Stream Data to Amazon S3 Using YugabyteDB CDC and Apache Iceberg
October 13, 2022
Data in YugabyteDB databases are exported to various data lakes to power business critical pipelines and dashboards.
In this blog, we will explore how YugabyteDB Change Data Capture (CDC) and open table formats like Apache Iceberg can be used to build data lakes in Amazon S3 using a single copy of the data and achieve low data ingestion latency while avoiding costly rewrites to support updates/deletes and schema evolution.
Requirements for Low Latency Export
Two components are required for low-latency export.
- Log Based CDC to extract the details of changes to the database.
- Data Lake Table formats that support ACID transactions and incremental ingestion.
Change Data Capture
Two ways to implement Change Data Capture are query and log-based. For low latency export, there are some significant advantages of log-based CDC, including:
- All change types, such as inserts, updates, and deletes, are captured.
- The system has to only process the changes; it doesn’t need to compete with other workloads to scan the tables and detect changes based on rows, numbers, or timestamps.
Table and File Formats
File formats like CSV, JSON, Apache Parquet, and Apache ORC are popular choices to build file-based data lakes on object stores.
The main advantage is that their architecture is simple and object stores such as Amazon S3, Google Cloud Storage, and Azure Data Lake Storage provide a reliable and scalable data store.
However, there are some disadvantages, including that it is hard to manage schema evolution, record-level upserts, and deletes.
Transactional data lake technologies like Apache Iceberg, Apache Hudi, and Databricks Delta Lake add metadata layers on top of the data stored in Apache Parquet or Apache ORC to provide ACID transactions and schema evolution. For example, Delta stores a transaction log in a separate Apache Parquet file.
Similarly, Apache Iceberg uses metadata files in JSON format to store table schema, snapshots, and the current snapshot. Manifest files track the files that are part of a snapshot. These metadata files:
- Enable snapshot isolation for transactions
- Reads and writes on Iceberg tables don’t interfere with each other.
- Supports concurrent writes via Optimistic Concurrency Control.
- Makes all writes atomic.
- Enables incremental ingestion where data can be inserted in small batches instead of the hourly or daily partitions keeping data fresh in the data lake.
- Expose a logical view instead of an abstract view
- Enables in-place evolution of the schema using add, drop or rename columns.
Components for Low Latency Export
YugabyteDB supports a CDC pipeline using Debezium and Kafka. The pipeline consists of two stages:
- Export CDC Events from YugabyteDB to Kafka using Kafka Connect and the Yugabyte Debezium Connector.
- Write records to Apache Iceberg tables in Amazon S3 using a Kafka-Iceberg Sink.
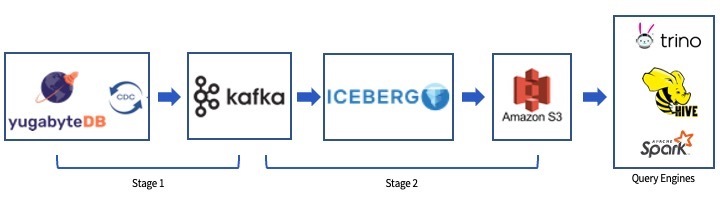
The Yugabyte Debezium Connector is hosted within a Kafka Connect process. It polls all nodes in the YugabyteDB cluster to get change events. It can transform the events into JSON or AVRO formats and publish them to table-specific Kafka topics.
Another Kafka Connect process hosts an Apache Iceberg Sink, which writes directly to directories in Amazon S3. Every batch of change events are stored in Apache Parquet files and tracked in metadata files. As soon as the metadata files are available, a query engine such as AWS Athena can consume it.

Apache Kafka provides separation of concerns between the two stages of the pipeline. Each component may be paused or restarted without affecting the other stage.
Configuration and instructions to install the CDC Pipeline is available in the cdc-examples Github repository.
Change Data Capture Example
There are two modes when writing data to Amazon S3:
- Trace Inserts, Updates, and Deletes: This mode is state of the art with formats like CSV, JSON, Apache Parquet, and Apache ORC. In this mode, the metadata and data of the operation are written to the data files. The user has to process the files and use the metadata to recreate the state of the database.
- Replay Inserts, Updates, and Deletes: This mode is available only with table formats such as Apache Iceberg. Transactions are applied atomically in the destination table. Since YugabyteDB is a distributed database, it provides primary key-level ordering of transactions which is sufficient for most OLAP databases.
Let us execute the following statements to check the data in Apache Iceberg tables.
# 1. Insert 10 rows into host table INSERT INTO host SELECT id, 'host_' || id::TEXT AS name, random_json(ARRAY['building','rack'],1,20) AS LOCATION FROM generate_series(1001,1010) AS id; # 2. Update one of the hosts UPDATE host SET host_name=’host_1002_arm’ WHERE id=1002; #3 Delete a row DELETE FROM HOST where id = 1003;
Comparison of Trace and Replay Modes
Insert 10 rows into host table
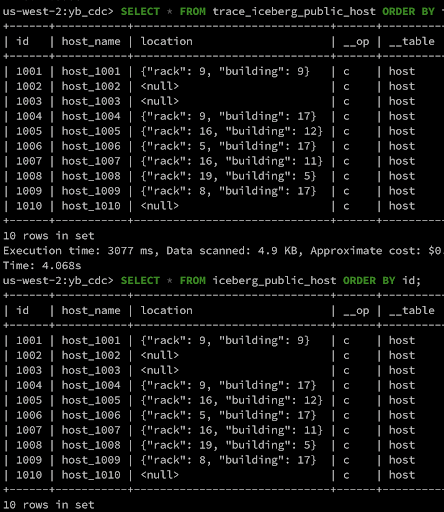
In both modes, inserted rows are similar.
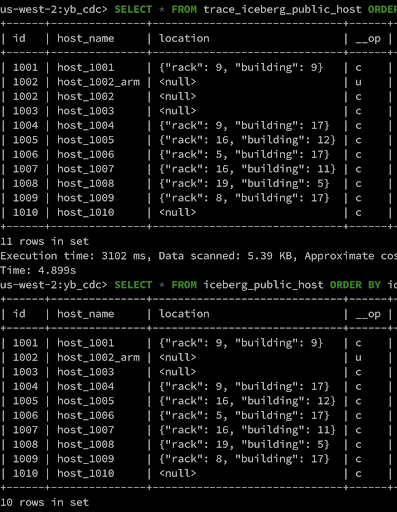
Update a Row
In Replay mode, the row is updated with the new value while in Trace mode a new row is added to the table with __op=’u’.
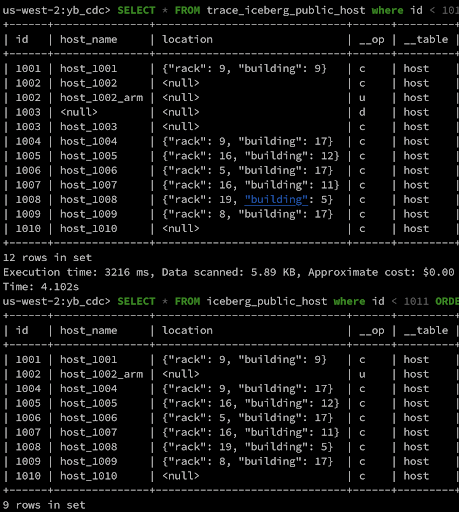
Delete a Row
In Replay mode, the row is updated with the new value while in Trace mode a new row is added to the table with __op=’d’.
Wrapping Up
Change Data Capture events from an OLTP database along with transactional table formats are required by data engineering teams to maintain an updated, single copy of your YugabyteDB database in Amazon S3 for archival and analytics purposes.
Learn more about YugabyteDB Change Data Capture (CDC) and YugabyteDB CDC Examples to set up a similar CDC pipeline to AWS S3.
To discover more, explore our recent related articles:
Snowflake CDC: Publishing Data Using Amazon S3 and Yugabyte db
Data Streaming Using YugabyteDB CDC, Kafka, and SnowflakeSinkConnector | Yugabyte
Unlocking Azure Storage Options With YugabyteDB CDC | Yugabyte


