YugabyteDB is the First Distributed SQL Database to Achieve AWS Graviton Ready Status
November 28, 2022
Introduction
 We are thrilled to announce that Yugabyte is an official AWS Graviton Ready Partner. YugabyteDB is the first distributed SQL database to receive this designation, and Yugabyte is listed on the Graviton Ready Partner site.
We are thrilled to announce that Yugabyte is an official AWS Graviton Ready Partner. YugabyteDB is the first distributed SQL database to receive this designation, and Yugabyte is listed on the Graviton Ready Partner site.
Graviton provides greater choice and flexibility when deploying workloads on AWS. Based on testing with YugabyteDB, choosing Graviton-based AWS EC2 instances can lower the total cost of ownership by up to 20% versus other instance types.
Below we’ll examine why we embarked on this engagement with AWS, and the key outcomes that drove the partnership. You’ll learn about our technical journey to test and optimize our distributed SQL database using Graviton ARM processors. Finally, we’ll share the results we achieved and the optimizations we made, which allow us to deliver equivalent throughput on both processor types.
Reducing Costs Using YugabyteDB and Graviton
Amazon’s reasons for embarking on the Graviton journey aligns perfectly with our goals to help companies accelerate their productivity and lower costs by embracing cloud native architectures.
These architectures should include a modern cloud infrastructure through an advanced data layer and forward-looking cloud native applications. Yugabyte engaged early with Amazon to test the YugabyteDB database with Graviton-based EC2 instances and deliver product enhancements that ensured the end-to-end offering for customers was validated and ready to go.
AWS Graviton processors are custom built by Amazon Web Services to deliver the best price performance for cloud workloads running in Amazon EC2. As your workloads continue to grow—requiring a massively scalable database like YugabyteDB and a scalable cloud infrastructure from AWS—cloud cost savings can significantly impact your bottom line.

Our initial goal was to validate the joint solution and optimize YugabyteDB allowing us to deliver roughly equivalent performance to existing EC2 instances, such as the C5 instance type. By matching performance, organizations can enjoy the 20% savings of Graviton-based instances, with no impact to their application performance or customer experience.
Our Journey to Graviton Readiness
Now let’s dig into the details of our journey and the update process we went through for YugabyteDB to support the ARM-based Graviton processors. For a distributed system like YugabyteDB, there are additional complexities to overcome when optimizing the database and underlying capabilities for the new chipset.
First, we added a number of features that specifically supported the ARM architecture in YugabyteDB. These features are enabled using the compiler flag -march=armv8.2-a.
At the time of our testing, Graviton2-based instances were available in over 25 AWS Regions. While our initial work focused on Graviton2 to meet the requirements of our global user base, we plan to optimize for Graviton3-based instances. These are now generally available and being rolled out in more regions worldwide
Graviton2 processors include support for Large-System Extensions (LSE). LSE provides low-cost atomic operations, which can improve system throughput for CPU-to-CPU communication, locks, and mutexes. GCC’s -march=armv8.2-a flag enables all instructions supported by Graviton2, including LSE.
Once support for the necessary instructions was enabled, our next task was to benchmark YugabyteDB on Graviton2-based instances versus standard Intel-based instances.
Benchmark Setup
To compare performance, we created a simple 3-node YugabyteDB Universe on these two instances:
- Intel Instances: c5.4xl, 16 core, 32 GB (2nd generation Intel Xeon Scalable Processor)
- Graviton Instances: c6g.4xl, 16 core, 32 GB (Graviton 2)
We used the CentOS 8 Linux distribution. The workload used was Sysbench Read and Sysbench Write with the following settings:
- Read-120 means 120 read threads using Sysbench Read workload.
- Write-48 means 48 write threads using Sysbench Write workload.
Initial numbers: C5 vs C6g
Once our setup was ready, and before applying any optimizations or changes, we captured the performance (latency and throughput). This provided a baseline for the two instances. The graphs below show the latency and throughput results for the Intel instances and Graviton instances.
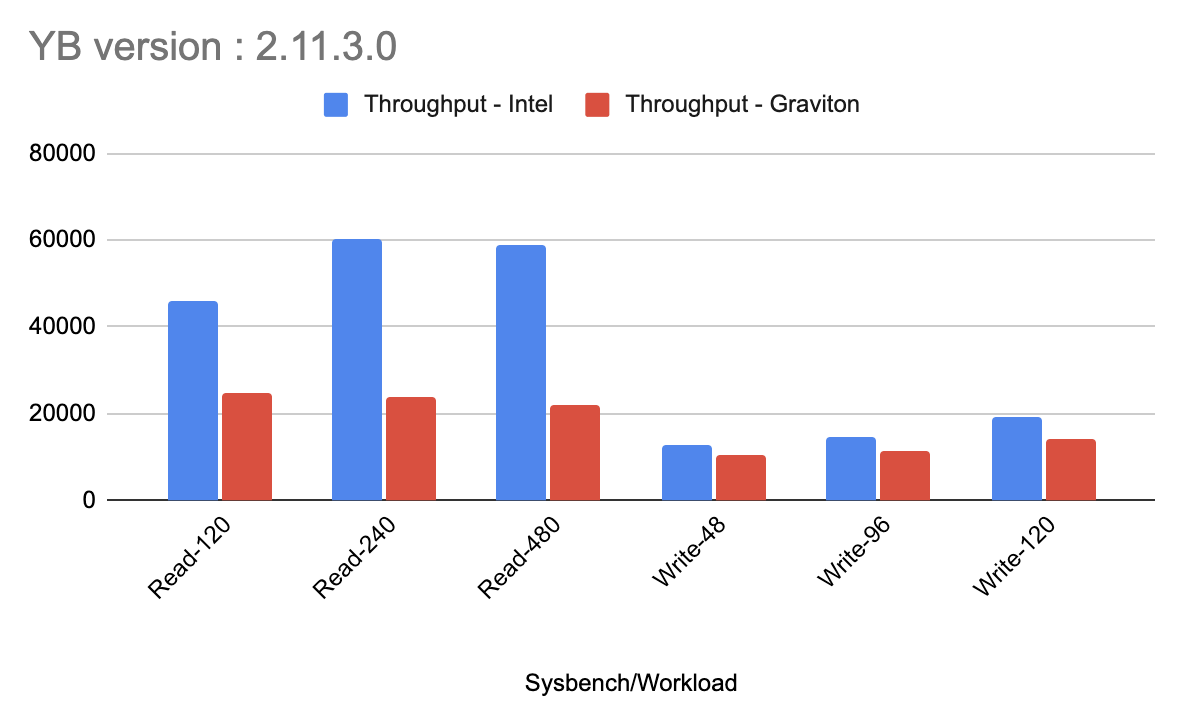
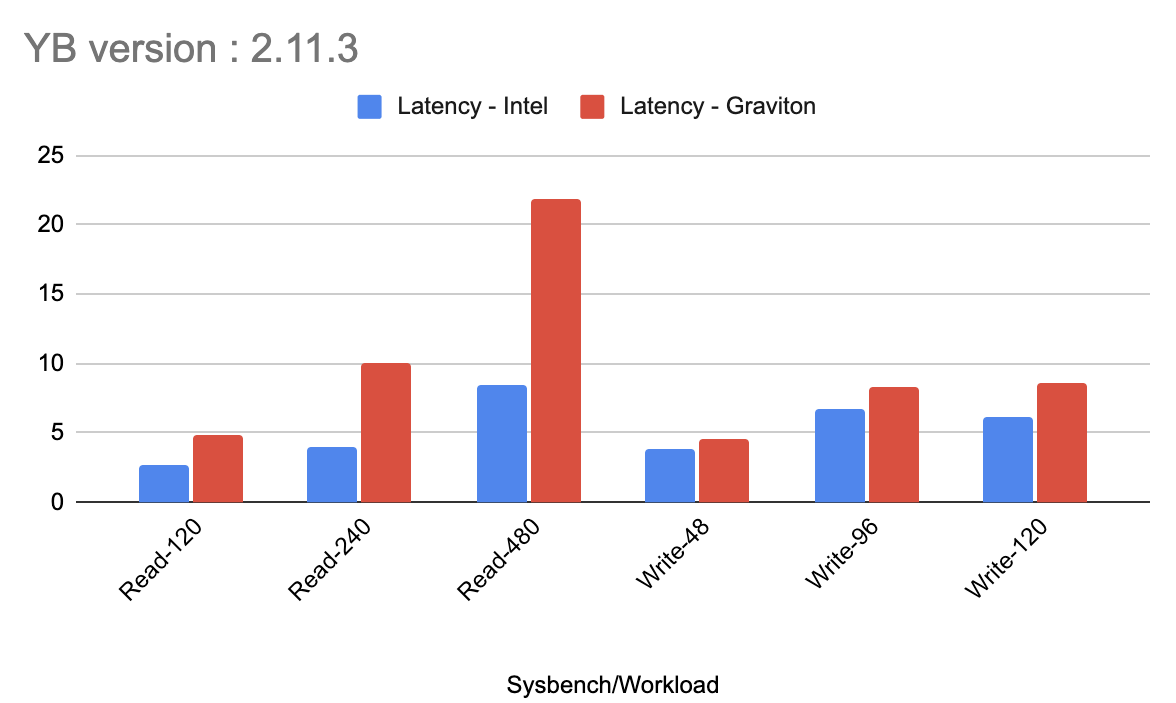
These tests show that the read workload with YugabyteDB on Graviton was not yet on par with the Intel-based servers. What was causing the big discrepancy? The answer lies in the disk stats. See the below image for the disk stats on Graviton versus Intel.
As you can see, on Intel YugabyteDB needed ~120 MBPS of disk bandwidth for ~5800 IOPs. For Graviton, YugabyteDB needed ~500 MBPS of disk bandwidth for ~6000 IOPs.
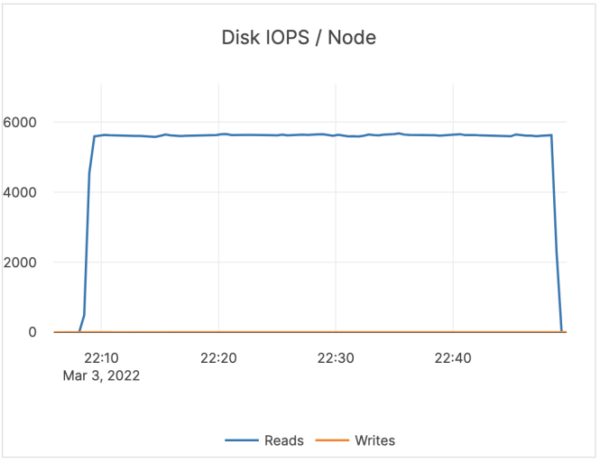
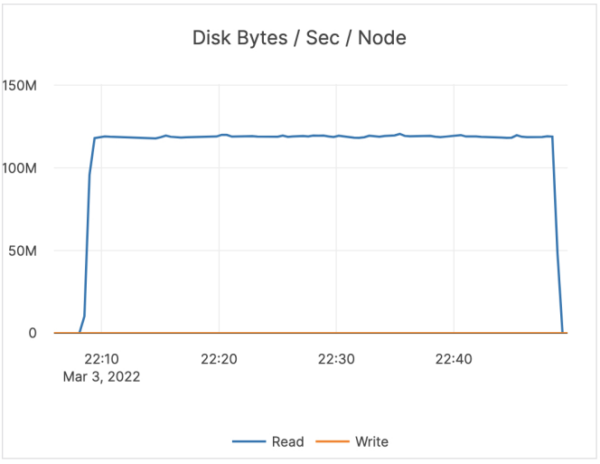
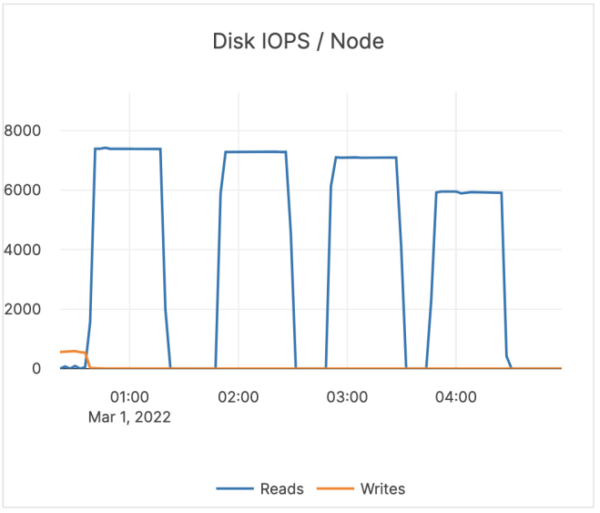
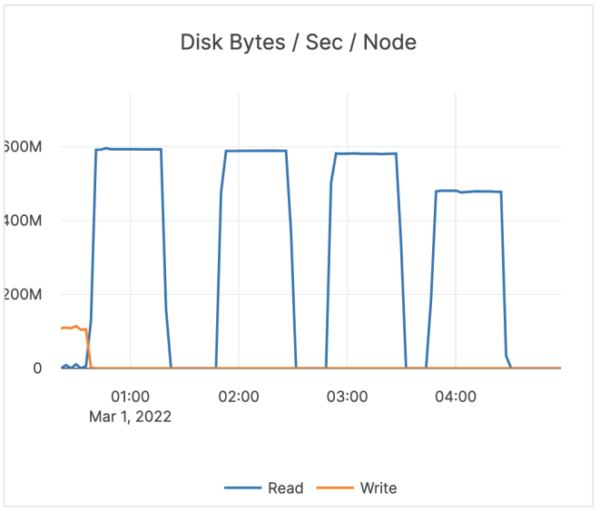
On average, YugabyteDB reads about 20 KB per Disk IOP. With Graviton, we were reading about 100 KB per Disk IOP. The large amounts being read from Graviton caused disk bandwidth exhaustion with reads. As a result, reads were getting throttled.
The reason for high disk bandwidth was the OS page size. The page size is 64K on Graviton and Centos, while on Intel and Centos it is 4K for x86. The solution was to move to Ubuntu, which has a 4K page size with Graviton, to eliminate the additional data being read per Disk IOP.
After moving to Ubuntu, the read numbers improved significantly, following the same general range as the Intel-based instances. Users should keep this in mind and not use YugabyteDB on Centos 8 and Graviton-based instances. The performance advantages of Ubuntu is shown in the two charts below:
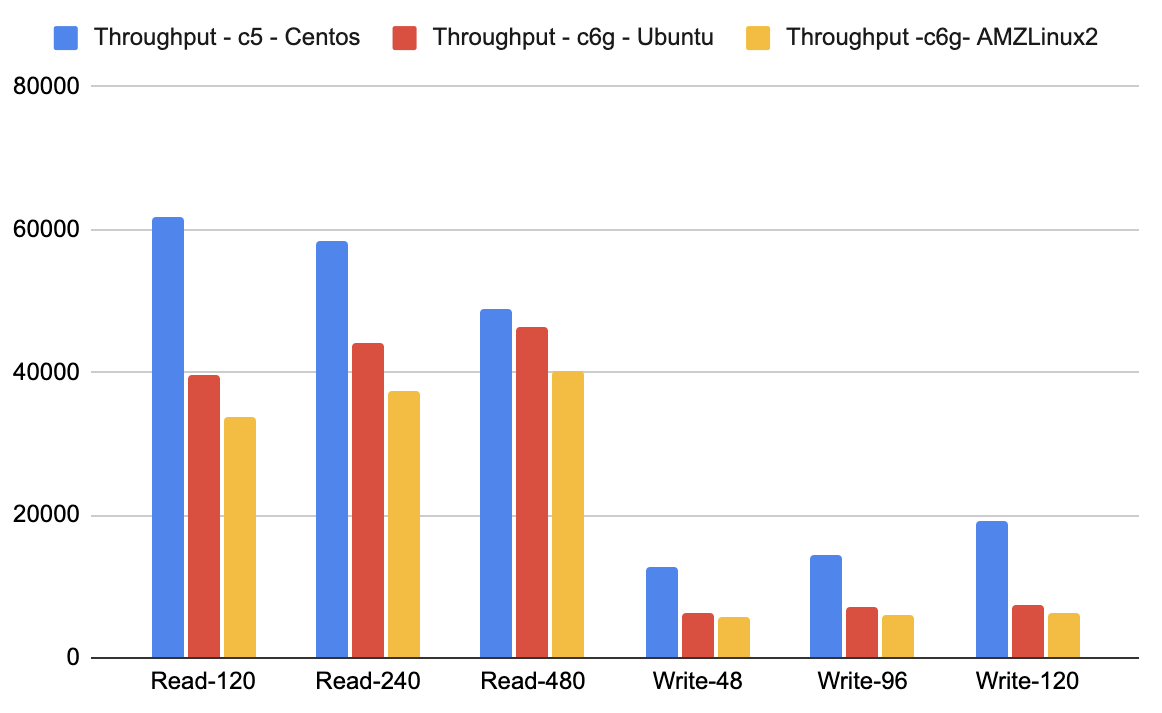
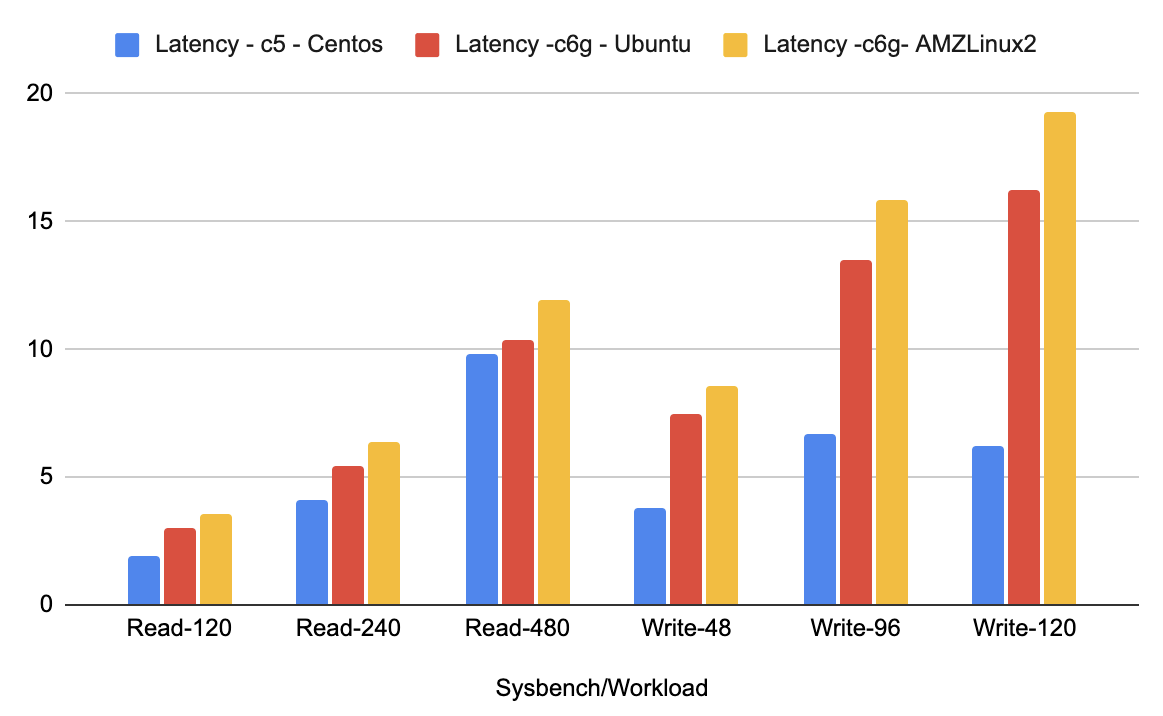
Clang Link Time Optimizations (LTO)
Once the read performance for Graviton was optimized and roughly on par with the Intel instances, we shifted our focus to optimizing write performance. YugabyteDB builds use Clang Link Time Optimization (LTO), which provides a performance boost in the range of 20% to 30%. Now that LTO is enabled automatically for Graviton builds, write performance has further improved as shown below.
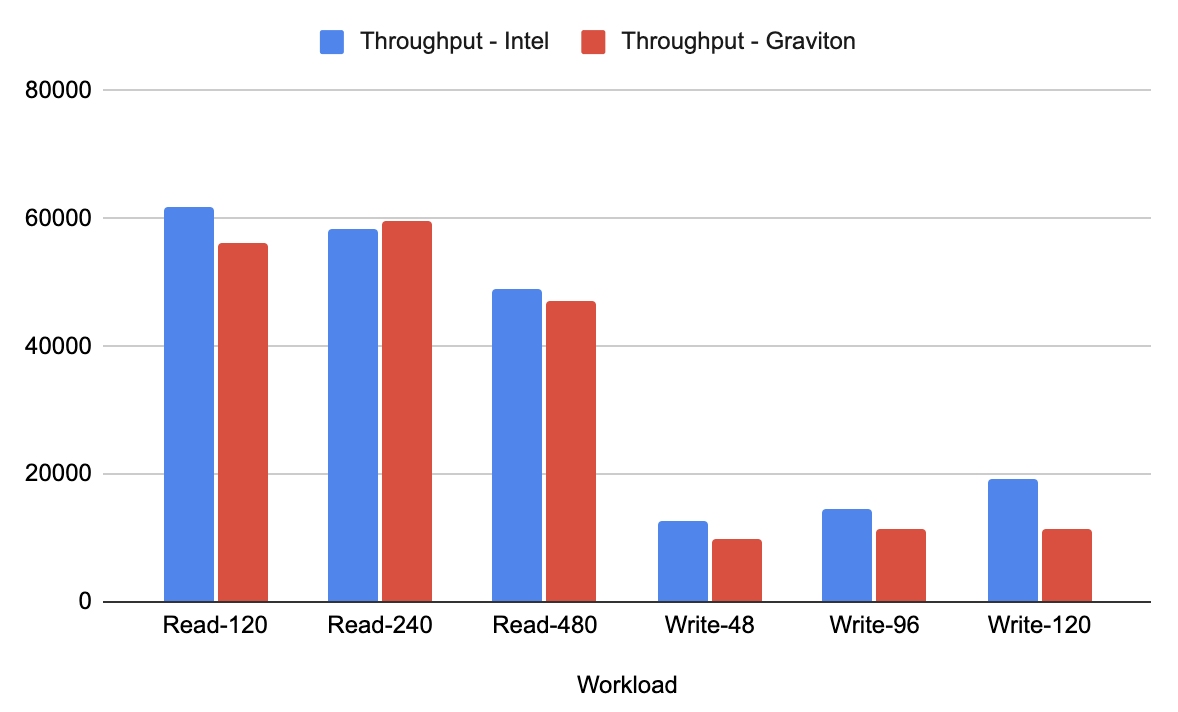
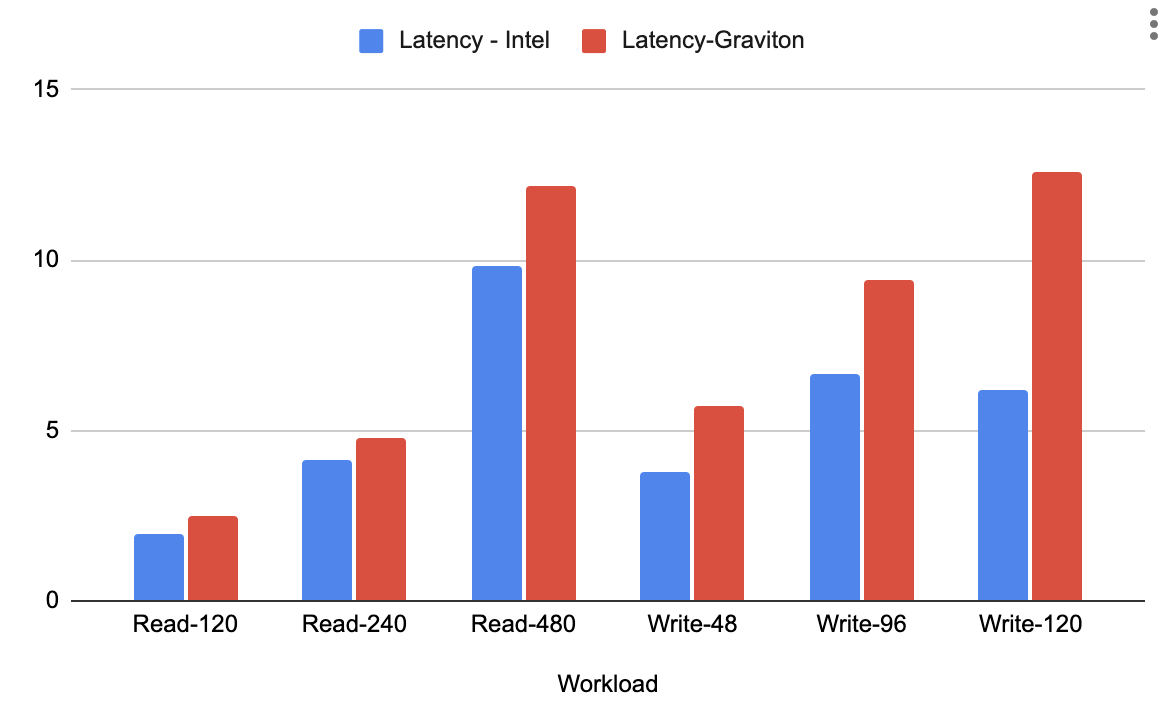
After making these additional changes and optimizations, we were getting good throughput on Graviton-based instances, but latencies on Intel-based instances are still better (based on our testing). We believe our write throughput can be improved even further. Therefore, we are actively working with the AWS team to continue to improve the overall performance of YugabyteDB on Graviton-based instances.
YugabyteDB Managed and Burstable Instances
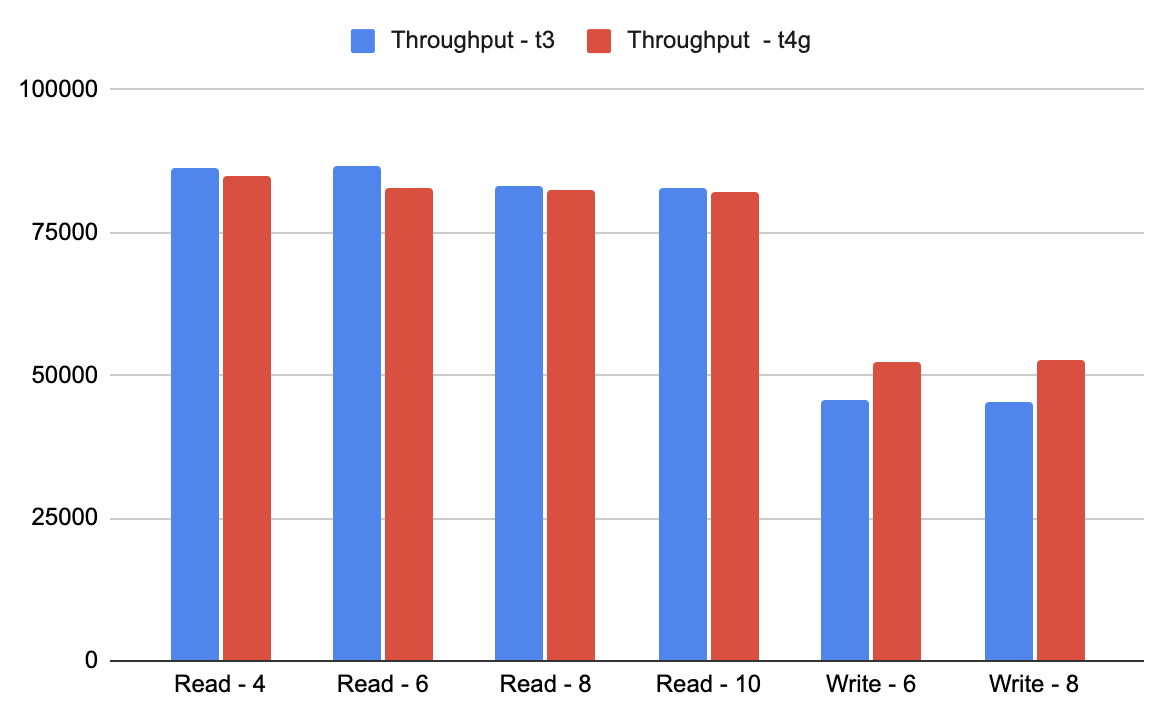
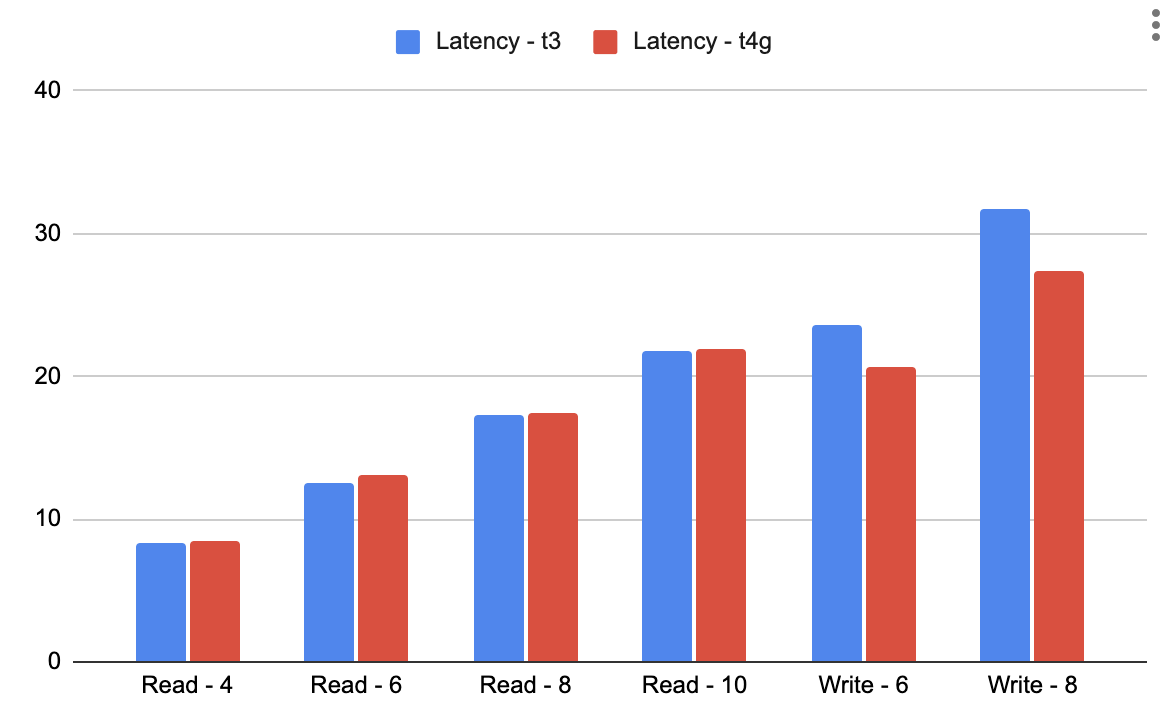
The free tier of YugabyteDB Managed runs on burstable instances and is available to anyone without cost, allowing you to quickly and easily get started with YugabyteDB. In the near future, we plan to begin migrating our free tier of this fully-managed service to Graviton-based instances. To prepare for that change, we also wanted to look at the performance of the different burstable instances.
We ran the same tests to measure the latency and throughput performance of YugabyteDB on T3 (Intel) and T4g (Graviton) instances, both of which are burstable instance types. Using these instances and the optimizations discussed previously, we got better numbers with Graviton-based instances.
Summary of Results and Next Steps
We are thrilled with the strong collaboration between the Yugabyte and AWS teams while undertaking this journey. Thanks to the work of both engineering teams, key enhancements were made.
We achieved our primary goal to provide greater choice and flexibility to our customers. By demonstrating strong performance numbers on Graviton-based instances (in the same range as Intel-based instances), customers now have more options. They can choose from two strong platforms and chipsets based on their unique needs and preferences.
For organizations looking to reduce costs, these results are of particular interest. Graviton instances are on average about 20% less than comparable Intel-based instances. Since we have demonstrated it’s possible to get equivalent throughput on Graviton-based instances, organizations have the opportunity to reduce their total cost of ownership by 20% without compromising performance.
While these results are great, our journey is not over.
Our next step is to move the YugabyteDB Managed free tier to T4g instances. We will work with AWS to continue to improve the write throughput on c6g instances and deliver even better results. Finally, we will start to try out Graviton3-based (c7g) instances as they roll out more widely. We believe this will provide further TCO benefits.
Get Started Today
 To learn more about Graviton-powered servers and YugabyteDB, watch Discover the Power of Distributed SQL + AWS Graviton.
To learn more about Graviton-powered servers and YugabyteDB, watch Discover the Power of Distributed SQL + AWS Graviton.
And if you’re ready to test out YugabyteDB on AWS sign-up to use YugabyteDB Managed for free and look for information on migration to Graviton-powered instances.


