YugabyteDB Fundamentals Training Q&A – Jan 28, 2021
January 29, 2021
Yesterday we had almost 200 folks show up for the latest “YugabyteDB Fundamentals and Certification” training session. We had a lot of questions during the session and weren’t able to get to them all! In this blog I have compiled the majority of them and provided answers in a simple Q&A format.
Missed yesterday’s training? You can catch our next training session, “YugabyteDB YSQL Development and Certification and Training” on Feb 25 by registering here.
Questions and Answers
If distributed SQL is strongly consistent, then won’t the performance always be slower than a monolithic system because data always needs to be replicated to multiple nodes?
No. At scale, a monolithic database will usually bottleneck on reads, writes, or both because of the practical limitations of the software or computing resources that are available. Distributed databases have theoretically limitless access to resources in order to horizontally scale both reads and writes. So, although RPCs are not free, meaning you can’t beat the laws of physics, when architected correctly, a distributed database can achieve single or sub single digit ms latency. In a nutshell, it’s a game of scaling up vs scaling out.
Do we need to use a load balancer with YugabyteDB?
For YSQL, an external load balancer is recommended, but note the following:
If you use the YugabyteDB JDBC driver (currently in beta) with an application that regularly opens and closes connections to clients, then the YugabyteDB JDBC driver effectively provides basic load balancing by randomly using connections to your nodes.
If you use the Spring Data Yugabyte driver (currently in beta) with your Spring application, then the underlying YugabyteDB JDBC driver provides basic load balancing.
If you have an application that is not in the same Kubernetes cluster, then you should use an external load balancing system.
For YCQL, YugabyteDB provides automatic load balancing.
What do I need to consider when sizing a YugabyteDB cluster?
The key metric to consider when sizing a YugabyteDB cluster is the number of read/write transactions per second for a given value size (think rows and columns). Our sample workload generator application is particularly useful in determining how many reads/writes a given cluster can handle and what the latency will be given a particular topology. If the number of reads/writes is higher than the sample application output at that value size, then you need to increase the size of the cluster proportionally to the difference. It is good practice to run these sample generators to consume 50-60% of cpu utilization to allow for normal recovery operations to have headroom to operate.
Where can I learn about YugabyteDB customer and community success stories?
Visit our case studies page to learn more.
How does YugabyteDB compare to Cassandra?
You can get an in-depth comparison of YugabyteDB and Cassandra by visiting our Docs.
Does YugabyteDB support Robin.io cloud?
Yes, Robin.io is a supported K8s platform for Yugabyte Platform deployments. You can find the instructions here.
What is the best way to manage latency when nodes are in different geos?
There are a couple of different techniques that can be employed, from choosing where nodes are deployed, using geo-partitioning, and perhaps even asynchronous replication. Learn more by checking out the Docs on multi-region deployments in YugabyteDB and reading this blog post on building cloud native, geo-distributed apps with low latency.
Where can I go to download YugabyteDB?
You can visit either our Downloads page or the Quickstart Guide.
What’s the significance behind the name “Yugabyte?”
Yuga in Sanskrit represents an era or an epoch (about 4.32 million human years), a very long period of time. We picked the name Yugabyte to signify data that lives forever and without limits.
When executing a write, how does YugabyteDB know which shard to update?
A write request first hits the YQL query layer on a port with the appropriate API, which is either YSQL or YCQL. This write is translated by the YQL layer into an internal key. Each key is owned by exactly one tablet. This tablet as well as the YB-TServers hosting it can easily be determined by making an RPC call to the YB-Master. The YQL layer makes this RPC call to determine the tablet/YB-TServer owning the key and caches the result for future use.
YugabyteDB has a smart client that can cache the location of the tablet directly and can therefore save the extra network hop. This allows it to send the request directly to the YQL layer of the appropriate YB-TServer which hosts the tablet leader. If the YQL layer finds that the tablet leader is hosted on the local node, the RPC call becomes a local function call and saves the time needed to serialize and deserialize the request and send it over the network.
The YQL layer then issues the write to the YB-TServer that hosts the tablet leader. The write is handled by the leader of the Raft group of the tablet owning the key. You can learn more about the write IO path here.
Do I need to define my data model in YugabyteDB, just like I would with a traditional RDBMS?
When making use of the YSQL API, you model your data using DDL statements, just like you would in PostgreSQL.
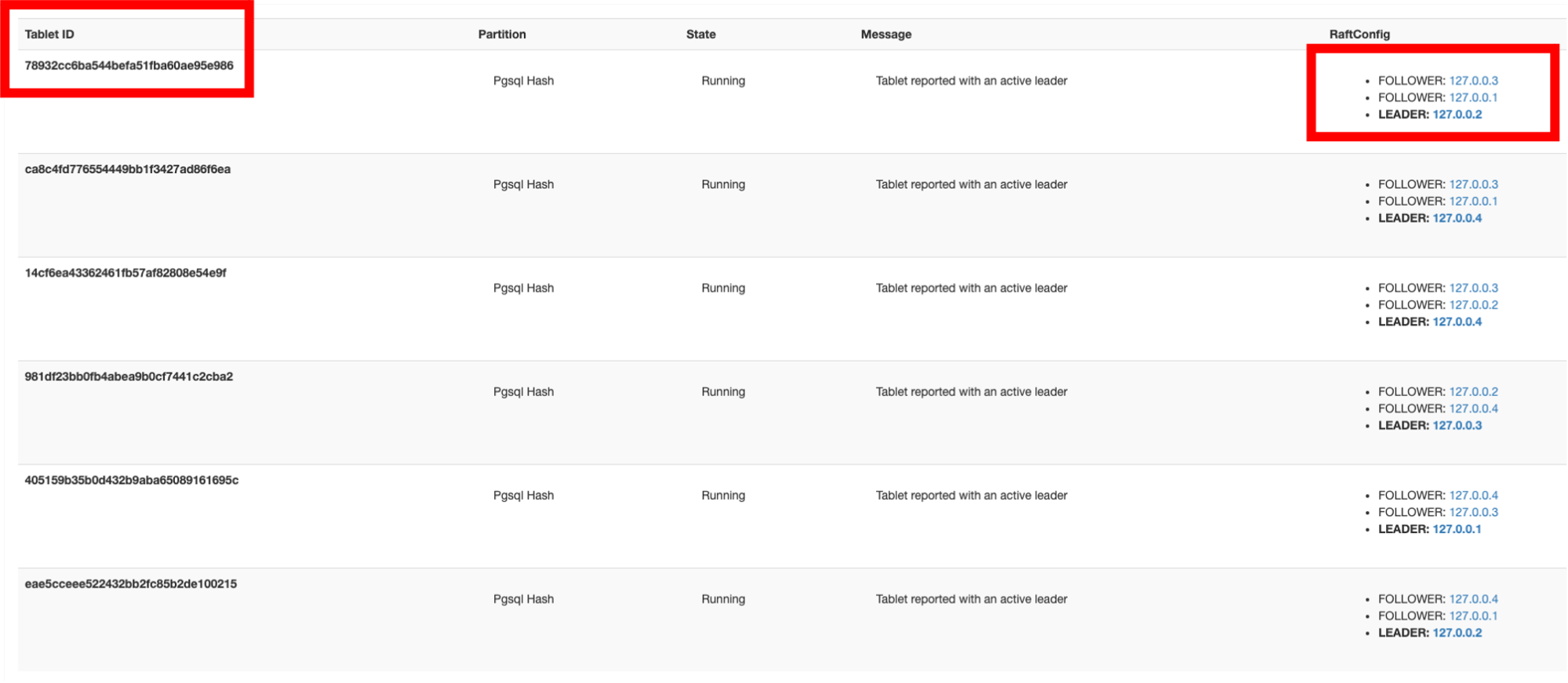
How can I discover where shards (tablet leaders and followers) are located?
One simple way to discover this information is to use the built-in YugabyteDB Web UI (https://yugabyte-ip:7000) and click on “Tables.” In the screenshot below you can see the tablets that make up a table (in this case the “customers” table) and where those tablets are located.
Does YugabyteDB also support NoSQL-styled workloads?
Yes. We built YugabyteDB with two APIs – YSQL (fully-relational) and YCQL (semi-relational). The YCQL API is specifically designed for NoSQL workloads. Check out the Docs for more information.
Are all types of PostgreSQL indexes supported or only B-tree?
YuagbyteDB actually uses LSM for docdb-storage tables/indexes and B-tree for temporary tables/indexes. You can learn more about LSM, B-Tree, and the basics of database storage engines in this post.
Since YugabyteDB’s distributed data store is based on RocksDB does it support pg_partman and pg_repack?
Neither of these utilities have been tested at this time. Support for table partitions is planned as part of the upcoming row-level geo-partitioning feature. With respect to pg_repack, note that the nature of our storage engine always stores the table organized by the PRIMARY KEY hash and range columns. Periodic compactions continually rewrite index structures and remove deleted rows automatically without the need for VACUUM operations found in Postgres.
Does Yugabyte db support PostgreSQL’s hstore datatype?
This extension has not yet been tested by our engineering team. In general, we expect most Postgres extensions that do not rely on specific storage layer integration to work. A detailed list of pre-bundled extensions can be found here. Note that extensions that require GIN and GIST support are not fully capable as those index types require additional support within our storage engine.
What is a “shard” in YuagbyteDB?
The functional equivalent in YugabyteDB is a “tablet.” Check out the Docs to learn more.
Is the rebalancing of nodes automatic in YugabyteDB? For example after a network partition is resolved or when scaling or shrinking a cluster?
Yes, the rebalancing of nodes is automatic in YugabyteDB. Check out the High Availability and Horizontal Scalability sections of the Docs or try it for yourself.
Will data residency be an issue to consider when we have multiple regions for Asia, Europe, and North America and a single YugabyteDB cluster ?
There are a couple of strategies to employ here. The most obvious one is to make use of row-based geo-partitioning. Check out the Docs on row-level geo-partitioning in YugabyteDB for more information.
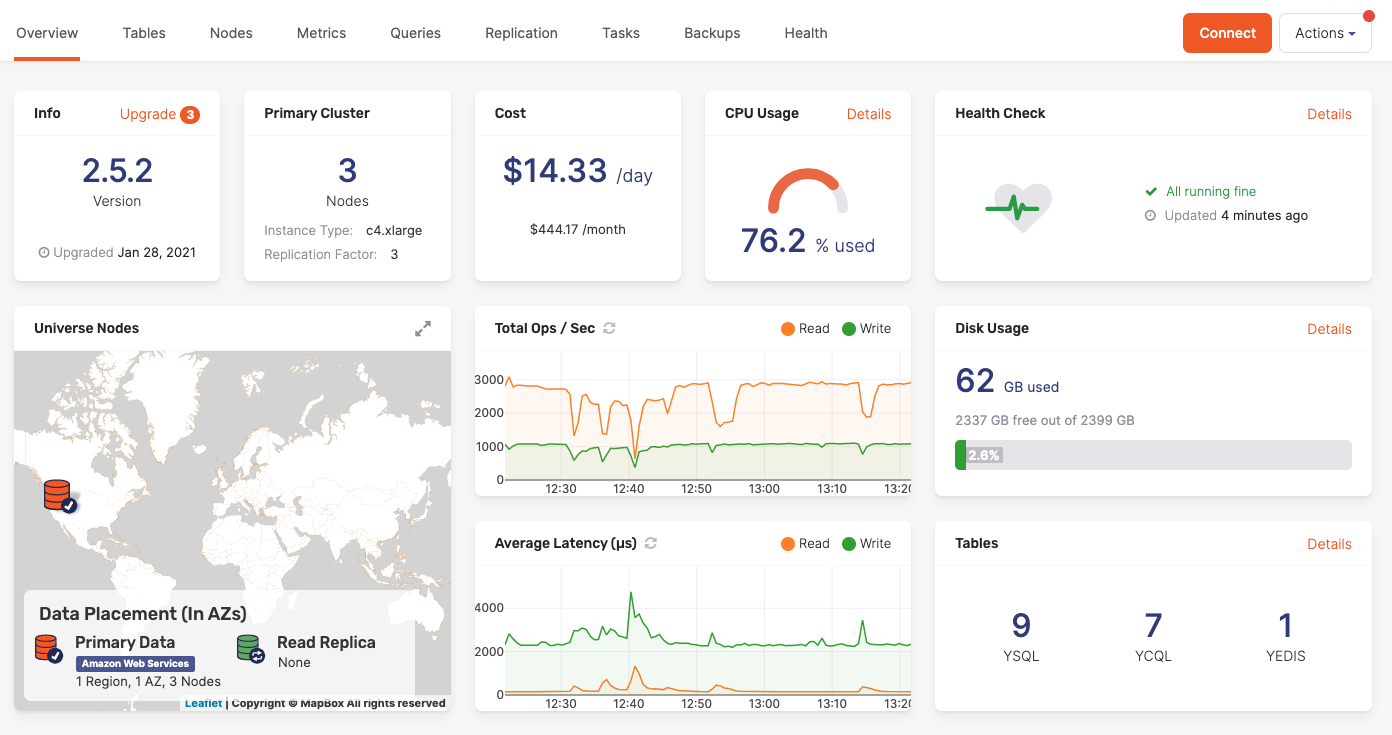
In Yugabyte Platform do I get cloud provider specific details and metrics or only database ones?
With Yugabyte Platform, a management platform for building your private DBaaS, you get database and cloud provider metrics relevant to the cluster.