Boost Productivity, Performance, and Security with New YugabyteDB Managed Innovations
March 27, 2023
Is your database slowing you down? Now you can elevate your database game with new features available in YugabyteDB Managed, our fully-managed database-as-a-service powered by YugabyteDB!
Our latest enhancements supercharge developer productivity, boost database performance and security, and simplify infrastructure management.
Let’s dive into what’s new.
Supercharge developer productivity with YugabyteDB Managed CLI
YugabyteDB Managed Command Line Interface (CLI) revolutionizes database cluster management. This user-friendly CLI simplifies the process of creating and managing clusters hosted in YugabyteDB Managed from your familiar terminal or IDE.
It automates repetitive tasks, so, whether you’re an app developer, end-user, or internal team member, you can now perform ad hoc tasks straight from your IDE, without needing to be proficient in REST APIs or Terraform.
Getting started with YugabyteDB Managed CLI is easy.
The CLI is cross-platform and supports Mac, Linux, and Windows, making it accessible to everyone. Simply install it using `brew install yugabyte/tap/ybm` on Mac or Linux, and you’ll be up and running in no time. For Windows, download the latest release from Github. You can interact with YugabyteDB Managed resources, such as clusters, VPCs, network allow lists, and more, from the comfort of your terminal.

Install YugabyteDB Managed CLI quickly and easily using ‘brew’ Take a Preview of AWS PrivateLink Support for Enterprise-Ready, Secure Networking
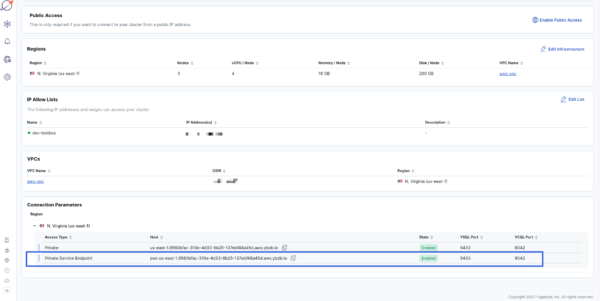
YugabyteDB Managed now includes support for AWS PrivateLink in preview mode, expanding the network access management options available to you. Establish ultra-secure network connectivity for dedicated clusters created in YugabyteDB Managed on AWS, for a more secure and convenient alternative to VPC peering.
AWS PrivateLink provides unidirectional access to your databases, making it harder for unauthorized users to gain access to your data. Setting up AWS PrivateLink is simple via our self-service process using YugabyteDB Managed CLI. Overlapping CIDR (Classless Inter-Domain Routing) ranges are not a problem with AWS PrivateLink, which means less network administration overhead for you.
Secure and enterprise-ready networking with AWS Privatelink Scale 2x Faster To Quickly Respond to Changing Needs
YugabyteDB Managed’s scaling capabilities just received a major speed boost, doubling the performance of vertical scaling operations on dedicated clusters. With this upgrade, making infrastructure changes in YugabyteDB Managed is now faster than ever before, ensuring you are always ready for planned or unplanned spikes in usage. We have streamlined our infrastructure by minimizing the number of node restarts and executing operations concurrently. As a result, you can elevate your applications to new heights and stay ahead of the competition.
Enhance Database Performance with New Observability Capabilities and High-Def Insights
If your business relies on a database to store critical data, you know it’s crucial that your database performs at the optimal level. Slow database performance can significantly disrupt your operations and result in lost revenue.
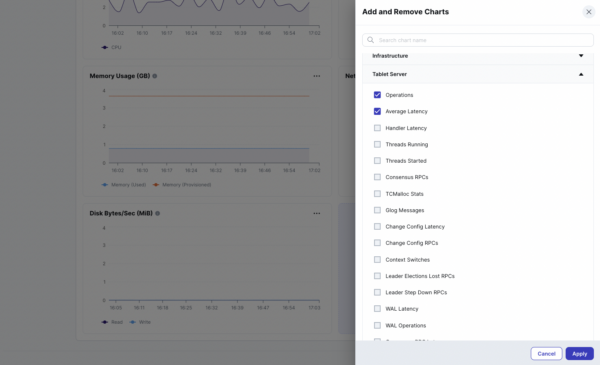
YugabyteDB Managed now provides over 125 new SQL and storage layer metrics. With these new metrics, you’ll gain even deeper insights into your database’s performance, making it easier to identify and resolve performance issues quickly.
New visualization options in the cloud-based user interface provide you the flexibility to reorder metrics to create customized dashboards and synchronize tooltips in charts for easier troubleshooting. As a result, you can quickly pinpoint performance bottlenecks and take corrective action to keep the database running smoothly.
New observability capabilities enable customized views with user selected charts and metrics.

Sign-up Today For a Full-Featured Trial and Discover All These Advanced Features!
YugabyteDB Managed is now available as a free, full-featured trial, allowing you to experience the full platform benefits. Use this trial to test PostgreSQL compatibility, horizontal scalability, fault tolerance, and multi-region clustering. These are the key features you need for global applications that need to be highly available, resilient to failure, and geo-distributed.
And the best part? You can get started in minutes with no credit card required. Test out the advanced features of YugabyteDB Managed to optimize your database performance and drive business success. Learn more about the trial.


