Navigating Database Concepts: Mapping YugabyteDB to PostgreSQL and MongoDB
February 28, 2019
Developing a distributed application or expanding an existing one with new microservices often requires data storage in a distributed database. However, selecting the right database can be challenging due to the numerous niche options available. Each database has its own unique terminology and nuances, making the learning process daunting. Luckily, YugabyteDB offers a solution by providing a new distributed SQL database with a familiar programming and architectural model, eliminating the complexities.
YugabyteDB is a fully open-source distributed SQL database designed for internet-scale, geo-distributed applications. It combines the best features of a SQL database, such as PostgreSQL-compatibility, ACID transactions, relational modeling with JOINS, secondary indexes, and schemas with the characteristics typically found in NoSQL systems. These include auto sharding, fault tolerance, low read latencies, and support for flexible schema designs using JSON documents.
If you are unfamiliar with the Yugabyte database, this blog post will help you grasp the key architectural concepts in YugabyteDB by drawing comparisons to PostgreSQL and MongoDB.
Concept 1: The Node
In production, YugabyteDB is deployed over a cluster of multiple machines that may be virtual, physical or containerized. Typically, the term node is used to refer to a single machine in the cluster.
So, what’s inside a YugabyteDB node? Let’s look at it from both the logical and physical perspectives. YugabyteDB has 2 logical layers – Yugabyte Query Layer and DocDB. The YQL layer includes the API specific aspects, for example, the SQL implementation, corresponding query/command compilation, and run-time components. And, DocDB is the distributed document store responsible for foundational aspects such as sharding, replication consistency, and other storage subsystems.

Logical Architecture of a YugabyteDB Node
From the physical aspect, YB-TServer (aka the YugabyteDB Tablet Server) is the main database process. It is responsible for serving application client queries as well as the automatic sharding, replication, transactions management tasks.
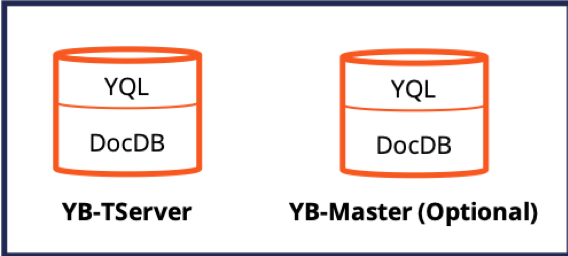
Physical Architecture of a YugabyteDB Node
Additionally, there is the YB-Master (aka the YugabyteDB Master Server) process that is responsible for storing system metadata (such as shard-to-node mappings) and coordinating system-wide operations, such as automatic load balancing, table creation, or schema changes. YB-Master does not come in the regular IO path used by application clients. Irrespective of the number of YB-TServers present in the system, there should be at least three YB-Master processes running across the system at any time for reliability.
Concept 2: The Cluster
A cluster is a logical group of nodes that run together. Clustering is used for high availability as well as for load balancing the application workload across several nodes. A cluster is expected to have a minimum of 3 nodes and can horizontally scale, as the workload demand grows, to as many nodes as required. A cluster can span multiple zones in a single region, multiple regions of a single cloud or multiple clouds to achieve global reach and scale.
In a YugabyteDB deployment, replication of data between cluster nodes can is by default setup as synchronous which guarantees strong consistency. Optionally, asynchronous replication which guarantees timeline consistency (with bounded staleness) can be configured in the context of read replicas. Note that YugabyteDB does not support any form of eventual consistency that’s common in traditional NoSQL databases. A synchronously replicated cluster is known as the Primary Cluster that can accept writes to the system. A primary cluster can become the source for an asynchronously replicated cluster known as a Read Replica. These read replicas allow the application to serve low latency reads in remote regions.
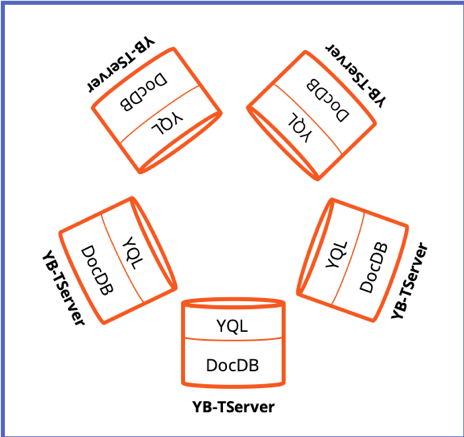
Logical Architecture of a YugabyteDB Cluster with 5 Nodes
As shown in the figure above, scaling a cluster simply involves increasing or decreasing the number of YB-TServers present in the cluster. Addition or removal of YB-TServers essentially leads to data shards (discussed in a later section) getting automatically re-balanced across the available YB-TServers. Note the above logical architecture also includes 3 YB-Masters not shown in the figure.
Concept 3: The Universe
A universe in YugabyteDB is comprised of one primary cluster and multiple optional read replica clusters. Each cluster is installed on a collection of nodes that may be located in one or more availability zones, regions or even multiple hybrid clouds.
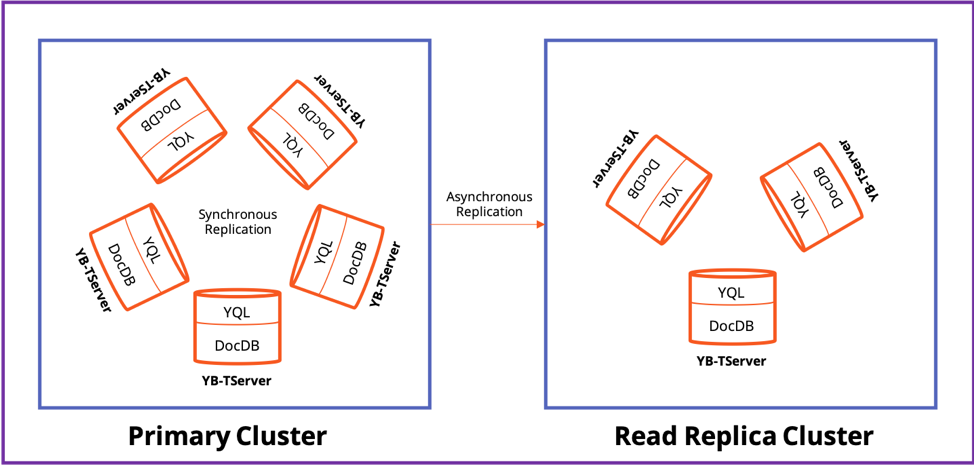
Logical Architecture of a YugabyteDB Universe
Together, the clusters function as a single logical, highly resilient, global-scale database known as a Universe.
Concept 4: From SQL Tables to Tablets and Nodes
Applications can manage data in YugabyteDB using either the fully relational Yugabyte SQL (YSQL) API or the SQL-based flexible-schema Yugabyte Cloud QL (YCQL) API.
- The YSQL API is best fit for RDBMS workloads that need scale-out and global distribution while also needing fully relational SQL features like JOINs, referential integrity, and multi-table transactions.
- The YCQL API is best fit for internet-scale OLTP apps that want a semi-relational distributed SQL that’s highly optimized for write-intensive applications as well as blazing fast query needs.
Similar to most distributed databases, table data in YugabyteDB is split into multiple chunks or shards and spread over multiple nodes. These shards are called tablets in DocDB, YugabyteDB’s distributed document store. Initial sharding and ongoing shard rebalancing across nodes is completely automatic in DocDB.
Data sharding in DocDB happens with the help of a hashing function over the partitioning columns in the primary key. In addition, the primary key can also contain additional range-based/clustered columns that help co-locate related data in a given partition in a sorted manner. In addition to hash-based partitioning, which uniformly distributes the workload across multiple nodes, DocDB plans to support range-based data partitioning that will useful for cases where querying of ordered records might be needed.
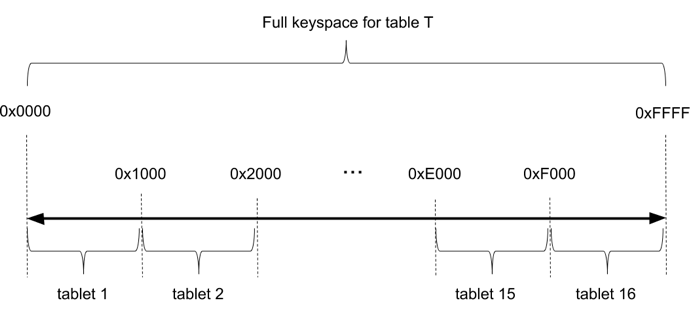
When a data read or write occurs, the partition columns of the primary key are hashed, and the request is routed to the correct tablet server that hosts the tablet.
Concept 5: Replication and Storage
Depending on the replication factor, tablets are replicated and have tablet-peers. For example, as shown in the figure below, Tablet 16 has 3 peers, and each peer is placed on a separate node for high availability in case one of the nodes goes offline.
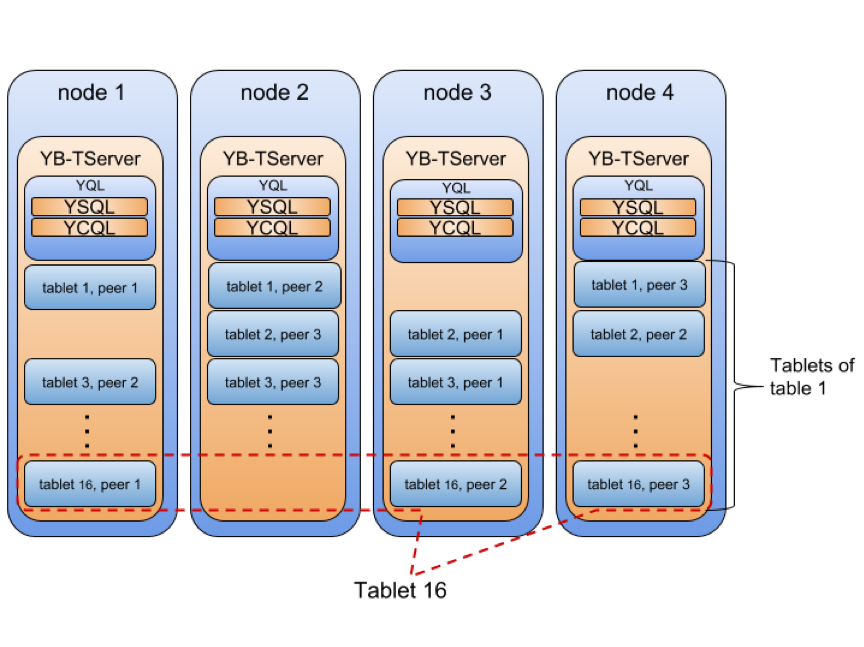
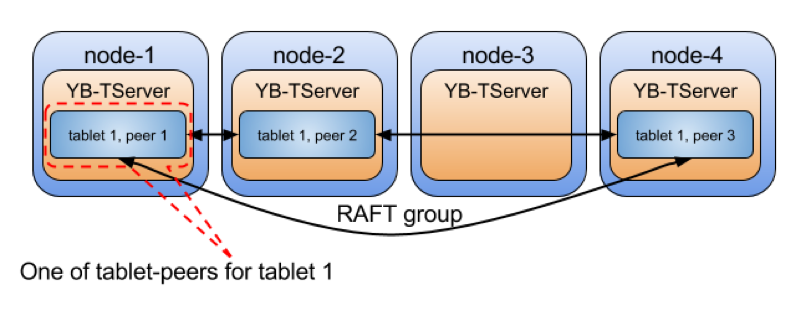
In the world of distributed systems, Raft has become the de-facto consensus replication algorithm when it comes to building resilient, strongly consistent systems. DocDB uses the Raft protocol for tablet leader election as well as data replication between tablet peers. Every tablet and its peers form a Raft group in YugabyteDB as shown in the figure below. “How Does the Raft Consensus-Based Replication Protocol Work in YugabyteDB?” describes the various benefits derived in such a replication architecture.
Once data is replicated via Raft across quorum of tablet-peers, DocDB applies the change to the local storage engine on that node. This local storage engine is a highly customized version of RocksDB, a widely popular embeddable fast key-value storage engine. To learn more about how DocDB leverages RocksDB, check out “How We Built a High Performance Document Store on RocksDB.”
Mapping Core Concepts to PostgreSQL & MongoDB
Now that we have reviewed the major YugabyteDB concepts, let’s quickly look at how these concepts map to PostgreSQL and MongoDB.
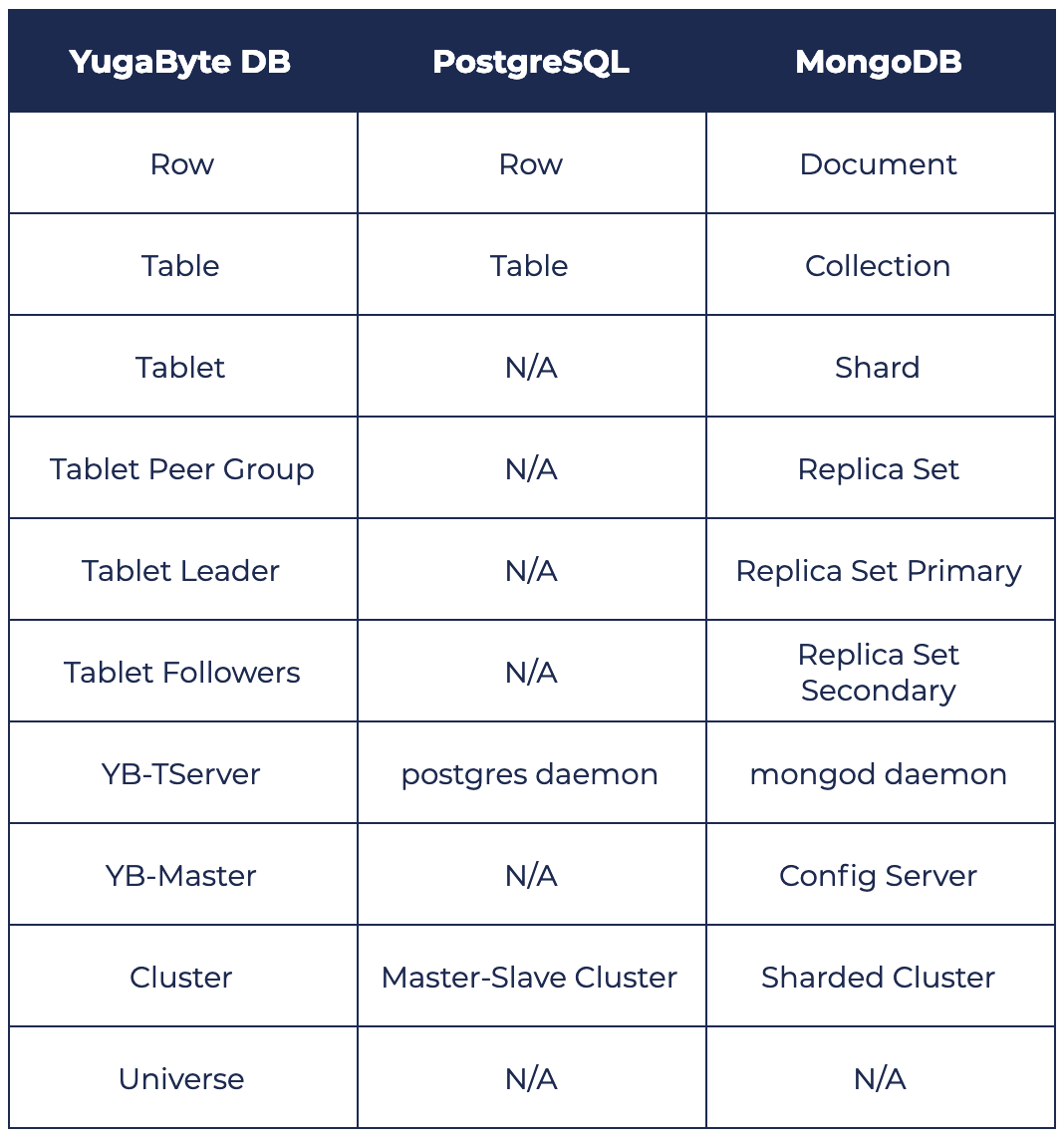
PostgreSQL vs. YugabyteDB
PostgreSQL is a single node relational database (aka RDBMS). Tables are not partitioned/sharded into smaller components since all data is served from a single node anyway. On the other hand, YugabyteDB is an auto-sharded distributed database where shards are automatically placed on different nodes altogether. The benefit is that no single node can become the performance or availability bottleneck while serving data across different shards. This concept is key to how YugabyteDB achieves horizontal write scalability that native PostgreSQL lacks. Additional nodes lead to the shards getting rebalanced across all the nodes so that the additional compute capacity can be more thoroughly utilized.
There is a concept of “partitioned tables” in PostgreSQL that can make horizontal data partitioning/sharding confusing to PostgreSQL developers. First introduced in PostgreSQL 10, partitioned tables enable a single table to be broken into multiple child tables so that these child tables can be stored on separate disks (tablespaces). Serving of the data however is still performed by a single node. Hence this approach does not offer any of the benefits of an auto-sharded distributed database such as YugabyteDB.
MongoDB vs. YugabyteDB
As detailed in “Overcoming MongoDB Sharding and Replication Limitations with YugabyteDB”, MongoDB by default operates in the context of a single shard. A single shard can be made highly available using a Replica Set, a group of mongod processes that maintain the same data set. This group has 1 primary member and 2 secondary members. Given the single write node limitation in both MongoDB Replica Set and PostgreSQL, they face the same horizontal scalability challenge.
If data volume grows beyond what can be handled by a single shard running on a single node, then the Replica Set has to be converted into a Sharded Cluster where multiple Replica Sets can be managed as a more unified unit. This conversion also comes with the addition of MongoDB Config Servers as the metadata store and cluster coordinator. In contrast, YugabyteDB functions in a fully sharded mode by default and hence can be horizontally scaled to large number of nodes much more easily than MongoDB. Note that a single YB-TServer manages multiple shards (aka tablets) where as a single mongod daemon is responsible for only one shard. This leads to significantly better CPU and memory utilization in YugabyteDB compared to MongoDB especially for the common case of uneven traffic distribution across shards.
Summary
As a single-node RDBMS, PostgreSQL is a strong contender for powering small-scale, business-critical apps. However, when the rigidity of relational schema modeling and/or the lack of automatic failover becomes a concern, developers tend to gravitate toward MongoDB. MongoDB works fine in the context of a single replica set as long as horizontal write scalability with low read latency is not the top priority. If that becomes a priority then developers have no choice but to look for an alternative. As a PostgreSQL-compatible high-performance distributed SQL database, YugabyteDB is that alternative.
What’s Next?
- Check out our next post of this series, where we deep dive into the high availability and ACID transactions architecture of the three databases.
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


