PostgreSQL How To: Installing the Chinook Sample DB on a Distributed SQL Database
July 30, 2019
In this post we are going to walk you through how to download and install the PostgreSQL version of the Chinook sample DB on the YugabyteDB distributed SQL database with a replication factor of 3.
What’s YugabyteDB? It’s a high performance distributed SQL database for global, internet-scale apps. YugabyteDB is a PostgreSQL-compatible database. Similar to Google Spanner, YugabyteDB gives you all the scalability characteristics of NoSQL, without sacrificing the ACID transactions or strong consistency you are accustomed to with PostgreSQL.
About the Chinook Sample DB
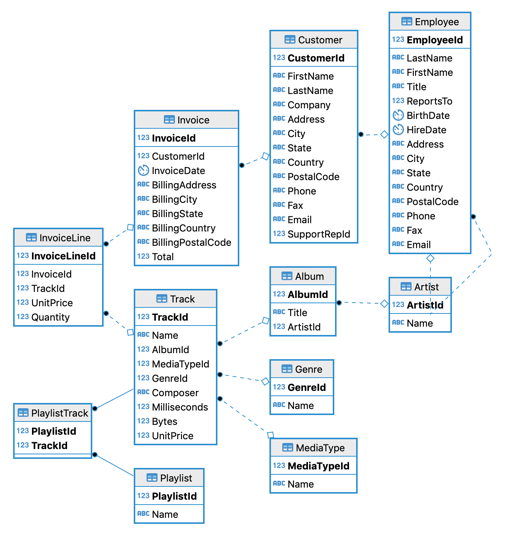
The Chinook data model represents a digital media store, including tables for artists, albums, media tracks, invoices and customers. Media related data was created using real data from an iTunes Library. Customer and employee information was created using fictitious names and addresses that can be located on Google maps, and other well formatted data (phone, fax, email, etc.). Sales information was auto generated using random data for a four year period. The basic characteristics of Chinook include:
- 11 tables
- A variety of indexes, primary and foreign key constraints
- Over 15,000 rows of data
Here’s an ER diagram of the Chinook data model:
Download and Install YugabyteDB
For complete instructions on how to get up and running on a variety of platforms including prerequisites, check out our Quickstart Guide. In the following section we’ll cover the basic steps for getting up and running in just a few minutes with a local 3 node cluster on your Mac.
Download and Extract YugabyteDB
$ $ wget https://downloads.yugabyte.com/yugabyte-2.0.1.0-darwin.tar.gz
$ tar xvfz yugabyte-2.0.1.0-darwin.tar.gz && cd yugabyte-2.0.1.0/
Note: The above instructions are for version 1.3.0. To find the latest version of YugabyteDB, visit the quickstart page.
Configure Loopback Addresses
Add a few loopback IP addresses for the various YugabyteDB nodes to use.
sudo ifconfig lo0 alias 127.0.0.2
sudo ifconfig lo0 alias 127.0.0.3
sudo ifconfig lo0 alias 127.0.0.4
sudo ifconfig lo0 alias 127.0.0.5
sudo ifconfig lo0 alias 127.0.0.6
sudo ifconfig lo0 alias 127.0.0.7
Create a 3 Node Cluster
With the command below you’ll create a 3 node cluster with a replication factor of 3.
$ ./bin/yb-ctl --rf 3 create
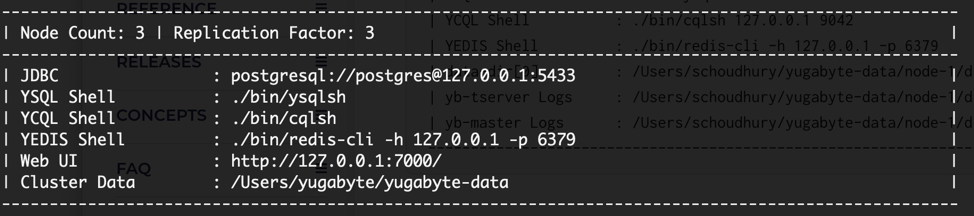
Check the Status of the YugabyteDB Cluster
Now let’s take a look at the status of the cluster and all the nodes that comprise it.
$ ./bin/yb-ctl status

As you can see from the output, we have three nodes running locally with a replication factor of 3. This means that every piece of data is being replicated on all three nodes.
Enter the YSQL shell
Next run the ysqlsh command to enter the PostgreSQL shell.
$ ./bin/ysqlsh --echo-queries
ysqlsh (11.2)
Type "help" for help.
postgres=#
What’s YSQL? It’s YugabyteDB’s PostgreSQL-compatible, distributed SQL API.
We are now ready to build the Chinook database.
Download and Install the Chinook Database
Download the Chinook Scripts
You can download the Chinook database that is compatible with YugabyteDB from our GitHub repo. The three files are:
- chinook_ddl.sql which creates tables and constraints
- chinook_genres_artists_albums.sql which loads artist and album information
- chinook_songs.sql which loads individual song information
Create the Chinook Database
CREATE DATABASE chinook;
Let’s confirm we have the exercises database by listing out the databases on our cluster.
postgres=# \l
Switch to the chinook database.
postgres=# \c chinook
You are now connected to database "chinook" as user "postgres".
chinook=#
Build the Chinook Tables and Objects
chinook=# \i /Users/yugabyte/chinook_ddl.sql
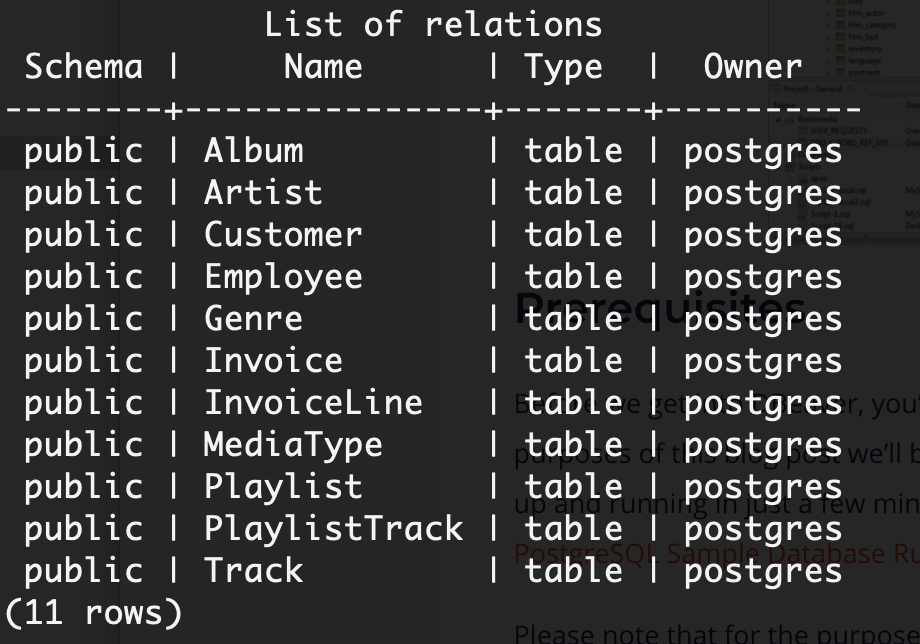
We can verify that all 11 of our tables have been created by executing:
chinook=# \d
Load Sample Data into Chinook
Next, let’s load our database with sample data.
chinook=# \i /Users/yugabyte/chinook_genres_artists_albums.sql
and
chinook=# \i /Users/yugabyte/chinook_songs.sql
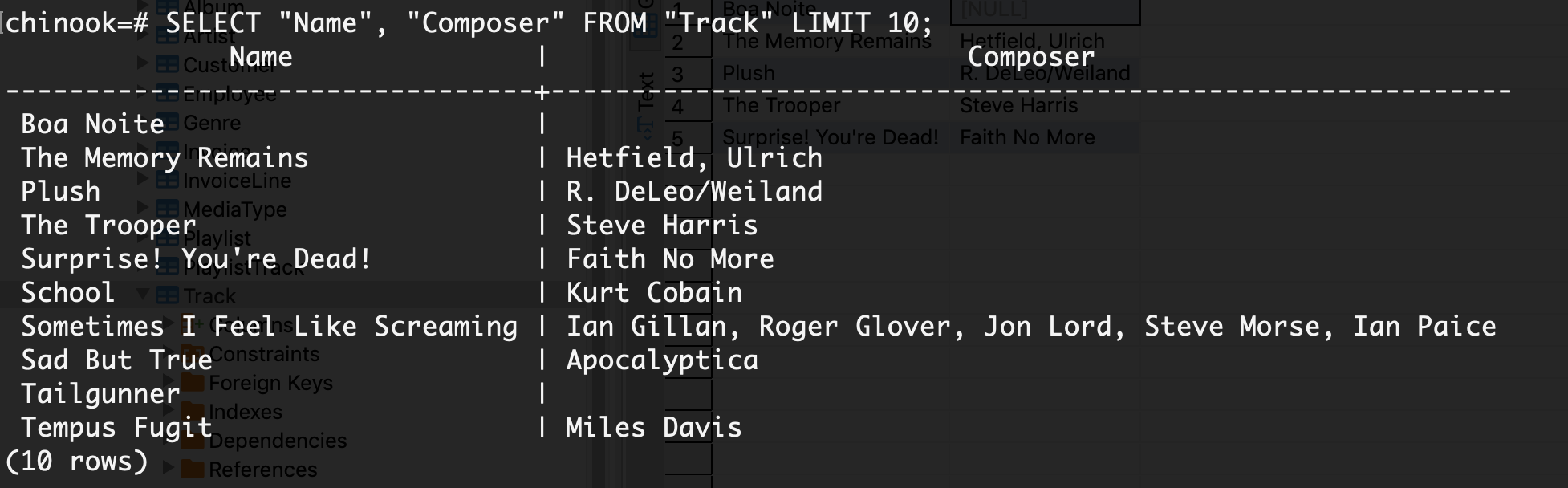
Do a simple SELECT to pull data from the “Track” table to verify we now have some data to play with.
chinook=# SELECT "Name", "Composer" FROM "Track" LIMIT 10;
Explore the Chinook Sample DB
That’s it! You are ready to start exploring the Chinook sample database.
If you are looking for a new database administration and SQL development tool, make sure to check out DBeaver, which is compatible with YugabyteDB. Installation is simple and the feature set is powerful.
What’s Next
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.

")
