How to Build Applications with YugabyteDB and Apache Spark
October 19, 2021
At Distributed SQL Summit 2021, we presented a workshop on how to build an application using the YugabyteDB Spark Connector and YugabyteDB to deliver business outcomes for our customers.
The YugabyteDB Spark Connector brings together the best of breed technologies Apache Spark — an industry-leading, distributed computing engine — with YugabyteDB, a modern, cloud-native distributed SQL database. This connector allows customers to seamlessly and natively read from, perform complex ETL, and write to YugabyteDB.
This native integration removes all the complexity and guesswork in deciding what processing should happen where. With the optimized connector, the complex workloads processed by Spark can be translated to SQL and executed by YugabyteDB directly, making the application much more scalable and performant.
In this blog post, we recap some highlights from the workshop, and show you how to get started with your first application.
Workshop recording and slides
You can check out the complete tutorial by accessing the workshop recording and slides.
Brief introduction to YugabyteDB and YugabyteDB Managed
Cloud native enterprise applications in the multi-cloud world demand a highly scalable, resilient, horizontally scalable, geographically distributed, and cloud agnostic modern database. YugabyteDB meets these challenges and is the database of choice for organizations building microservices and born-in-the-cloud apps. In addition, YugabyteDB provides multiple APIs by converging SQL and NoSQL, which simplifies the polyglot data architecture needs of the enterprise.
YugabyteDB Managed is a fully-managed offering of YugabyteDB and unlocks the power of “any.” Organizations can run any app at any scale, anywhere, accessible at any time and running in any cloud, a perfect addition to a multi-cloud world.
Getting started with the YugabyteDB Spark Connector
The latest version of the YugabyteDB Spark Connector is Spark 3.0 compatible and allows you to expose YugabyteDB tables as Spark RDDs, write Spark RDDs to Yugabyte tables, and execute arbitrary CQL queries in your Spark applications. Key features of the YugabyteDB Spark Connector include:
- Read from YugabyteDB: Exposes YugabyteDB tables as Spark RDDs
- Write to YugabyteDB: Save RDDs back to Cassandra by implicit saveToCassandra calls
- Native JSON data support using JSONB data type, where Cassanda lacks the native support
- Supports PySpark DataFrames
- Performance optimizations with predicate pushdowns
- Cluster, topology and partition awareness
Understanding the application architecture
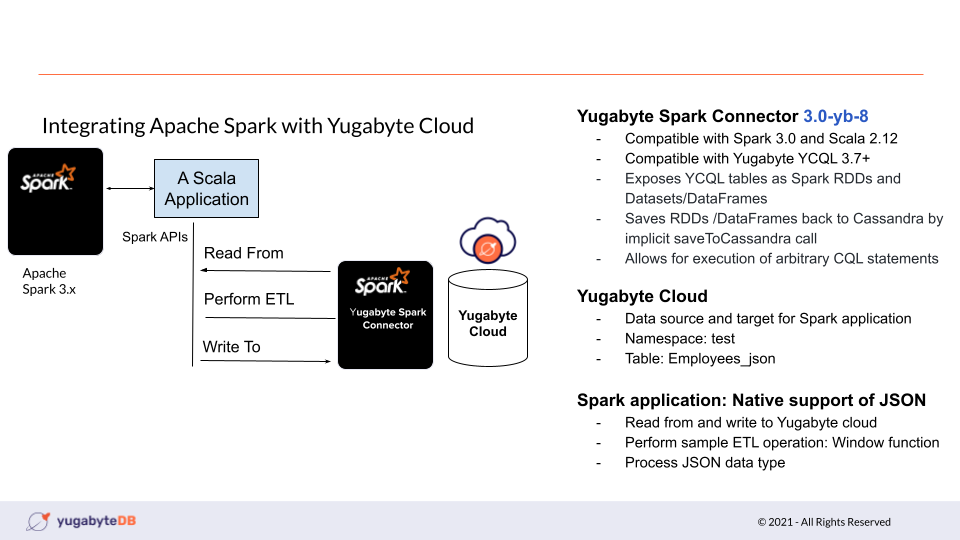
As seen in the diagram, we are building a Scala application using YugabyteDB Spark Connector to demonstrate:
- How Spark integrates with Yugabyte Cloud to develop applications
- How YugabyteDB models JSON data efficiently using a JSONB data type
- Key features of the connector
Prerequisites
Before you get started, you’ll need to have the following software installed on your machine:
- Java JDK 1.8
- Spark 3.0 and Scala 2.12
wget https://dlcdn.apache.org/spark/spark-3.0.3/spark-3.0.3-bin-hadoop2.7.tgz tar xvf spark-3.0.3-bin-hadoop2.7.tgz cd spark-3.0.3-bin-hadoop2.7 ./bin/spark-shell --conf spark.cassandra.connection.host=127.0.0.1 --conf spark.sql.extensions=com.datastax.spark.connector.CassandraSparkExtensions --packages com.yugabyte.spark:spark-cassandra-connector_2.12:3.0-yb-8
- YugabyteDB access: Create a YugabyteDB cluster in YugabyteDB Managed and follow the instructions to configure and connect to the cluster, as well as create database objects using the script namespace.sql
./bin/ycqlsh -h your_cluster_ip -f namepspace.sql //a DDL example with jsonb data type Create keyspace test; Create table test.employeess_json (department_id INT, employee_id INT,dept_name TEXT, salary Double, phone jsonb, PRIMARY KEY(department_id, employee_id));
Steps for building your first application
1. Import the libraries required to build the application:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql.CassandraConnectorConf
import org.apache.spark.sql.functions._
import org.apache.spark.sql.expressions.Window
import com.datastax.spark.connector.cql.CassandraConnector2. Configure YugabyteDB connectivity:
val host = "748fdee2-aabe-4d75-a698-a6514e0b19ff.aws.ybdb.io" val user = "admin" val password = "your password for admin" val keyStore ="/Users/xxx/Documents/spark3yb/yb-keystore.jks"
3. Now create a Spark session and connect to YugabyteDB Managed:
val conf = new SparkConf()
.setAppName("yb.spark-jsonb")
.setMaster("local[1]")
.set("spark.cassandra.connection.localDC", "us-east-2")
.set("spark.cassandra.connection.host", "127.0.0.1")
.set("spark.sql.catalog.ybcatalog",
"com.datastax.spark.connector.datasource.CassandraCatalog")
.set("spark.sql.extensions",
"com.datastax.spark.connector.CassandraSparkExtensions")
val spark = SparkSession.builder()
.config(conf)
.config("spark.cassandra.connection.host", host)
.config("spark.cassandra.connection.port", "9042")
.config("spark.cassandra.connection.ssl.clientAuth.enabled", true)
.config("spark.cassandra.auth.username", user)
.config("spark.cassandra.auth.password", password)
.config("spark.cassandra.connection.ssl.enabled", true)
.config("spark.cassandra.connection.ssl.trustStore.type", "jks")
.config("spark.cassandra.connection.ssl.trustStore.path", keyStore)
.config("spark.cassandra.connection.ssl.trustStore.password", "ybcloud")
.withExtensions(new CassandraSparkExtensions)
.getOrCreate()4. Process the data by reading from YugabyteDB, performing an ETL-window function specifically in Spark and saving the result back to YugabyteDB:
//Read data into a data frame from a YB table
val df_yb = spark.read.table("ybcatalog.test.employees_json")
//Perform window function
val windowSpec = Window.partitionBy("department_id").orderBy("salary")
df_yb.withColumn("row_number",row_number.over(windowSpec)).show(false)
df_yb.withColumn("rank",rank().over(windowSpec)).show(false)
//Write back to a YB table
df_yb.write.cassandraFormat("employees_json_copy", "test").mode("append").save()5. Now query the data in YugabyteDB:
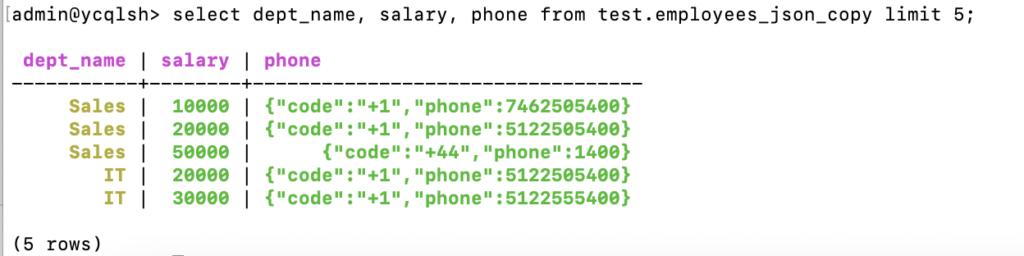
YugabyteDB models JSON data in a JSONB data type efficiently. The connector optimizes the query performance with column pruning and predicate pushdown:
//Column Pruning Val query1 = "SELECT department_id, employee_id, get_json_object(phone,'$.code') as code FROM ybcatalog.test.employees_json WHERE get_json_string(phone, '$.key(1)') = '1400' order by department_id limit 2"; val df_sel1=spark.sql(query1) df_sel1.explain //Predicate pushdown val query2 = "SELECT department_id, employee_id, get_json_object(phone, '$.key[1].m[2].b') as key FROM ybcatalog.test.employees_json WHERE get_json_string(phone, '$.key[1].m[2].b') = '400' order by department_id limit 2"; val df_sel2 = spark.sql(query2) df_sel2.show(false) //verify with the explain plan from YB df_sel2.explain
Conclusion
YugabyteDB is an excellent choice of distributed SQL database for storing critical business information such as system of records and product catalogs. Spark provides all the capabilities you need to perform complex computations on this data by leveraging the YugabyteDB Spark Connector.
Next steps
Interested in learning more about YugabyteDB Spark Connector? Download it here to get started!
The code for the application we just walked through can be found on GitHub. You can also sign up for YugabyteDB Managed, a fully managed YugabyteDB-as-a-service.

")
