YugabyteDB: Reimagining the RDBMS for the Cloud
February 25, 2021
Perspectives from 5 years of building a cloud native database
YugabyteDB just turned 5 years old, and I cannot help but reminisce about our journey in building this database over the last half-decade. I vividly remember the genesis of the YugabyteDB project, which started with Kannan, Mikhail, and myself meeting for lunch at a restaurant to discuss the future of cloud native databases. After iterating on the idea over a number of such discussions, we ended up kicking off the YugabyteDB project on Feb 4, 2016. This blog post is a brief recounting of the technical journey that led to creating YugabyteDB, and the exciting things still to come.
Our Facebook experience
Kannan, Mikhail, and I worked as a part of the same infrastructure team at Facebook from 2007 – 2013, when there was an explosive growth in the number of monthly active users from 58 million to over 1 billion.
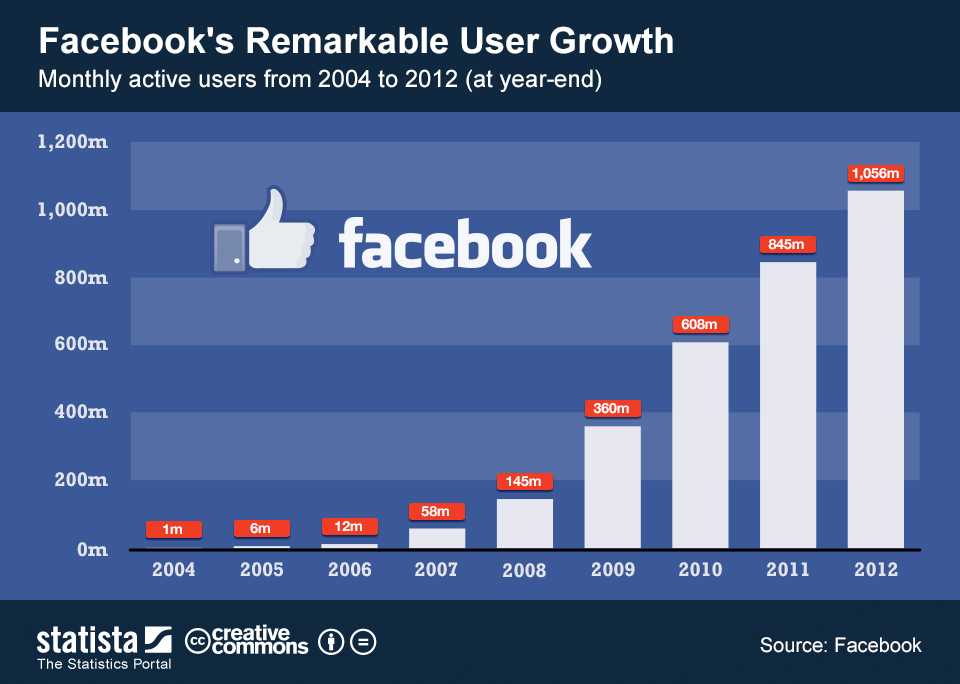
Back in 2007, the term NoSQL had not yet been coined. At the time, the only highly available and horizontally scalable database was Google’s Bigtable, which was a proprietary service. Open source data infrastructure projects had not taken off in a big way yet, and the concept of a public cloud was not something most people had heard of yet.
Our work at Facebook involved building scalable OLTP databases such as Apache Cassandra and Apache HBase, as well as operating them in production at a massive scale. Our daily struggle was trying to figure out how to scale the database tier with the growth in both the number of active users and the number of services that were rapidly being launched.
Why the world needed a new database
Our Facebook experience taught us a great deal about the evolution of cloud native services over a period of time, and the features they would in turn demand from a cloud native database. Some of the critical features of a cloud native database are listed below.
- Support for transactions and indexes: This is something that we had overlooked when building the original NoSQL databases such as Apache Cassandra and Apache HBase. We had many, many developers request the ability to lookup data efficiently using secondary indexes, as well as the ability to perform transactional updates. However, it would be a band-aid approach to simply bolt on these features to the NoSQL databases without redesigning the core architecture.
- High availability and resilience: New applications being developed require that the databases they depend on are always available, and do not incur any downtime. Thus, a cloud native database should not only be able to tolerate unplanned outages but also planned maintenance activities such as rolling software upgrades and security patches.
- Horizontally scalability: Some applications tend to become extremely popular in a short period of time, thereby requiring near instantaneous scalability from the database. It is not really an option to take downtime or move the data to a different machine in order to scale these databases. Thus, horizontal scalability is a must, and furthermore reliably scaling out the database cluster to accommodate these growing workloads was critical.
- High performance: When using a distributed database, the ability to directly serve traffic from it without requiring a caching layer is very handy, as this can simplify deployments dramatically. Introducing a separate caching tier to mask database performance issues pushes complexity to the development team to deal with (example: cache consistency issues) and to the operations team to manage two layers of infrastructure (example: operational runbooks, security, etc.).
- Operational simplicity: It must be possible to perform most maintenance tasks without disrupting the applications using the database. For example: decommissioning machines that are faulty to subsequently replace them. Another common example was replacing all the machines in a cluster with a new set of machines. This could be required because an entire data center is being retired or a newer machine SKU is being adopted.
- Geographic distribution of data: In order to ensure high availability and a good end user experience, it becomes essential to replicate data across multiple zones and regions. This often involves a combination of synchronous and asynchronous replication of data so as to cater to a wide variety of microservices.
An analysis of the various databases available at the time led us to conclude that there was a need for a new cloud native database that could offer the above features.
Why the world did not need a new database
We talked to many potential users to get their feedback about our hypothesis that the world needs a new cloud native database. The feedback was nearly unanimous – no one wanted to learn the nuances of a new database API, even if it offered the “so-called” ANSI-SQL compatibility on the surface – they really wanted something that was essentially drop in compatible both with an existing database both in terms of language-level features but also in terms of the client-drivers, SDKs, and tools used to interact with the database. The underlying issue was that this often required a specialized team of developers and another dedicated ops team in order to really leverage each database, and no one really wanted to invest this time and effort given there are many databases already in use.
However, everyone loved the idea of a new cloud native database with well-known APIs. The API and language-feature compatibility of a new database was especially important from an ecosystem perspective as well, because it would enable developers to use familiar tools and frameworks. At this juncture, we made the decision not to build a new API for this new database, we would reuse existing APIs instead.
Building YugabyteDB
At this juncture, we started designing and building the database from ground up. We had to make many important decisions, some of which are described below.
Picking the right SQL API – PostgreSQL
The first exercise was deciding on which APIs to pick. The logical choice was SQL, and we wanted to standardize on a SQL RDBMS that was widely adopted. We also wanted it to be open source and have a mature ecosystem around the database. The natural choices to weigh were PostgreSQL and MySQL. We chose PostgreSQL for the following reasons:
- PostgreSQL has a more permissive license which is more inline with the 100% open source ethos of YugabyteDB.
- And it definitely did not hurt that the popularity of PostgreSQL in the last few years has been skyrocketing compared to any other SQL database!
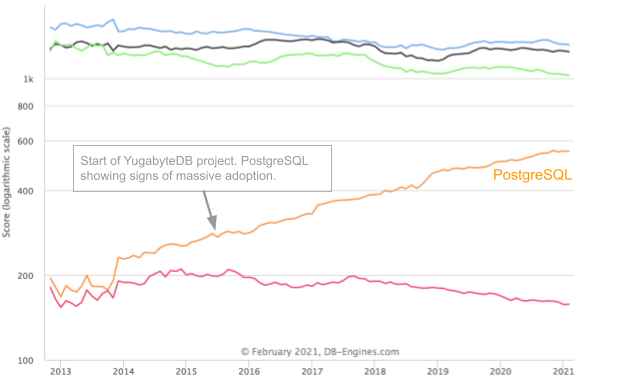
The image above is a trend graph of the five SQL databases currently in the top 10 of DB-Engines ranking site. Only PostgreSQL has been growing in popularity since 2014, while the others have flatlined or are losing mindshare. For many applications, PostgreSQL is an excellent alternative to Oracle. Organizations are being drawn to PostgreSQL because it is open source, vendor neutral (MySQL is owned by Oracle), has an engaged community of developers, a thriving ecosystem of vendors, a robust feature set, and a mature code base that has been battle-hardened with over 20 years of rigorous use.
Converging SQL and NoSQL – one database, multiple APIs
When we talked to our community of users about picking SQL as the API, we got feedback from developers who loved NoSQL, including the features they absolutely needed from the NoSQL databases, some of which are discussed below.
- Usable as a low-latency serving tier: NoSQL databases can sometimes be used directly to serve queries without always requiring a cache, primarily because they achieve low latencies while being highly available and scalable on demand.
- No need for load balancers: Most developers loved the fact that the NoSQL languages were built to operate on a cluster of nodes, as opposed to SQL where an external load balancer needs to be managed to route queries across multiple nodes. In most NoSQL databases, the client drivers transparently learn the cluster membership when new nodes are added, existing nodes are removed, etc.
- Replication and geo-distribution are built into the database: Replication is an inherent part of NoSQL databases. These DBs offer powerful features such as the ability to query data from the nearest geographic region and stretch a cluster across regions using synchronous or asynchronous replication.
- Automatic data expiry: In many use cases, data needs to be automatically expired in a certain time period after it is inserted (say in 90 days). This is accomplished through a time to live (TTL) feature, which does not have an equivalent in RDBMS.
Augmenting the primary RDBMS with a NoSQL database for the above features introduces a lot of complexity when building applications, as well as a lot of operational pain points in production. Given our mission statement of “building the default operational database for cloud native applications,” we felt that we should cater to the features listed above as well. Hence, we made the decision to build an extensible query layer to support APIs from multiple existing databases.
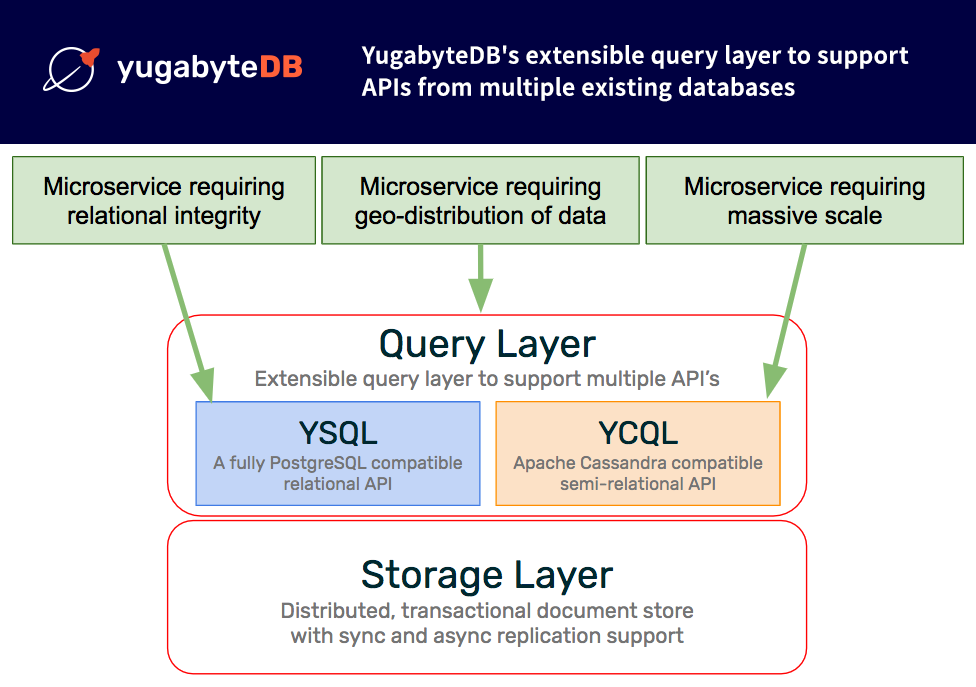
As shown in the figure above, this design can dramatically simplify the development of modern applications and microservices.
High availability and resilience
In terms of the CAP theorem, YugabyteDB is a CP database (consistent and partition tolerant), but achieves very high availability. The architectural design of YugabyteDB is similar to Google Cloud Spanner, which is also a CP system. The description about Spanner is equally valid for YugabyteDB. The key takeaway is that no system provides 100% availability, so the pragmatic question is whether or not the system delivers availability that is so high that most users no longer have to be concerned about outages. For example, given there are many sources of outages for an application, if YugabyteDB is an insignificant contributor to application downtime, then users are correct to not worry about it.
High availability in YugabyteDB is achieved by having active replicas that are ready to take over as a new leader in a matter of seconds after the failure of the current leader and serving requests. In a multi-zone public cloud deployment, upon a node outage, the queries failover to other nodes in about 3 seconds with zero data loss. This is shown in the diagram below.
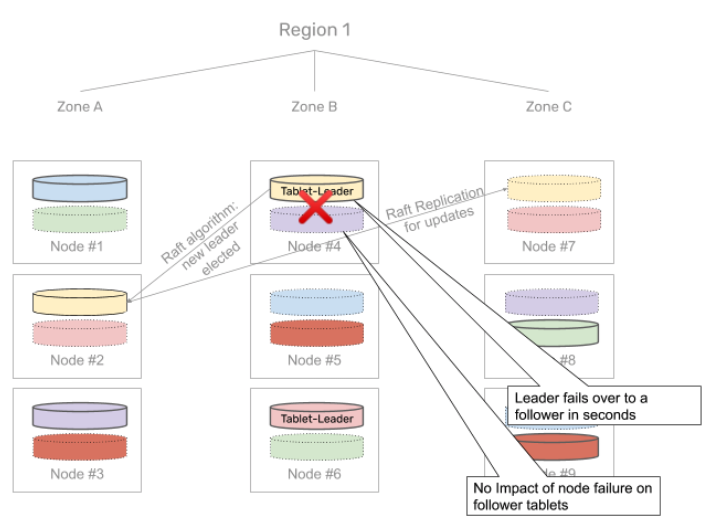
Additionally, on an extended node failure, YugabyteDB can self-heal by automatically re-replicating data hosted on the failed node to other nodes in the cluster. This ensures that business-critical applications and services can be highly available even if unexpected outages occur.
Scaling queries, data sets, and connections
The design of sharding, replication, and transactions in YugabyteDB is done to ensure that no single component of the database becomes a performance or availability bottleneck for geo-distributed, random access SQL-based OLTP workloads. Horizontal scalability is ensured by transparently sharding a table into many tablets. Each tablet contains a subset of rows and is replicated across the different nodes in a cluster.
Scaling a cluster out simply requires new nodes to be added to the cluster. This triggers an internal redistribution of some of the existing tablets to the newly added nodes, so that the queries are evenly distributed and the cluster is able to utilize all the nodes. The example of scaling out from a 3-node cluster to a 9-node one is shown below, where the replication factor of data in the cluster is 3. A query for any particular row is handled by the tablet it falls in, which in turn is processed and served by the node the tablet currently resides in. Since the tablet can dynamically move from one node to another, the queries get re-distributed transparently.
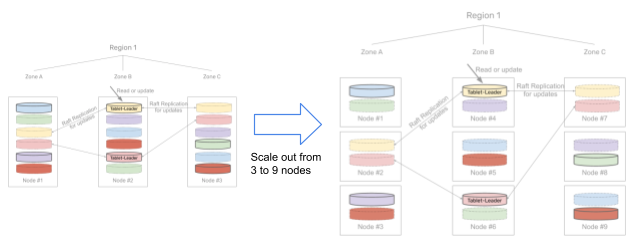
The capacity of a YugabyteDB cluster to handle concurrent requests, large data sets, and support many client connections is determined by the number of nodes in the cluster, which can be scaled on demand. Thus, making it is easy to scale the cluster based on the needs of the application.
Distributed transactions without atomic clocks
Transactions are a key building block for developing business-critical, user-facing applications and a fundamental requirement for any RDBMS. YugabyteDB supports fully distributed ACID transactions across rows, tablets, and nodes at any scale. ACID transactions in YugabyteDB are achieved using a distributed transaction management layer to coordinate the various operations being performed as a part of a transaction, and finally performing a commit or a rollback as needed.
Distributed transactions require clock synchronization. YugabyteDB uses Hybrid Logical Clocks (HLCs) to perform distributed time synchronization, to ensure that there is no single point of failure, plus it works well in multi-region deployments. HLCs solve the “time-synchronization problem” by combining physical time clocks that are coarsely synchronized using NTP with Lamport clocks that track causal relationships.

YugabyteDB supports the Serializable and Snapshot isolation levels. To this end, the transaction management layer in YugabyteDB transparently differentiates between single-row/single-shard transactions as opposed to transactions that update rows across tablets or nodes. The updates to a single row directly update the row without having to interact with the transaction status table using the single row transaction path, also called the fast path. A transaction that impacts a set of rows distributed across multiple tablets (which would be hosted on different nodes in the most general case) uses the distributed transactions path to execute transactions. Implementing distributed transactions in YugabyteDB requires the use of a transaction manager that can coordinate the various operations that are a part of the transaction and finally commit or abort the transaction as needed.
Supporting asynchronous replication in addition to synchronous
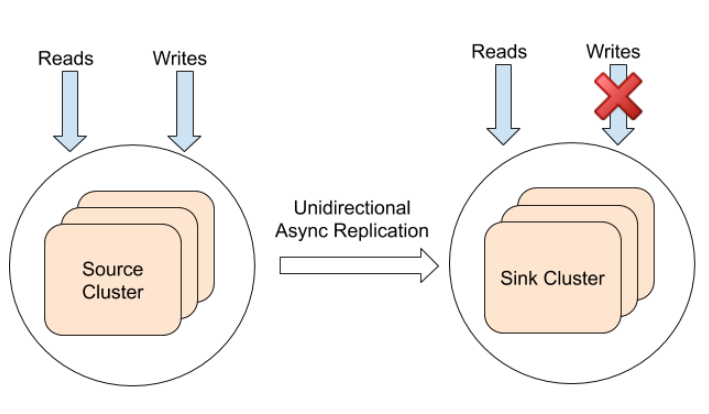
YugabyteDB provides synchronous replication of data between nodes in a cluster dispersed across multiple (three or more) data centers. However, many use cases require asynchronous replication across two or more data centers. YugabyteDB supports xCluster asynchronous replication on a per-table basis to support these use cases.
The replication could be unidirectional from a source cluster to one or more “sink clusters “ (or bi-directional as described later). The sink clusters, typically located in data centers or regions that are different from the source cluster, are passive because they do not not take writes from the higher layer services. Such deployments are typically used for serving low latency reads from the slave clusters as well as for disaster recovery purposes. This is shown in the diagram below.
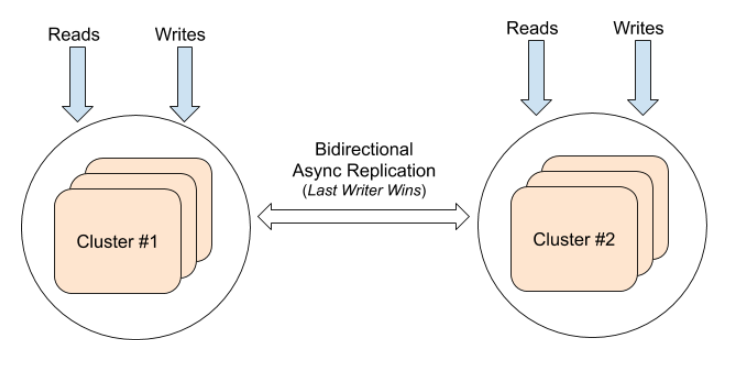
The replication of data can also be bi-directional between two clusters. In this case, both clusters can perform reads and writes. Any update to either cluster is asynchronously replicated to the other cluster with a timestamp for the update. If the same key is updated in both clusters at a similar time window, this will result in the write with the larger timestamp becoming the latest write.
Read more about asynchronous replication, or more generally the different multi-region deployments supported in YugabyteDB.
In hindsight – the most critical decisions
The previous sections show that even before embarking on the implementation phase of YugabyteDB, we had done a lot of design work, collected user feedback and thought through Day 2 operations based on our collective experiences running databases in production. However, some of the decisions, in retrospect, turned out to be far more important than others, and are outlined below.
Reusing the PostgreSQL codebase
The YugabyteDB Query Layer was designed with extensibility in mind. Having already built the YCQL API into this query layer framework from ground up to be highly compatible with Apache Cassandra, a rewrite of the PostgreSQL API seemed easier and natural at first. We were about 5 months down this path before we realized this was not an ideal path. The other APIs were much simpler compared to the mature, full-fledged database that PostgreSQL was. We then reset the whole effort, went back to the drawing board, and started anew with the approach of re-using PostgreSQL’s query layer code. While this was painful in the beginning, it has been a much better strategy in retrospect.
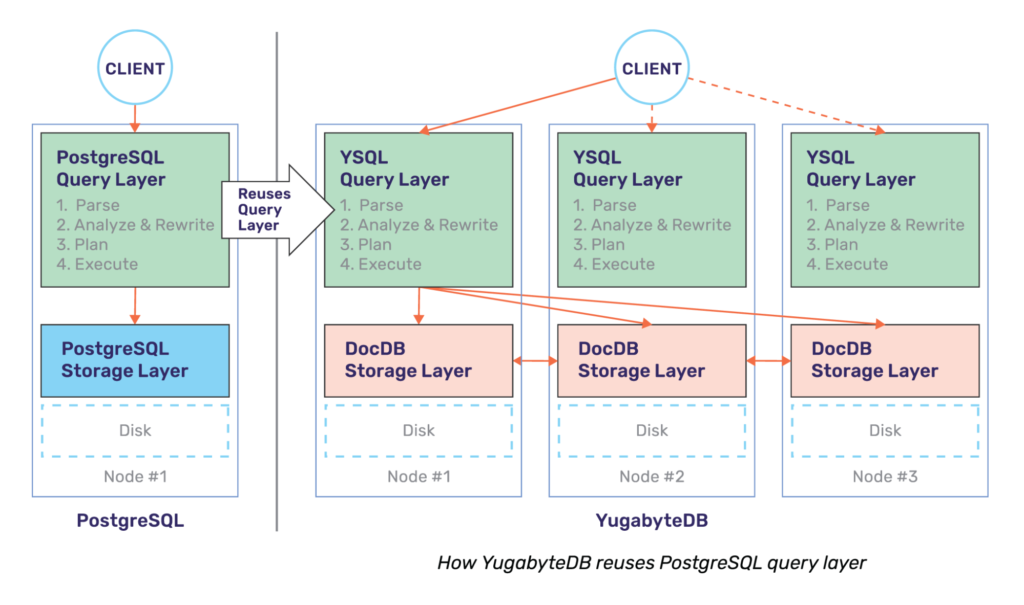
Our post Distributed PostgreSQL on a Google Spanner Architecture – Query Layer highlights how the query layer works in detail. The single biggest advantage of this reuse approach is the fact that YugabyteDB gets to leverage advanced RDBMS features that are well designed, implemented, and documented by PostgreSQL. While the work to get these features to work with high performance on top of a cluster of YugabyteDB nodes is significant, the query layer does get radically simplified with such an approach. Compared to other distributed SQL databases, YugabyteDB supports many more RDBMS features such as table functions, stored procedures, triggers, row and column security, various types of partial and expression indexes, user defined types, and many other features listed on our GitHub repo.
Ensuring high performance
Another critical decision was to focus on high performance, starting with writing YugabyteDB in C++ to ensuring high performance without the overhead of garbage collection, and unlocking the ability to leverage large memory heaps (RAM) as an internal database cache. It is optimized primarily to run on SSDs and NVMe drives. It is also designed to handle high write throughput workloads, many concurrent clients, and high data density (total data set size) per node.
YugabyteDB also uses a highly customized version of RocksDB, a log-structured merge tree (LSM) based key-value store. A number of enhancements or customizations were done to RocksDB in order to achieve scalability and performance in YugabyteDB.
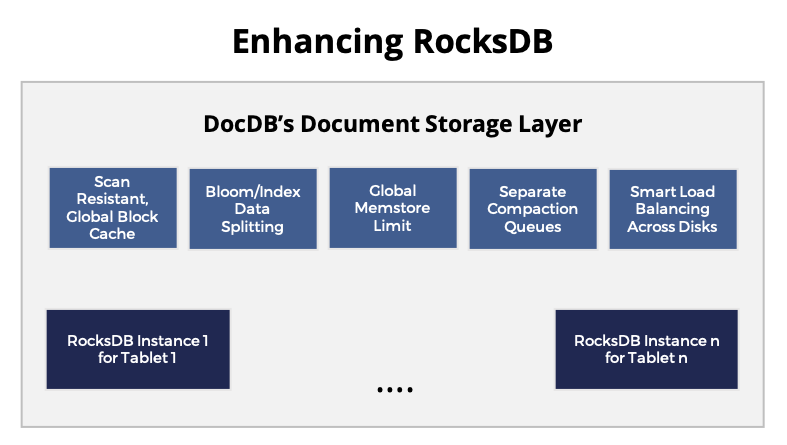
Switching to 100% open source
Another pivotal decision was to make YugabyteDB fully open sourced under the Apache v2 license. YugabyteDB had started as an open-core project, where there were some enterprise features such as distributed backups and security features such as encryption requiring a commercial license. In May 2019, we switched YugabyteDB to a 100% open source licensing model, because we wanted to be as open as PostgreSQL, the database API we were supporting.
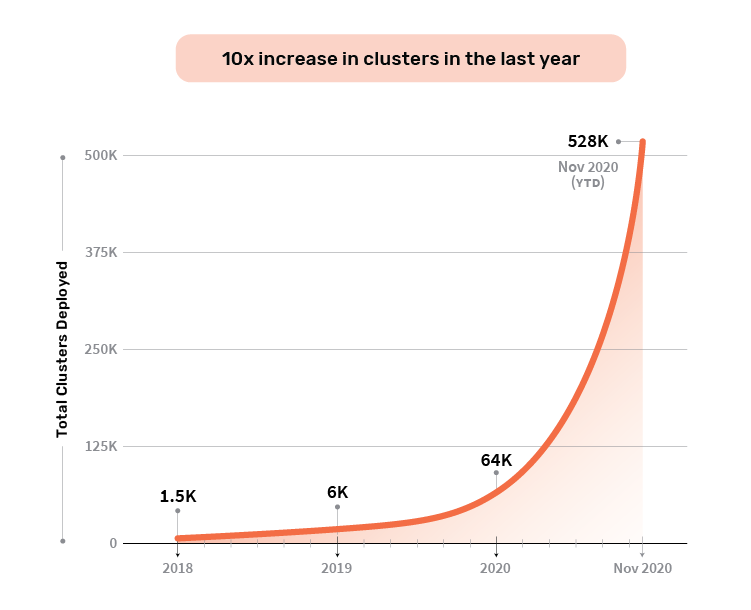
Industry observers and open source experts have noted that our change goes against the trend of database and data infrastructure companies abandoning open source licenses for some or all of their projects. But over the 18 months since then, we’ve seen great adoption from the community. The number of YugabyteDB clusters created has been increasing at 10x year over year, now with more than half a million clusters deployed in the lifetime of the project.
Additionally, there are now over 2600 members in YugabyteDB’s community Slack channel, where users can get near real time help on fast moving projects and get answers to technical questions quickly from YugabyteDB contributors, as well as exchange learnings with experienced community members who have “been there and done that.”
Who’s using it – YugabyteDB in your daily life
Five years later, we are proud of just how far we have come as a project, something that would not have been possible without the support of innumerable people all of whom took a huge leap of faith based on the belief in the vision and the team – the customer and user community giving very valuable feedback, early adopters putting their most prized and business critical workloads on top of this new database, fellow builders of the database who joined in this mission, and the strong set of advisors and investors alike who believed in what we were building.
While the database is a critical piece of infrastructure for many user-facing services, it remains mostly invisible to end users (and rightfully so). That said, millions of users every day rely on services that are built on top of YugabyteDB as the database. Below are some examples – perhaps you have used some of these services too!
Online shopping and ecommerce
Online shopping and ecommerce are rapidly rising, with Covid further accelerating these trends. If you have browsed Walmart.com to browse items, you have likely used the product mappings microservice that is powered by YugabyteDB. If you create a shopping list or use the shopping cart on Kroger.com, these services use YugabyteDB. In fact, if you have purchased anything online from most major retailers other than Amazon.com, a portion of that service was likely powered by YugabyteDB. Narvar.com powers the post purchase and customer loyalty experience for most retailers such as Costco, Home Depot, Gap, Niemen Marcus, and many others. Narvar switched from Amazon DynamoDB and Aurora to YugabyteDB as the backing database for most of their core microservices. All of these retailers used YugabyteDB to ensure very high availability, scalability, and low latency responses – especially mega online shopping events such as Black Fridays and Cyber Mondays.
Financial services
Online banking is now rapidly becoming commonplace. Building a great online banking service requires not only high availability and scalability but also transactional consistency and low latency. Ever used financial services services from Robinhood, Investopedia, Wealthfront, or Blackrock? Then most likely you have indirectly used YugabyteDB. About 800 financial institutions and fintech firms rely on cloud-native market data APIs from Xignite to power their services, and Xignite relies on YugabyteDB. Other large banks and financial institutions also rely on YugabyteDB as their system of record database to serve business-critical services.
IoT and Telco
Other areas where YugabyteDB tends to be heavily used are IoT and Telco workloads. As an example, if you’re using some of the largest ISPs in America, Canada, and Europe such as Comcast, Bell Canada, Armstrong, TalkTalk, and others – you’re indirectly using YugabyteDB. These ISPs all rely on the Plume platform to monitor and manage WiFi across millions of homes.
What’s ahead – our journey is 1% done
In keeping with the above popular Facebook saying, the journey of YugabyteDB has just begun, and there are a number of exciting and groundbreaking features yet to come. Some of these are highlighted below.
Exciting, core database features
The pursuit to build useful features core to the database is ever ongoing. And we’re indeed seeing a huge demand for a number of useful core database features from our community of users. Examples of some of these features include point in time recovery to rewind the state of the database to a timestamp in the past, enabling text search similar to that of PostgreSQL, geospatial support support using PostGIS, improving the query optimizer for distributed execution, and deeper integrations with other projects and frameworks that currently leverage PostgreSQL.
High throughput use-cases and real-time analytics
Another broad area of investment to watch are features that improve real-time queries, streaming workloads and use-cases with very high throughput query or update needs. Examples in this bucket include improvements to parallel query framework, data exchange using messaging systems like Apache Kafka or Apache Pulsar, columnar storage format for better compression, and many other such features.
Supporting more APIs – Babelfish (SQL Server), MySQL
The concept of building a multi-API database was a relatively new one when we started building YugabyteDB. Amazon Aurora, which supported both MySQL and PostgreSQL APIs, was a multi-API database. CosmosDB from Microsoft Azure launched about a year later in 2017 as another multi-API database. Our hypothesis is that we’re going to see other such efforts get going, and some of these atop PostgreSQL.
A project of interest to the YugabyteDB community is Babelfish for PostgreSQL being open sourced by Amazon, SQL Server-compatible end-point for PostgreSQL to make PostgreSQL fluent in understanding communication from apps written for SQL Server (i.e., including understanding T-SQL and TDS communication protocol). Once Babelfish gets open sourced, we’re planning to attempt integrating it into YugabyteDB, which is also based on PostgreSQL. Another interesting discussion in the PostgreSQL community revolves around a MySQL translation layer for PostgreSQL, which allows MySQL applications to interact with PostgreSQL and possibly YugabyteDB.
Join us in our mission
If you have made it thus far, thank you for reading about our journey over the last half-decade. If you’re interested in being a part of this journey over the next half-decade when we do another such retrospective, please join us – we’re hiring across the board. Also consider joining our community Slack and becoming a contributor to the project.


