way to go. Amazon Aurora is the poster child for highly successful fully-managed DBaaS. It essentially monetizes MySQL and PostgreSQL, two massively popular OSS DBs, using the benefits of an AWS-managed service. However, enterprises also need the additional flexibility to self-manage the DBaaS on their own infrastructure if they so desire. That is exactly what Yugabyte Cloud and Yugabyte Platform are designed to do.
Summary
YugabyteDB with its Google Spanner-inspired storage architecture and PostgreSQL-based query layer is built to provide modern applications with Oracle-like depth in distributed SQL, but on cloud native infrastructure. With the licensing changes highlighted in this post, we want to enable engineering teams to move faster than ever before towards such cloud native applications. We understand that many will find our vision too ambitious and some may even find it impossible. Rather than argue with such observations, we agree that the burden of proof is on our shoulders. Watch this space for our progress, you will be pleasantly surprised 🙂
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and Amazon Aurora.
- Get started with YugabyteDB on the cloud or container of your choice.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


