How Data Sharding Works in a Distributed SQL Database
June 6, 2019
Enterprises of all sizes are embracing rapid modernization of user-facing applications as part of their broader digital transformation strategy. The relational database (RDBMS) infrastructure that such applications rely on suddenly needs to support much larger data sizes and transaction volumes. However, a monolithic RDBMS tends to quickly get overloaded in such scenarios. One of the most common architectural patterns used to scale an RDBMS is to “shard” the data. In this blog, we will learn what data sharding is and how it can be used to scale a SQL database. We will also review the pros and cons of common sharding architectures, plus explore how sharding is implemented in a distributed SQL database like YugabyteDB.
YugabyteDB also uses one process per connection, mirroring PostgreSQL’s protocol and query layer. This isn’t typically a scalability problem as connections can be spread across nodes. With YugabyteDB, all nodes are equal, accepting connections with read and write transactions. Ongoing work to add a database resident connection pool—based on Odyssey—aims to address applications without client-side connection pools and microservices with too many connection pools.
What Is Data Sharding?
Sharding is the process of breaking up large tables into smaller chunks called shards that are spread across multiple servers. A shard is essentially a horizontal data partition that contains a subset of the total data set, and hence is responsible for serving a portion of the overall workload. The idea is to distribute data that can’t fit on a single node onto a cluster of database nodes. Sharding is also referred to as horizontal partitioning. The distinction between horizontal and vertical comes from the traditional tabular view of a database. A database can be split vertically — storing different table columns in a separate database, or horizontally — storing rows of the same table in multiple database nodes.
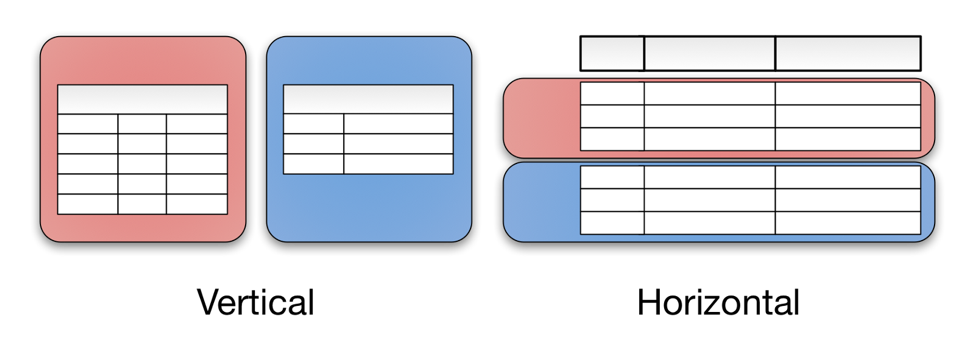
Figure 1 : Vertical and Horizontal Data Partitioning (Source: Medium)
Why Shard a Database?
Business applications that rely on a monolithic RDBMS hit bottlenecks as they grow. With limited CPU, storage capacity, and memory, query throughput and response times are bound to suffer. When it comes to adding resources to support database operations, vertical scaling (aka scaling up) has its own set of limits and eventually reaches a point of diminishing returns.
On the other hand, horizontally partitioning a table means more compute capacity to serve incoming queries, and therefore you end up with faster query response times and index builds. By continuously balancing the load and data set over additional nodes, sharding also enables usage of additional capacity. Moreover, a network of smaller, cheaper servers may be more cost effective in the long term than maintaining one big server.
Besides resolving scaling challenges, sharding can potentially alleviate the impact of unplanned outages. During downtime, all the data in an unsharded database is inaccessible, which can be disruptive or downright disastrous. When done right, sharding can ensure high availability: even if one or two nodes hosting a few shards are down, the rest of the database is still available for read/write operations as long as the other nodes (hosting the remaining shards) run in different failure domains. Overall, sharding can increase total cluster storage capacity, speed up processing, and offer higher availability at a lower cost than vertical scaling.
The Perils of Manual Sharding
Sharding, including the day-1 shard creation and day-2 shard rebalancing, when completely automated can be a boon to high-volume data applications. Unfortunately, monolithic databases like Oracle, PostgreSQL, MySQL, and even newer distributed SQL databases like Amazon Aurora do not support automatic sharding. This means manual sharding at the application layer has to be performed if you want to continue to use these databases. The net result is a massive increase in development complexity. Your application now has additional sharding logic to know exactly how your data is distributed, and how to fetch it. You also have to decide what sharding approach to adopt, how many shards to create, and how many nodes to use. And also account for shard key as well as even sharding approach changes if your business needs change.
One of the most significant challenges with manual sharding is uneven shard allocation. Disproportionate distribution of data could cause shards to become unbalanced, with some overloaded while others remain relatively empty. It’s best to avoid accruing too much data on a shard, because a hotspot can lead to slowdowns and server crashes. This problem could also arise from a small shard set, which forces data to be spread across too few shards. This is acceptable in development and testing environments, but not in production. Uneven data distribution, hotspots, and storing data on too few shards can all cause shard and server resource exhaustion.
Finally, manual sharding can complicate operational processes. Backups will now have to be performed for multiple servers. Data migration and schema changes must be carefully coordinated to ensure all shards have the same schema copy. Without sufficient optimization, database joins across multiple servers could highly inefficient and difficult to perform.
Common Auto-Sharding Architectures
Sharding has been around for a long time, and over the years different sharding architectures and implementations have been used to build large scale systems. In this section, we will go over the three most common ones.
Hash Sharding
Hash sharding takes a shard key’s value and generates a hash value from it. The hash value is then used to determine in which shard the data should reside. With a uniform hashing algorithm such as ketama, the hash function can evenly distribute data across servers, reducing the risk of hotspots. With this approach, data with close shard keys are unlikely to be placed on the same shard. This architecture is thus great for targeted data operations.
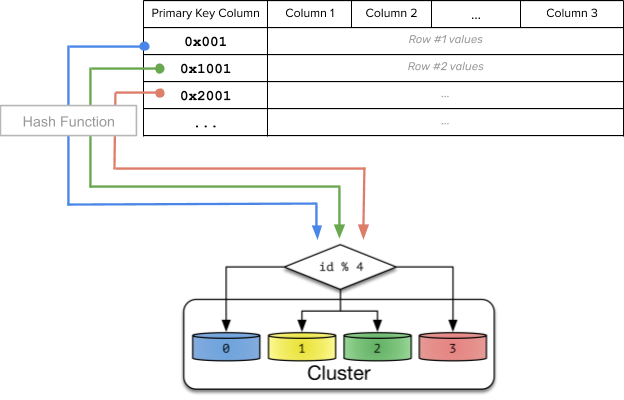
Figure 2: Hash sharding
Range Sharding
Range sharding divides data based on ranges of the data value (aka the keyspace). Shard keys with nearby values are more likely to fall into the same range and onto the same shards. Each shard essentially preserves the same schema from the original database. Sharding becomes as easy as identifying the data’s appropriate range and placing it on the corresponding shard.
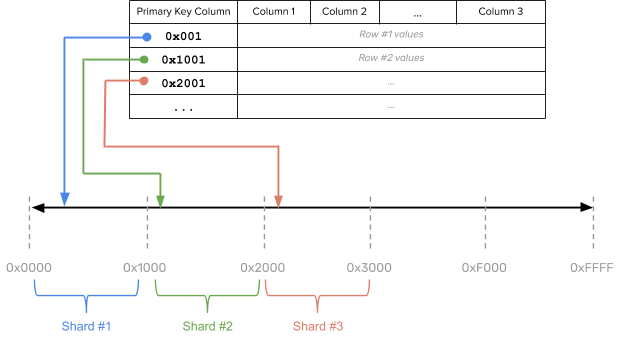
Figure 3 : Range sharding
Range sharding allows for efficient queries that reads target data within a contiguous range or range queries. However, range sharding needs the user to apriori choose the shard keys, and poorly chosen shard keys could result in database hotspots.
A good rule-of-thumb is to pick shard keys that have large cardinality, low recurring frequency, and that do not increase, or decrease, monotonically. Without proper shard key selections, data could be unevenly distributed across shards, and specific data could be queried more compared to the others, creating potential system bottlenecks in the shards that get a heavier workload.
The ideal solution to uneven shard sizes is to perform automatic shard splitting and merging. If the shard becomes too big or hosts a frequently accessed row, then breaking the shard into multiple shards and then rebalancing them across all the available nodes leads to better performance. Similarly, the opposite process can be undertaken when there are too many small shards.
Geo-Partitioning
In geo-based (aka location-aware) sharding, data is first partitioned according to a user-specified column that maps range shards to specific regions and the nodes in those regions. Inside a given region, data is then sharded using either hash or range sharding. For example, a cluster that runs across 3 regions in the US, UK, and the EU can rely on the Country_Code column of the User table to map the user’s row to the nearest region that is in conformance with GDPR rules.
Sharding in YugabyteDB
YugabyteDB is an auto-sharded, ultra-resilient, high-performance, geo-distributed SQL database built with inspiration from Google Spanner. It currently supports hash and range sharding. Geo-partitioning is an active work-in-progress feature. Each data shard is called a tablet, and it resides on a corresponding tablet server.
Read Yugabyte blog “Four Data Sharding Strategies We Analyzed in Building a Distributed SQL Database”
Hash Sharding
For hash sharding, tables are allocated a hash space between 0x0000 to 0xFFFF (the 2-byte range), accommodating as many as 64K tablets in very large data sets or cluster sizes. Consider a table with 16 tablets as shown in Figure 4. We take the overall hash space [0x0000 to 0xFFFF), and divide it into 16 segments — one for each tablet.
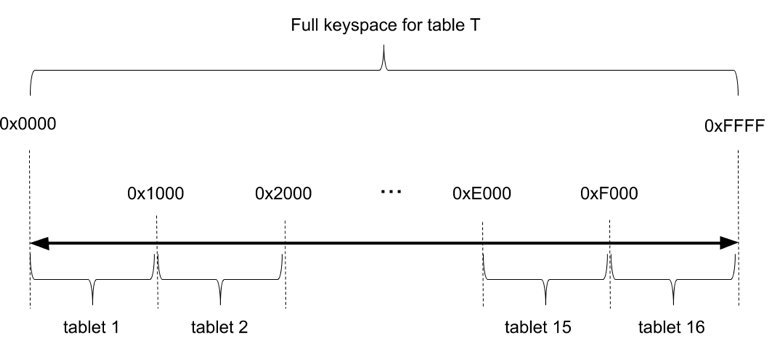
Figure 4: Hash sharding in YugabyteDB
In read/write operations, the primary keys are first converted into internal keys and their corresponding hash values. The operation is served by collecting data from the appropriate tablets. (Figure 3)
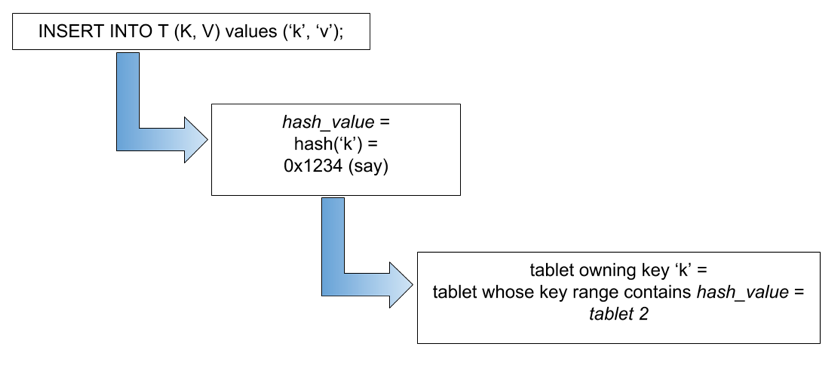
Figure 5: Figuring out which tablet to use in YugabyteDB
As an example, suppose you want to insert a key k, with a value v into a table as shown in Figure 6, the hash value of k is computed, and then the corresponding tablet is looked up, followed by the relevant tablet server. The request is then sent directly to that tablet server for processing.
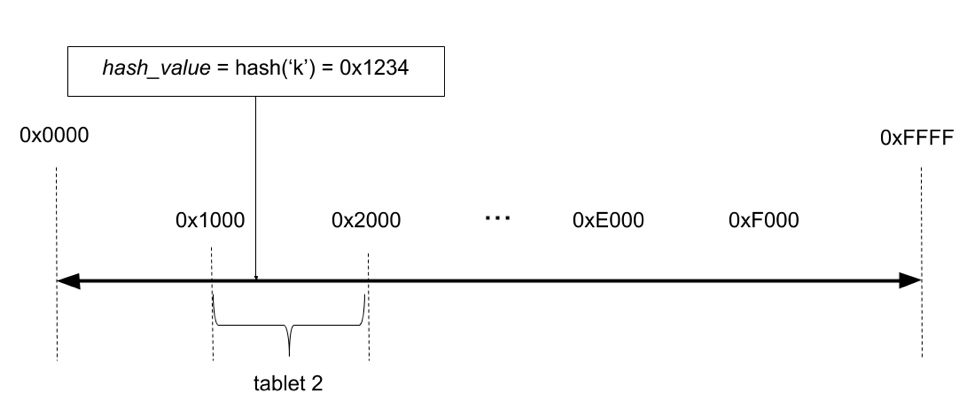
Figure 6 : Storing value of k in YugabyteDB
Range Sharding
SQL tables can be created with ASC and DESC directives for the first column of a primary key as well as first of the indexed columns. This will lead to the data getting stored in the chosen order on a single tablet. This single tablet can be either split automatically (once it reaches certain size) or can be split manually whenever desired. For high performance workloads with well-known split points, the SPLIT AT clause can be added at table creation time to specify the exact ranges.
Geo-Partitioning
Row-level geo-partitioning is an active work in progress. Design documentation and current status are both available on GitHub.
Summary
Data sharding is a solution for business applications with large data sets and scale needs. There are a variety of sharding architectures to choose from, each of which provides different capabilities. Before settling on a sharding architecture, the needs and workload requirements of your application must be mapped out. Manual sharding should be avoided in most circumstances given significant increase in application logic complexity. YugabyteDB is an auto-sharded distributed SQL database with support for both hash and range sharding today. Support for geo-partitioning is coming soon. In this tutorial, you can see YugabyteDB’s automatic sharding in action.
Additional Data Sharding Resources
Distributed SQL Sharding: How Many Tablets, and at What Size?
Four Data Sharding Strategies We Analyzed in Building a Distributed SQL Database
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner, and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing, or to schedule a technical overview.
Editor’s note: This post was updated August 28, 2020 to include new sharding features available starting in YugabyteDB 2.2

 When Node Is Lost and Then Brought Back Into Cluster?")
