Bringing Truth to Competitive Benchmark Claims – YugabyteDB vs CockroachDB, Part 1
May 4, 2020
At Yugabyte, we welcome competition and criticism. We believe these aspects are essential to the wide adoption of a business-critical, fully open source project like YugabyteDB. Specifically, constructive criticism helps us improve the project for the benefit of our large community of users. Engineers at Cockroach Labs posted their analysis of how CockroachDB compares with YugabyteDB a few months ago. We thank them for taking the time to do so. Unfortunately, there were a number of factual errors in their understanding of YugabyteDB’s design, which resulted in them promoting misconceptions. We would like to take this opportunity to clear up the misconceptions.
We believe that anyone who wants to understand the inner workings of an open source database should be able to do so, irrespective of their role as a user, a database enthusiast, and even a competitor. Therefore, we took the time to write the following additional content about the architecture and design of YugabyteDB.
- Why we built YugabyteDB by reusing the PostgreSQL query layer
- 5 query pushdowns YugabyteDB does on top of PostgreSQL
- 4 sharding strategies we analyzed before building YugabyteDB
- Performance enhancements in YugabyteDB v2.1
- Design of automatic tablet splitting in YugabyteDB
TLDR
1. YugabyteDB is not a “monolithic SQL database grafted onto a distributed KV database” as claimed by their post. It is a full-featured, ACID-compliant distributed SQL database that not only scales writes horizontally and self-heals from failures, but also performs distributed query execution through “code shipping” (aka pushdowns). The post cites reuse of PostgreSQL’s query layer as the basis for this inaccurate claim. The truth is that this reuse is an architectural strength that allows YugabyteDB to support advanced RDBMS features that are missing in CockroachDB.
2. Yugabyte SQL (YSQL) supports range sharding along with the ability to pre-split a range into multiple shards (aka tablets). However, the default option is hash sharding (and not range sharding) so that SQL workloads can immediately benefit from horizontal scaling. Furthermore, there is neither a limit on the number of tablets nor on the size of a single tablet. Manual tablet splitting is available whenever large tablets need additional processing power. Dynamic tablet splitting is a work in progress.
3. Contrary to the claim suggesting otherwise, YSQL supports pessimistic locking in the form of explicit row-level locks. The semantics of these locks closely match that of PostgreSQL.
4. YugabyteDB offers online index rebuilds and schema changes in the context of the Yugabyte Cloud QL (YCQL) API today. These features for the YSQL API are a work in progress.
5. With YugabyteDB v2.1, YSQL outperforms CockroachDB v19.2 in the YCSB benchmark especially as data volume stored per node grows into TBs. Additionally, the 2.1 release also makes significant performance improvements on industry standard benchmarks like pgbench, sysbench, and TPC-C.
Setting the record straight
Distributed SQL vs a monolithic SQL architecture
Cockroach Labs post makes a false claim that YugabyteDB uses a monolithic SQL architecture (meaning “code-shipping” pushdowns cannot be done). Excerpts from the Cockroach Labs post:
We discovered differences between CockroachDB’s distributed SQL execution which decomposes SQL queries in order to run them close to data, and Yugabyte’s SQL execution which moves data to a gateway node for centralized processing.
…
Rather than a distributed SQL database, Yugabyte can be more accurately described as a monolithic SQL database on top of a distributed KV database.
…
CockroachDB delivers a “code-shipping” instead of a “data-shipping” architecture. This is of vital importance in a distributed architecture.
Many of us at Yugabyte have worked on the internals of multiple popular databases such as Oracle, Apache Cassandra, and Apache HBase, and we pride ourselves on the careful consideration of our architectural choices. We are well aware of the advantages of moving query processing closer to data to limit the amount of data shipped across nodes in a distributed system.
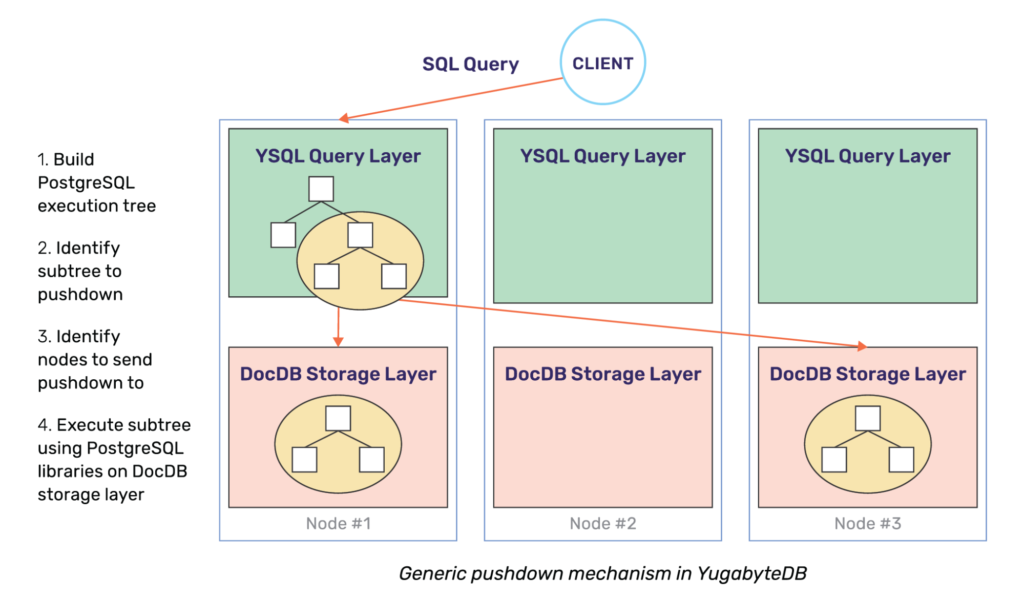
“Code shipping” pushdowns to the storage layer is in fact a foundational feature of YugabyteDB. Our recent post goes into some of the pushdowns YugabyteDB implements by modifying the PostgreSQL execution plan. The post covers the following types of pushdowns:
- Single row operations such as
INSERT,UPDATE,DELETE - Batch operations such as
COPY FROM,INSERTarray of values and nested queries - Efficiently filtering when using index predicates
- Expressions and how they get pushed down
- Various optimizations for index-organized tables such as predicate pushdowns, sort elimination, handling
LIMITandOFFSETclauses
Thus, YugabyteDB not only inherits PostgreSQL’s query handling and optimizations at all layers, it also has a robust framework to implement additional distributed SQL optimizations. Note that performing these additional pushdowns to support a wider array of queries represents a continuum of work. This would be the case for any database – CockroachDB and YugabyteDB are no exceptions.
 Hash vs range sharding
Hash vs range sharding
 Hash vs range sharding
Hash vs range shardingNow, let’s turn to the hash vs range sharding debate. Again, quoting from CockroachDB’s blog:
Defaulting to hash partitioning is a dubious choice, as it differs from the PostgreSQL default and the normal expectations for a SQL table. Many NoSQL systems use hash partitioning which is a primary factor in the difficulty of implementing full SQL on top of such systems.
One of the primary reasons to pick a distributed SQL database is horizontal write scalability, where data distribution across nodes is a fundamental concern. The scheme to distribute data across nodes is called sharding (aka horizontal partitioning).
In a single-node PostgreSQL database, since horizontal scalability is not a concern, the notion of sharding data for distribution across nodes is irrelevant. Hence, storing data in any form other than range sorting (essentially range sharding with only one shard) is unnecessary. Our blog post on sharding strategies explains our decision making process and highlights why YugabyteDB supports both hash and range sharding with hash sharding as the default. Given the fundamental need to deliver horizontal scalability in a distributed SQL database, we strongly believe we made the right choice. Additionally, we believe there are many real-world applications that don’t need range-sharded tables and scale better with hash-sharded tables. The industry standard TPC-C benchmark serves as a good example.
The next obvious concern is related to the efficacy of each sharding strategy in the context of load balancing and hotspot mitigation. Their blog post calls this aspect out as below.
Load balancing and load hotspots are fairly common concerns in distributed systems. Even though distributed systems may scale horizontally in theory, developers still need to be careful to access them in ways that can be distributed. In a range partitioned system, load can become imbalanced if it focuses on a specific range of data. In a hash partitioned system, load can become imbalanced if it focuses on a specific hash bucket due to hash collisions.
…
This (a workload writing to sequential keys) would be considered an anti-pattern in CockroachDB, and it’s why we recommend avoiding such access patterns in our documentation.
Given the native support for hash sharding in YugabyteDB, the popular sequential key insert workload is certainly not an anti-pattern. Claiming to build a massively scalable database with range sharding only, leaving it up to the user to implement hash sharding and rationalizing that this is the default behavior of PostgreSQL (which is not horizontally scalable) is the more dubious choice in our opinion. [Update: While we have not yet reviewed the details, it appears that CockroachDB will be adding support for hash sharded indexes in its next major release. This affirms their acknowledgement of the merit of our viewpoint about hash sharding being essential to distributed SQL databases.]
Distributed transactions with pessimistic locks
The CockroachDB blog post stated the following:
The functionality and limitations of the DocDB transactions are directly exposed to SQL. For example, DocDB transactions provide no pessimistic locks for either read or write operations. If two transactions conflict, one will be aborted. This behavior is similar to the original CockroachDB transaction support.
…
Besides performance, aborting one of the transactions during conflicts requires the application to add retry loops to their application code. CockroachDB now has a pessimistic locking mechanism to improve the performance under contention and to reduce user-visible transaction restarts.
Distributed transactions in YugabyteDB are designed with extensibility in mind. The DocDB transaction layer supports both optimistic and pessimistic locks. When two transactions in YugabyteDB conflict, the transaction with the lower priority is aborted. Pessimistic locks are achieved by the query layer assigning a very high value for the priority of the transaction that is being run under pessimistic concurrency control. This has the effect of the current transaction taking precedence over other conflicting transactions.
YugabyteDB opts for optimistic concurrency control to support a high throughput of concurrent transactions. In cases when contention is high, YugabyteDB recommends using pessimistic concurrency control with explicit row-locks. These transactional capabilities allow YugabyteDB to support most of the pessimistic row-level locking features that PostgreSQL supports including:
FOR UPDATEFOR NO KEY UPDATEFOR SHARE
Online schema changes
The blog post by Cockroach Labs pointed out that schema changes are not coordinated across nodes. The example used was rebuilding indexes on a table that had existing data and had concurrent operations running. The feature to rebuild indexes in a safe and distributed manner has been available starting with the YugabyteDB 2.1 release in the context of the YCQL API. This feature is being actively worked on for the YSQL API. We acknowledge that this capability was not available in YugabyteDB v2.0, the release available at the time they authored their post. They wrote:
We created a table, added some data, and then added an index. While the index was being added, we concurrently inserted into the table on another node. The end result was an index that is out of sync with the main table data.
While the observed behavior is correct, this issue has nothing to do with YugabyteDB’s reuse of PostgreSQL query layer. Rather, it stems from the fact that backfilling an index on a table that already has data was not supported at that time.
The other issue that was pointed out is the existence of catalog mismatch errors. These happen when a node decides that it has a stale version of the schema. As a system of record, YugabyteDB prioritizes safety above all else. Currently, these catalog version mismatch errors are surfaced in a few more scenarios than desirable. That said, the same framework being used for index rebuild also lends itself to performing other online schema changes in a safe manner without resulting in spurious errors. The catalog version mismatch errors, which are encountered as a result of online schema changes, will gradually be addressed by this framework.
Overall, we have made a lot of improvements in this area in YugabyteDB, showing there is nothing fundamental about the architecture and these issues are easily addressable.
Tablets and splitting
There was some misinformation with respect to how shards (aka tablets) work in YugabyteDB. In this section, we’ll clear up the matter. They wrote:
We discovered that Yugabyte SQL tables have a maximum of 50 tablets.
YugabyteDB tables do not have any hard limits on the number of tablets. For example, a single table was split into 2000 tablets spread across a 100 node cluster in our benchmark of achieving 1 million concurrent inserts per second. Additionally, multiple users are running YugabyteDB in production with thousands of tablets per cluster. So, this claim is completely inaccurate. Additionally, there is no limit on the size of a single tablet.
We discovered that a Yugabyte range partitioned table is limited to a single tablet which limits the performance and scalability of such tables.
The feature to split a range-sharded table in YugabyteDB into multiple tablets was in progress at the time the above blog was authored. YugabyteDB now supports splitting both hash-sharded and range-sharded tables into multiple tablets. They wrote:
We discovered that Yugabyte tablets do not split or merge which requires the operator to make an important upfront decision on their data schema.
YugabyteDB tables are hash partitioned by default. Each table is pre-split into a configurable number of tablets per node in the cluster, with 8 tablets per node being the default. For example, a 10 node cluster by default would start off with 80 tablets (8 tablets per node * 10 nodes in the cluster). This mitigates the need for undertaking expensive splitting operations down the line. We agree that splitting a tablet after the initial table creation is an essential feature for handling large tablets. Currently, it is possible to manually split large tablets while full dynamic splitting is currently a work in progress.
Performance and benchmarks
YugabyteDB offers two distributed SQL APIs – YSQL (fully-relational with PostgreSQL wire compatibility) and YCQL (semi-relational Cloud Query Language with Apache Cassandra QL roots). While YCQL is already a mature high-performance API, performance of YSQL API has been steadily improving since its general availability last year. YSQL’s latest runs of industry standard benchmarks such as YCSB and sysbench reveal significant improvements. We are also developing our own TPC-C benchmark client that has strict adherence to the benchmark specification. Given that both YSQL and YCQL engines run on the same DocDB storage layer, we expect YSQL performance to closely match YCQL performance in a relatively short period of time. Below are some of the performance improvements we have made and the results observed.
Note that all of the results below can be reproduced by these instructions for the YCSB benchmark, the sysbench benchmark, and the TPCC benchmark.
YCSB- Yugabyte SQL outperforms CockroachDB
As seen below, YSQL v2.1 outperforms CockroachDB in 5 of the 6 YCSB workloads; and YCQL v2.1 significantly outperforms CockroachDB in all of the workloads. YugabyteDB was benchmarked on a cluster of three AWS nodes (each node is a c5.4xlarge instance with 16 vCPUs). The graph below shows the numbers that CockroachDB reported in their blog post (which was performed on an equivalent machine type c5d.4xlarge, with 16 vCPUs as well) along with the YugabyteDB numbers.
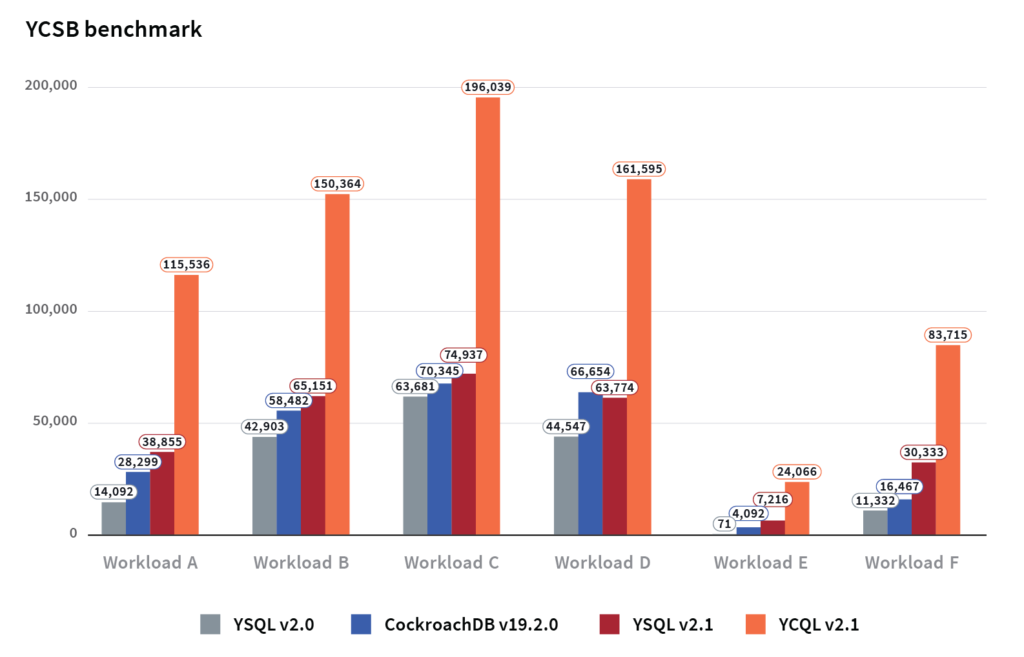
Note that for the above results, we used the new yugabyteSQL, yugabyteSQL2Keys (for Workload E only), and yugabyteCQL YCSB bindings which model the workloads efficiently on YugabyteDB. Note: the yugabyteSQL2Keys binding, which uses 2 column keys, better models Workload E with the first column identifying the thread and the second column identifying the post within the thread. For an in-depth comparison between both the databases using the standard YCSB binding for PostgreSQL, see the next post in this series.
So why did the YSQL numbers go up dramatically between v2.0 and v2.1? The performance improvements can be attributed to the following two changes.
Single-row update pushdowns
In v2.0, YSQL did not push down single-row updates to the DocDB storage layer. Therefore, these updates were unnecessarily using the slower distributed transaction execution path which required multiple RPC calls from the query coordinator. This increased the probability of transaction conflicts resulting in higher number of retries. YugabyteDB v2.1 added pushdowns for single-row updates which resulted in using an optimized fast path for transactions incurring only one RPC call, and consequently much better performanceYCSB-Fine-grained column-level locking.
Fine-grained column-level locking
YSQL v2.0 would acquire an exclusive row lock even in scenarios where the update involved a subset of columns. This approach caused a higher number of transaction conflicts, because the granularity of locks was coarser than necessary. The more optimal strategy is to acquire a shared lock on the row, and exclusively lock on just the columns that need to be updated. While this feature was already supported by DocDB for a similar usage pattern from the YCQL API, it was not wired into the YSQL API until v2.1.
sysbench
Having seen significant improvements in YCSB, we naturally expected to see similar improvement in the sysbench results as well. However, we observed that the sysbench data loading was much slower than expected. We decided to investigate this issue further.
Data loading
We started by examining the schema of the table that sysbench creates.
CREATE TABLE sbtest1 (
id SERIAL,
k INTEGER DEFAULT '0' NOT NULL,
c CHAR(120) DEFAULT '' NOT NULL,
pad CHAR(60) DEFAULT '' NOT NULL,
PRIMARY KEY id);
Notice that the table above uses the SERIAL data type as the primary key. The SERIAL data type in YugabyteDB strictly adheres to the PostgreSQL semantics of SERIAL, which needs to fetch a new, monotonically increasing value for the id column for each insert. This results in each insert operation incurring the penalty of an additional RPC call, resulting in the load phase being very slow.
In CockroachDB, the SERIAL type is a pseudo data type with semantics that are completely different from PostgreSQL, it does not use an incrementing counter but generates a unique number from the current timestamp and the id of the node (using the unique_rowid() call). The relevant snippet from CockroachDB docs is highlighted below. While the technique of using a random number does not incur the extra RPC call leading to a noticeable speedup, it breaks PostgreSQL semantics. Applications that depend on this behavior can fail in subtle ways. Below is an excerpt from the CockroachDB documentation page mentioned above:
The SERIAL pseudo data type is a keyword that can be used in lieu of a real data type when defining table columns. It is approximately equivalent to using an integer type with a DEFAULT expression that generates different values every time it is evaluated.
…
SERIAL is provided only for compatibility with PostgreSQL. New applications should use real data types and a suitable DEFAULT expression.
The correct apples-to-apples comparison would be to run both under the PostgreSQL SERIAL semantics. For CockroachDB, this can be achieved by setting the following session variable, which is only an experimental feature.
SET experimental_serial_normalization=sql_sequence
The loading times for sysbench are shown below. The cache value is set to 1 for both databases in order to force both databases to generate a single new value for the sequence.
| CockroachDB v19.2.2 (sql_sequence, cache=1) | YSQL v2.1 (default, cache=1) | |
|---|---|---|
| 1 table, 10,000 rows | 11.7 seconds | 14 seconds |
| 1 table, 100,000 rows | 1m 59s | 1m 55s |
| 1 table, 1,000,000 rows | 19m 52s | 18m |
It is evident from the table above that both databases do not fare too well under such a configuration. In other words, when CockroachDB is configured to use the same scheme of issuing one SERIAL value per insert, performance observed is nearly identical to that of YugabyteDB.
Speeding up YSQL without breaking PostgreSQL semantics
CockroachDB speeds up the sysbench load phase by using a pseudo data type, as we had seen before. Speeding up the load phase in YugabyteDB can be done in one of the following two ways, without sacrificing PostgreSQL semantics.
- Run sysbench with
auto_inc=false. This flag results in sysbench generating the random values for theidcolumn, completely eliminating the extra RPC call.
- Issue batch of values for SERIAL. It is possible to change YugabyteDB to request a batch of values for the
idcolumn instead of one at a time. This can be accomplished by performing the action the same way PostgreSQL does. For example, issuing 1000 values per RPC call can be accomplished by running the following command after creating the table:ALTER SEQUENCE sbtest1_id_seq CACHE 1000
The performance gain as a result of either of the above techniques is the same. Now, let us look at the effect on performance of the above changes. The performance of YSQL 2.0 is also shown in the table below for reference. Note that there are a number of performance improvements in YSQL v2.1 such as efficiently loading a batch of inserts compared to the previous version. Improving YSQL performance is an area of active work for the next major release as well.
| sysbench load phase | |||
CockroachDB v19.2unique_rowid() | YSQL v2.1cache=1000 | YSQL v2.0cache=1 | |
|---|---|---|---|
| 1 table, 100,000 rows | 2.591s | 6.3s | 2m12.280s |
| 1 table, 1,000,000 rows | 27.92s | 46s | 39m0.027s |
Running the sysbench workloads
Unlike v2.0, YSQL v2.1 runs all the sysbench workloads successfully. The sysbench workloads contain range queries as a dominant pattern, hence the need to use range sharding in YugabyteDB. To get started, we created a pre-split range-sharded table as shown below.
CREATE TABLE sbtest1 (
id SERIAL,
k INTEGER DEFAULT '0' NOT NULL,
c CHAR(120) DEFAULT '' NOT NULL,
pad CHAR(60) DEFAULT '' NOT NULL,
PRIMARY KEY (id ASC))
SPLIT AT VALUES ((41666),(83333),(125000), ... ,(958333));For the results of the benchmark shown below, we loaded 100K rows into 10 tables created by sysbench above, and ran the benchmark using 64 concurrent threads. Below are the throughput results based on the above table we created. While the results below reflect the current state, there is ongoing work to improve the performance even further.
| sysbench Workload | Throughput in ops/sec YSQL v2.1.5 (10 tables, range) |
|---|---|
oltp_read_only | 3,276 |
oltp_read_write | 481 |
oltp_write_only | 1,818 |
oltp_point_select | 95,695 |
oltp_insert | 6,348 |
oltp_update_index | 4,052 |
oltp_update_non_index | 11,496 |
oltp_delete | 67,499 |
TPC-C
While YSQL v2.0 could barely run the TPC-C workload, we are happy to report that the 2.1 release can run TPC-C quite well. We have yet to identify an official TPC-C benchmark implementation that adheres to the official specification accurately, and thus do not have an official tpmC number to report yet. The work to develop a TPC-C benchmark for YugabyteDB is well underway, and the preliminary results are looking promising. Expect to see a follow-up blog post on our TPC-C results shortly.
Conclusion
Making erroneous claims based on an incomplete understanding of a competing project is easy. The hard path requires analyzing architectural decisions with intellectual honesty and highlighting the implications to end users. We have always aimed to follow this hard path as we have built YugabyteDB over the last few years. Setting the record straight in response to Cockroach Labs’ unfounded claims is no different. In this post, we have not only highlighted the factual errors in their analysis but have also shown YugabyteDB’s real performance with verifiable industry-standard benchmarks. We recommend you to review part 2 of this blog series where we provide the next layer of detail behind YugabyteDB’s architecture, with an emphasis on comparing it to that of CockroachDB’s.
This is the first in a two part blog series which highlights factual errors in the Cockroach Labs analysis of YugabyteDB. In the second post in this series, we provide the next layer of detail behind YugabyteDB’s architecture, with an emphasis on comparing it to that of CockroachDB’s.


