YugabyteDB Joins Google’s MCP Toolbox for AI Agent Development
November 19, 2025
Anthropic first announced the Model Context Protocol (MCP) ecosystem in November 2024. Within months, hundreds of MCP servers appeared across GitHub, each promising to connect AI agents to different data sources.
Great for innovation. But making the right choice for your use case can become a problem.
When you’re building an AI agent that needs database access, you’re suddenly comparing implementations, evaluating which ones are production-ready, and wondering if the one you pick will be maintained six months from now.
You need database-specific features supported, not buried behind generic compatibility layers. You also want to be sure that what you’re building on won’t be abandoned in the future.
YugabyteDB’s addition to Google’s MCP Toolbox represents a shift from “build and hope they find you” to “be where developers are already looking.”
In this blog, we explore what YugabyteDB‘s addition to Google’s MCP Toolbox means for building production AI agents. We reveal how the Toolbox solves problems like permissions and observability, detail how YugabyteDB’s distributed SQL features (load balancing, topology-aware routing) become first-class options, and discuss the realities of finding the right database for your LLM.
What Does Google’s MCP Toolbox Solve?
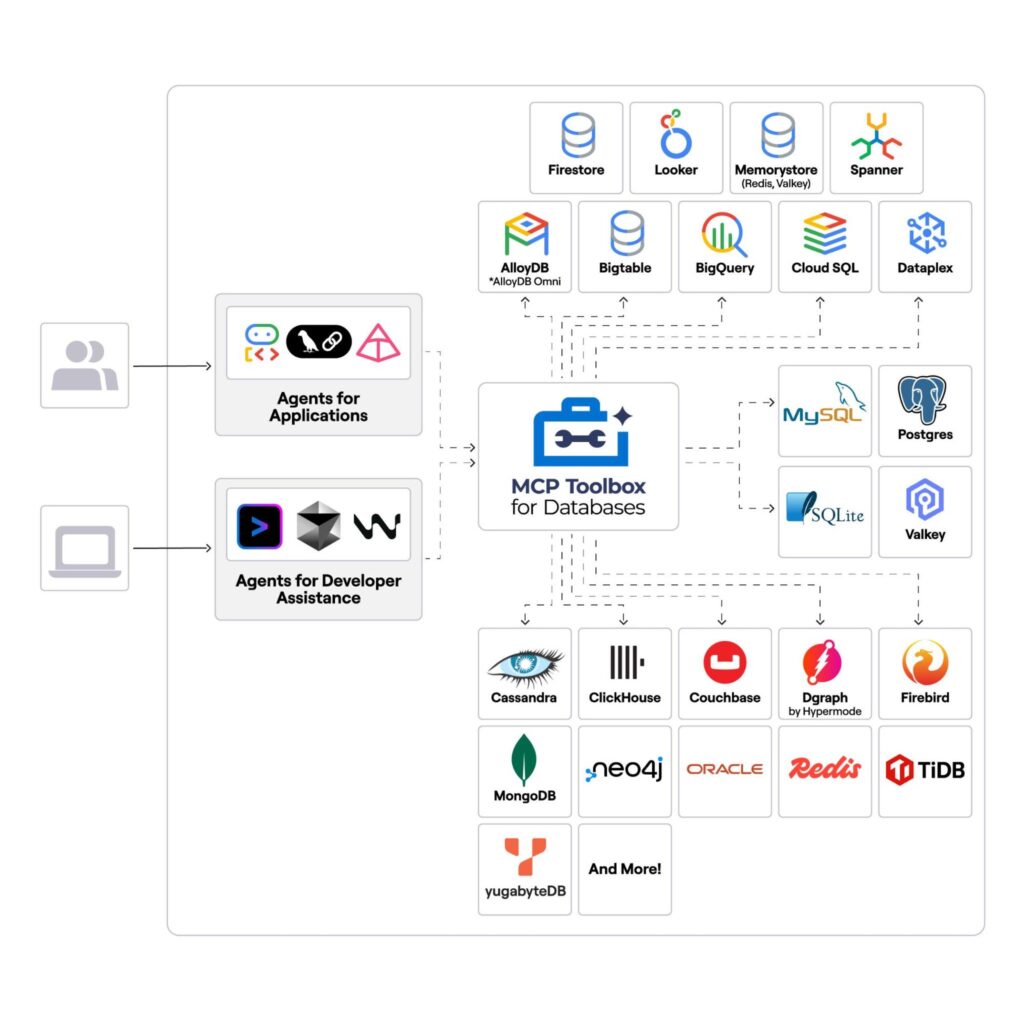
Google’s MCP Toolbox for Databases is architected to solve specific production problems, so you don’t need to painstakingly build the framework for managing autonomous AI agent calls to your database..
Google’s MCP Toolbox for Databases includes:
Granular Permission Control
Traditional database access is binary. You either have credentials or you don’t. AI agents need granular control – this agent can read but not modify, that agent can update inventory but not delete records. The Toolbox allows you to define precisely what SQL each tool can execute.
Custom Tool Definition
Instead of generic “run any query” tools, you define specific operations (search-products, update-inventory, check-order-status) that match your application’s actual needs. Your agent can only call what you’ve explicitly allowed.
Built-in Observability
When AI agents make database calls on behalf of users, you need telemetry that shows which tools were called, what parameters were passed, execution times, and failures. The Toolbox provides this visibility out of the box.
Database-Specific Feature Support
Rather than treating all databases as generic SQL endpoints, the Toolbox exposes database-specific capabilities as first-class configuration options.
That last point is why YugabyteDB’s addition to the Toolbox matters.
YugabyteDB: A Supported Source in the MCP Toolbox
YugabyteDB is now officially supported in the MCP Toolbox, joining MySQL, PostgreSQL, MongoDB, and 20+ other curated database sources.
This allows developers to access YugabyteDB’s distributed SQL capabilities, including load balancing, topology-aware routing, and data sovereignty controls, as documented and tested configuration options rather than custom workarounds.
Explore Two Approaches to MCP with YugabyteDB
This option sits alongside the YugabyteDB MCP Server we released earlier for database exploration. There are now two different tools for different stages of development.
Database Exploration: YugabyteDB MCP Server
Our open-source MCP server provides pre-built, read-only tools for exploring your database through natural language:
summarize_database – Lists all tables with schema and row counts
run_read_only_query – Executes a safe, read-only SQL query
Best for: Prototyping, dashboard building, asking questions about data. It works immediately with Claude Desktop, Cursor, and Windsurf.
Agentic Orchestration and Access: MCP Toolbox for Databases
Google’s MCP Toolbox is where you define custom tools using a tools.yaml configuration file. You specify exactly what SQL operations each tool performs, from simple SELECT queries to complex UPDATE and DELETE operations.
Best for: Building production AI agents that take actions (booking systems, inventory management, order processing, etc) while maintaining strict control over permissions and operations.
Here’s what a tool definition looks like:
sources: my-yb-source: kind: yugabytedb host: 127.0.0.1 port: 5433 database: yugabyte loadBalance: true topologyKeys: cloud.region.zone1:1,cloud.region.zone2:2 tools: search-hotels: kind: yugabytedb-sql source: my-yb-source description: Search for hotels by location statement: SELECT * FROM hotels WHERE location ILIKE '%' || $1 || '%' book-hotel: kind: yugabytedb-sql source: my-yb-source description: Book a hotel by ID statement: UPDATE hotels SET booked = true WHERE id = $1
Your agent can only call the tools you define. It cannot execute arbitrary SQL.
Why Distributed SQL Features Matter for AI Agent Workloads
YugabyteDB is more than just PostgreSQL-compatible; it delivers distributed SQL. For production AI agents, that distinction becomes immediately apparent under load.
Load Balancing for Burst Query Patterns
AI agents don’t query databases like traditional applications. A single user conversation can trigger 5-15 rapid-fire database calls as the agent gathers context, validates data, and takes actions. Multiply this across hundreds of concurrent conversations, and you have burst traffic patterns that can overwhelm a single database connection.
Consider an enterprise support agent handling customer inquiries. During business hours, conversation volume spikes. Each conversation might trigger:
- User history lookup
- Order status checks
- Inventory queries
- Shipping updates
- Refund validations
Setting loadBalance: true in your YugabyteDB configuration enables the MCP Toolbox (through its use of YugabyteDB’s Smart Driver) to automatically distribute these queries across all database nodes, rather than relying on a single connection.
The result: consistent response times even during peak conversation loads.
You only need to specify a single host in your MCP Toolbox configuration – the YugabyteDB driver automatically discovers all other nodes in the cluster upon initial connection and handles load balancing across them. The driver queries the cluster metadata to learn about all available nodes and their health status.
Why this matters: Without load balancing, you’d need to manually configure connection pools, proxy layers, or accept degraded performance during peak usage. YugabyteDB handles this at the driver level.
Topology-Aware Routing for Global Deployments
Enterprise AI agents serve global users. A customer service agent deployed across North America, Europe, and Asia faces a fundamental latency problem – if all database queries route to a single region, some users experience 150-200ms cross-region delays. That’s the difference between “responsive” and “noticeably slow.”
YugabyteDB’s topology-aware routing solves this:
topologyKeys: cloud.region.us-east:1,cloud.region.eu-west:2,cloud.region.ap-south:3
This routing is handled by YugabyteDB’s smart driver at the connection layer – the MCP Toolbox simply makes it easy to configure these YugabyteDB-native features through its configuration file.
The node metadata (regions, zones, IP addresses) is configured when you deploy your YugabyteDB cluster. The topologyKeys setting instructs the driver on which preferred pre-configured topology to use for routing.
With this configuration, the YugabyteDB driver routes queries to geographically close nodes based on the cluster’s topology metadata. European users hit European nodes. Asian users hit Asian nodes.
The practical impact: cross-region latency (150ms+) becomes local latency (10-20ms). Your AI agent performs faster because the database layer is faster.
Why this matters: Building this routing logic yourself means custom infrastructure, increased complexity, and maintenance burden. Having it as a configuration option allows you to optimize global performance without building a distributed systems team.
Fallback Control for Data Sovereignty
Many enterprises face regulatory requirements about where data can be processed. GDPR, data residency laws, and industry-specific compliance rules require that certain queries remain within specific regions – not as a best practice, but as a legal requirement.
Setting fallbackToTopologyKeysOnly: true ensures queries only execute in your specified regions. If those regions are unavailable, the query fails rather than routing to a non-compliant region. This isn’t about optimization; it’s about maintaining compliance without building custom routing logic into your application layer.
Why this matters: Compliance failures aren’t technical problems – they’re legal and financial risks. Having enforcement at the database configuration level means you can’t accidentally violate data residency requirements through application bugs.
Why Not Just Configure Distributed PostgreSQL Yourself?
You can. However, that means you must build and maintain the infrastructure that YugabyteDB provides out of the box.
Inclusion in Google’s MCP Toolbox signals these YugabyteDB features as first-class configuration options on their platform. Instead of working around limitations, you will utilize supported, documented capabilities that are custom-designed for AI agent workloads.
Production Realities: Permissions, Hallucinations, and Oversight
Building AI agents that interact with production databases introduces challenges that don’t exist with read-only exploration tools.
The Permissions Architecture
The MCP Toolbox’s tool definition model makes permissions explicit and enforceable:
tools: check-inventory: statement: SELECT quantity FROM inventory WHERE product_id = $1 update-inventory: statement: UPDATE inventory SET quantity = quantity - $1 WHERE product_id = $2 AND quantity >= $1
Each tool defines exactly what SQL it can execute. Your AI agent can only call the tools you’ve defined. It cannot execute arbitrary SQL. This isn’t security through obscurity – it’s architecture that enforces constraints.
If your support agent should only read customer data, you define read-only tools. If your booking agent needs write access, you define specific write operations. The agent framework doesn’t need special handling because the constraints are in the database access layer.
The Schema Hallucination Problem
Here’s something that needs to be stated clearly: granting your AI agent database access doesn’t guarantee that it will use your database correctly.
LLMs are pattern-matching machines, not database validators. They will confidently query columns that don’t exist, fabricate table relationships, and hallucinate schema details that sound plausible but aren’t real.
MCP access doesn’t fix this. It makes the risk more immediate because now those hallucinated queries actually execute.
What actually helps:
Explicit tool descriptions: Don’t write “searches products.” Write “searches the products table, which has columns: id, name, category, price, stock_quantity (integer).”
Schema introspection: The Toolbox supports schema discovery tools that let your agent query table structures before building queries.
Development testing: Log every SQL query your agent generates during testing and watch for nonsensical patterns.
Validation layers: Your tools can include WHERE clauses that constrain what data can be accessed, regardless of what the agent requests.
This isn’t a YugabyteDB issue or an MCP Toolbox issue. It’s the current reality of LLMs and structured data. Be aware of the risk and plan for it.
Telemetry and Observability
When AI agents are making database calls on behalf of users, you need visibility into what’s actually happening. The MCP Toolbox includes built-in telemetry that logs:
- Which tools were called
- What parameters were passed
- Query execution times
- Errors and failures
Oversight isn’t optional when running production agents. It’s essential for debugging unexpected behavior, auditing agent actions, and understanding performance bottlenecks. Without telemetry, you’re flying blind when something goes wrong.
The combination of explicit permissions, schema awareness, and comprehensive logging creates the observability layer you need when autonomous agents interact with production databases.
Conclusion
The shift from scattered MCP implementations to curated, supported platforms makes it easier to build production AI agents with confidence. YugabyteDB’s distributed SQL capabilities are now first-class citizens in Google’s AI development ecosystem, which provides the tooling and documentation necessary to support production deployments.
Getting Started:
- Start building with fully managed YugabyteDB Aeon, which offers a free tier that’s ready for AI agent workloads.
- Check out an example of MCP Toolbox in action with YugabyteDB
- Explore YugabyteDB’s MCP Toolbox documentation to view configuration options.
- Learn more about YugabyteDB’s AI solutions and discover how distributed SQL enables intelligent applications.


