GraphQL & Distributed SQL Tips and Tricks – July 10, 2020
July 10, 2020
Welcome to this week’s tips and tricks blog where we explore topics related to combining GraphQL and YugabyteDB to develop scalable APIs and services. We’ll also review upcoming events, new documentation, and blogs that have been published since the last tips and tricks post.
This next section is for those of you who might be new to either GraphQL or distributed SQL.
What’s GraphQL?
GraphQL is a query language (more specifically a specification) for your API, and a server-side runtime for executing queries by using a type system you define for your data. GraphQL is often used for microservices, mobile apps, and as an alternative to REST. Although GraphQL isn’t tied to any specific database or storage engine and is instead backed by your existing code and data, YugabyteDB is a perfect complement to GraphQL giving you horizontal scalability, fault tolerance, and global data distribution in a single system. Popular open source GraphQL projects include Hasura and Apollo.
What’s YugabyteDB?
YugabyteDB is an open source, high-performance distributed SQL database built on a scalable and fault-tolerant design inspired by Google Spanner. YugabyteDB is PostgreSQL wire compatible and supports GraphQL along with advanced RDBMS features like stored procedures, triggers, and UDFs.
Got questions? Make sure to ask them on our YugabyteDB Slack channel, Forum, GitHub, or Stackoverflow.
Ok, let’s dive in…
How do I set up a YugabyteDB and GraphQL environment?
Check out our updated “Basic CRUD Operations Using Hasura GraphQL with Distributed SQL on GKE” blog post for a quickstart on how to get both technologies configured and working together on Google Cloud. In that post we walk you through the following steps:
- Deploy a GKE cluster on Google Cloud
- Deploy a 3 node YugabteDB cluster
- Build the Northwind sample database
- Install Hasura GraphQL
- Connect Hasura to the Northwind database
- Build a simple GraphQL query to fetch a result set
If you’d like to see the above in action, check out this short video.
What’s the difference between Apollo and Hasura?
At a high-level, Hasura is an open source GraphQL engine that lets you deploy instant, realtime GraphQL APIs on top of PostgreSQL or PostgreSQL-compatible databases like YugabyteDB. Apollo is an open source GraphQL platform for seamlessly connecting application clients (such as React and iOS apps) to back-end services. Apollo also works with just about all Node.js HTTP server frameworks like Express, Koa, and Hapi. You can use any one of these projects with YugabyteDB.
GraphQL projects often combine Hasura and Apollo. So, they can certainly be thought of as complementary technologies. For example, Hasura has a half-dozen blog posts that show how the Apollo Client can be integrated with Hasura APIs. Another post worth checking out is Anupam Dagar’s “Building a React Todo App with the Hasura GraphQL Engine,” which makes use of Apollo’s excellent support for React.
How do I query multiple YugabyteDB tables in the same GraphQL query?
For this example, let’s use the Northwind sample database which simulates a company that sells speciality food products. The business requirement here is that we need to send automated messages to customers who have previously requested shipments sent to specific countries. Why? Because in order to keep shipping rates low, we often switch logistics providers in different countries and our customers appreciate knowing who to expect that will be delivering their goods. In this case, let’s say we’ve switched our Canadian shipper and would like to alert all customers who have ever requested products shipped to Canada. The first thing we need to do is identify these companies. To do so we’ll need to leverage the relationship between the customers and orders table on the customer_id column.
In SQL, our query would look like this:
SELECT DISTINCT customers.company_name, orders.ship_country FROM orders INNER JOIN customers ON orders.customer_id=customers.customer_id WHERE orders.ship_country = 'Canada';
Our SQL result set looks this:
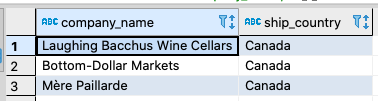
Here’s how to retrieve a similar result in GraphQL.
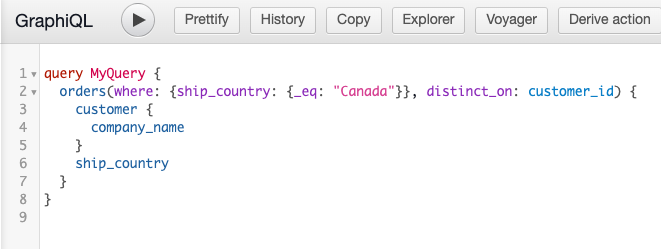
Recall that we are “joining” data between the orders and customers tables (or nodes as they are referred to in GraphQL) using the customer_id column because company_name exists in the customer table, while ship_country resides in the orders table.
Note that in the GraphQL query above we are using a where argument to filter our results with an _eq equality operator specifying “Canada.” Finally, we are using the distinct_on argument to fetch only distinct values in the customer_id column. This prevents multiple values of the same company_name to be returned.
The results of the GraphQL query should return the same values as our original SQL query.

What are the different types of queries I can perform with GraphQL?
There are three different types of GraphQL queries that roughly equate to SQL statements you are already familiar with.
- Query: Similar to a SELECT, which can be combined with various clauses like WHERE, DISTINCT, etc.
- Mutation: Similar to INSERT, UPDATE, etc.
- Subscription: Used to fetch new or updated data in real time
Is there an easy way to spin up a GraphQL API server from an existing YugabyteDB or PostgreSQL server?
Aside from Hasura (which we used in our previous example), another project to check out is the crowd-funded, open source Postgraphile GraphQL API server. Getting started is super easy. Here’s all you need to do:
Install Postgraphile
$ npm install -g postgraphile
Set up the connection between Postgraphile and YugabyteDB
Next, let’s connect Postgraphile to the Northwind database running on YugabyteDB. (Remember that YugabteDB is PostgreSQL wire compatible. This allows us to “piggy-back” on the existing PostgreSQL connectivity to Postgraphile.)
$ postgraphile -c "postgres://yugabyte:password@35.223.XX.XX:5433/northwind"
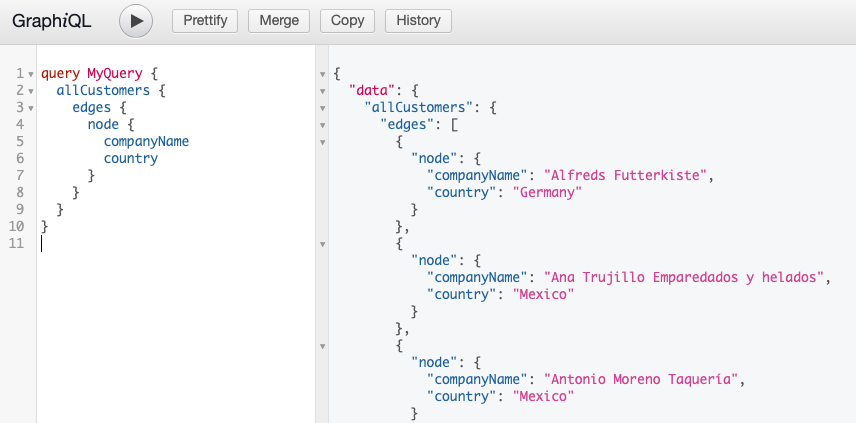
That’s it! You can now access the GraphQL API at https://localhost:5000/graphql and the GraphQL GUI/IDE at https://localhost:5000/graphiql. The IDE allows you to build queries and view results like in the screenshot shown below where we are retrieving a list of all the Northwind customer names and the country in which they are located.
New Documentation, Blogs, Tutorials, and Videos
New Blogs
- Polymorphism in SQL part one – anyelement and anyarray
- Polymorphism in SQL part two – variadic functions
- SQL Puzzle: Partial Versus Expression Indexes
- Real-Time Scalable GraphQL and JAMstack with Gatsby, Hasura, and YugabyteDB
- Getting Started with Distributed SQL on Red Hat OpenShift with YugabyteDB Operator
New Videos
- Getting Started with YugabyteDB on GKE with Helm 3
- Getting Started with YugabyteDB and GraphQL on Kubernetes
- Evaluating CockroachDB vs YugabyteDB
New and Updated Docs
- We’re continually adding to and updating the documentation to give you the information you need to make the most out of YugabyteDB. We had so many new and updated docs for you, that we wrote a blog post to cover recent content added, and changes made, to the YugabyteDB documentation – What’s New and Improved in YugabyteDB Docs
Upcoming Events
- July 15 @ 10am PDT [1pm EDT] – YugabyteDB Community Q&A, Topic: PostgreSQL Compatibility; get a short demo then open Q&A
- July 16 @ 7am PDT [1pm EDT] – The Cloud-native, distributed PostgreSQL database: YugabyteDB; attend this ProHuddle webinar to learn about cloud native distributed databases
- July 29 @ 10am PDT [1pm EDT] – Introduction to SQL; if you need a relational database, but you never learned SQL, then this webinar is for you.
- Aug 17 – 20 – KubeCon + CloudNativeCon Europe 2020 Virtual
Get Started
Ready to start exploring YugabyteDB features? Getting up and running locally on your laptop is fast. Visit our quickstart page to get started.

 When Node Is Lost and Then Brought Back Into Cluster?")
