Best Practices for Deploying Confluent Kafka, Spring Boot & Distributed SQL Based Streaming Apps on Kubernetes
June 12, 2019
In our previous post “Develop IoT Apps with Confluent Kafka, KSQL, Spring Boot & Distributed SQL”, we highlighted how Confluent Kafka, KSQL, Spring Boot and YugabyteDB can be integrated to develop an application responsible for managing Internet-of-Things (IoT) sensor data. In this post, we will review the challenges and best practices associated with deploying such a stateful streaming application on Kubernetes.
Challenges of Streaming Apps
Streaming apps are inherently stateful in nature given the large volume of data managed and that too continuously. As shown in the figure below, there are four primary challenges with such apps in the context of scalability, reliability and functional depth.
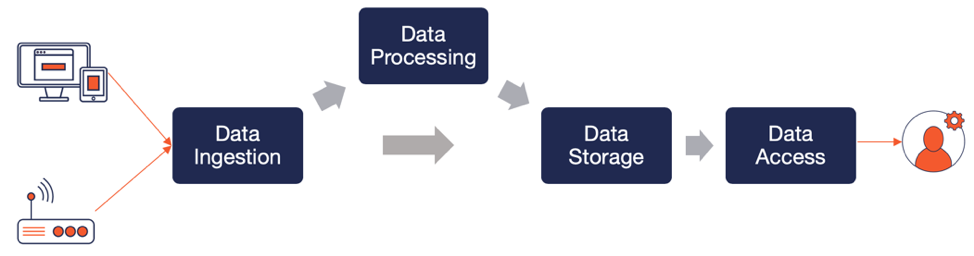
Data Ingestion
For a simple 3-tier user-facing application with no streaming component, data is created and read by users. For the majority of such cases, a single node RDBMS is good enough to manage the application’s requests for data. However, when a streaming component is added, things tend to become quite complex. This streaming component usually has to handle a firehose of ever-growing data that is generated either outside the application (such as IoT sensors and monitoring agents) or inside the application (such as user clickstream). Feeding this firehose directly to your database may not be the best approach if you would like to pre-process the messages first, perform initial analysis and then finally store either a subset of the data or an aggregate of the data in the database. Enter a publish-subscribe streaming platform like Apache Kafka that is purpose-built for handling large-scale data streams with high reliability and processing flexibility. Confluent Kafka is an enterprise-grade distribution of Kafka from Confluent, the company with the most active committers to the Apache Kafka project.
Data Processing
For the initial analysis/aggregation phase highlighted above, there is a need for a strong analytics framework that can look at the incoming streams over a configurable window of time and give easy insights. While there are dedicated real-time analytics frameworks such as Apache Spark Streaming and Apache Flink, the one that’s natively built into the Confluent Kafka platform is KSQL. Built as a stateless stream processing layer using the Kafka Streams API, KSQL essentially converts incoming data into Streams and Tables that can be analyzed using a custom SQL-like query language. The results can be stored back in to Kafka as new topics which external applications can consume from. Kafka users may choose to use the Kakfa Streams API directly if that’s more convenient.
Data Storage
While Kafka is great at what it does, it is not meant to replace the database as a long-term persistent store. This is because the persistence in Kafka is meant to handle messages temporarily while they are in transit (that includes KSQL-driven stream processing) and not to act as a long-term persistent store responsible for serving consistent reads/writes from highly-concurrent user-facing web/mobile applications. As we highlighted in “5 Reasons Why Apache Kafka Needs a Distributed SQL Database”, business-critical event-driven apps are best served by augmenting their Kafka infrastructure with a massively scalable and fault-tolerant distributed SQL database like YugabyteDB.
Data Access
Last but not least, the data that has been moving through Kafka, KSQL and distributed SQL has to be served to users easily without sacrificing developer productivity. Enter the Spring framework as well as its Spring Boot and Spring Data projects. While Spring Boot is aimed to get users started with easy to understand Spring defaults, Spring Data is geared towards enabling Spring apps integrate with a wide variety of databases without writing much of the database access logic themselves.
Isn’t Kubernetes the Wrong Choice?
If we inspect the streaming app closely, there are two stateless components, namely KSQL and Spring Data, and two stateful components, namely Confluent Kafka and a distributed SQL DB. Now add to the mix, the long held belief that Kubernetes is the wrong choice for running business-critical stateful components. We have a problem on our hands. With not one but two stateful components dealing with continuous ever-growing data streams, streaming apps easily become one of the hardest to deal with in the stateful Kubernetes category.
Best Practices for Streaming Apps on Kubernetes
Running stateful apps like Kafka and distributed SQL databases on Kubernetes (K8S) is a non-trivial problem because stateful K8S pods have data gravity with the K8S node they run on. Treating such pods exactly the same as stateless pods and scheduling them to other nodes without handling the associated data gravity is a recipe for guaranteed data loss. But we do want to solve this problem because of all the application development agility and infrastructure portability benefits that come with standardizing on K8S as the orchestration layer. Here are a few best practices to follow.
1. StatefulSets for Stateful Apps
As we have previously highlighted in “Orchestrating Stateful Apps with Kubernetes StatefulSets”, the K8S controller APIs popular for stateless apps (such as Replica Set, Deployment and Daemon Set) are inappropriate for supporting stateful apps. GA since v1.9, the StatefulSets controller API is the right abstraction for stateful apps. This is because StatefulSets pods can provide the following four guarantees.
- Stable, unique network identifiers.
- Stable, persistent storage.
- Ordered, graceful deployment and scaling.
- Ordered, automated rolling updates.
Since each pod in the StatefulSet has a unique network ID that does not change across restarts or reschedules, StatefulSets have to be accessed through a headless service that allows all pod IDs to be discovered.
2. Low Latency Storage
Now that we have settled on leveraging StatefulSets, the next question to answer is about the type of storage volume (aka disk) to attach to the K8S nodes where the StatefulSet pods will run. The following table highlights the key differences.

Local storage delivers lower latency but unfortunately does not have the ability to be dynamically provisioned by stateful apps. This means cluster administrators have to manually make calls to their cloud or storage provider to create new storage volumes, and then create local PersistentVolume objects to represent them in K8S. This loss of agility maybe acceptable to you if performance is a higher priority. Note that local storage is recommended only for stateful apps that have built-in replication so that there is no data loss even when there is loss of a K8S node (and the attached local volume).
3. High Data Resilience
Resilience against Node Failures
Assuming a single zone deployment, the choice of storage type has implications on the type of pod affinity configuration recommended for tolerating node failures.
- When using remote storage, you can allow pods of same types to be affinitized to the same K8S node for better resource utilization. This is because data resilience continues to remain intact even when that node is lost for any reason — new pods will get scheduled to other nodes and get attached to the previously used storage volume.
- When using local storage, additional care has to be taken to ensure data resilience. You should be leveraging K8S’ pod anti-affinity directives so that pods of the same type are never scheduled on to the same node. Note that if you allow such a case in a Replication Factor 3 cluster of Kafka or YugabyteDB, then you allow two copies of the same shard to be potentially placed on the same K8S node. Losing that node means losing the ability to write to those shards as well as read strongly consistent data out of those shards.
Resilience against Zone, Region and Cloud Failures
While the above configuration protects you from node failures in a single region, additional considerations are necessary if you need tolerance against zone, region and cloud failures. Essentially it boils down to deploying your K8S cluster(s) in a multi-zone, multi-region and multi-cloud configuration.
A single K8S cluster can be made multi-zone by attaching special labels (such as failure-domain.beta.kubernetes.io/zone for the zone name) to the nodes of the cluster. The presence of these labels direct K8S to automatically spread pods across zones as application deployment requests come in. However, such a configuration is not recommended for multi-region and multi-cloud deployments because the entire cluster will become non-writeable the moment the K8S master leader node gets partitioned away from the master replica nodes (assuming a highly available K8S cluster configuration). These sort of partitions can be common when WAN latency of the internet comes into the picture for a single K8S cluster that is spread across multiple geographic regions.
Multi-region and multi-cloud K8S deployments are essentially multi-cluster deployments where each region/cloud runs an independent cluster. This approach is known as K8S Cluster Federation (KubeFed) and official support from upstream K8S is in alpha. Some downstream distributions such Rancher Kubernetes Service have created their own multi-cluster K8S support using an external/global DNS service similar to the one proposed by KubeFed.
4. High Performance Networking
Network configuration to run high-performance stateful apps can get complicated easily. For example, an important issue arises when the data producers are not deployed in the same Kubernetes cluster. This is indeed the case with streaming apps where the data producers are essentially IoT sensors.
- If you want the incoming data stream to be ingested directly into Kafka, then you cannot rely on the Kubernetes headless service (see the section below) but have to expose the Kafka statefulset using an external-facing load balancer that is usually specific to the cloud platform where Kafka is deployed. This load balancer exposes a single endpoint for the producers to talk to and round-robins incoming requests across the Kafka statefulset pods. Note that some of the key benefits of a statefulset such as accessing a pod directly using the pod’s unique ID is lost in this approach.
- If you want to continue to retain the ability to talk to a given pod directly, then you have to develop an app ingestion layer that processes the incoming stream and then routes it to the appropriate Kafka pod. This approach can be of lower latency than the stream getting ingested into Kafka directly because of the ability to avoid communication with pods that don’t manage the data records being processed.
Note the same considerations as above arise if we replace producers to Kafka communication with that of Spring App to YugabyteDB.
IoT Fleet Management App in Action
This section highlights how to deploy our reference streaming application, IoT Fleet Management, on K8S. We will initially model each of the components in K8S and thereafter deploy the entire application on a K8S cluster.
Confluent Platform on Kubernetes
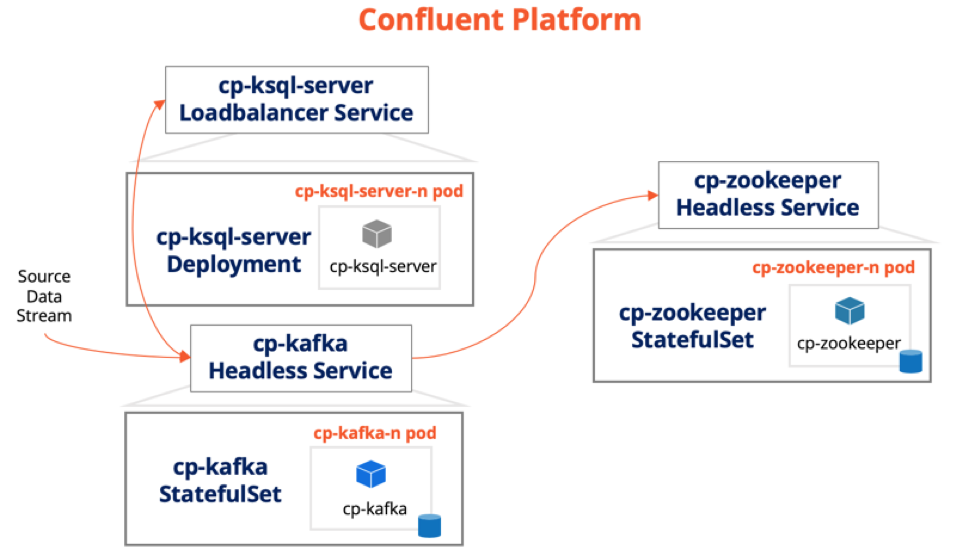
As shown in the figure below, of the many components that ship as part of the Confluent Platform, only three are mandatory for our IoT app.
- Step 1:
cp-kafkastatefulset and its headless service - Step 2:
cp-zookeeperstatefulset and its headless service - Step 3:
cp-ksql-serverdeployment and a loadbalancer service
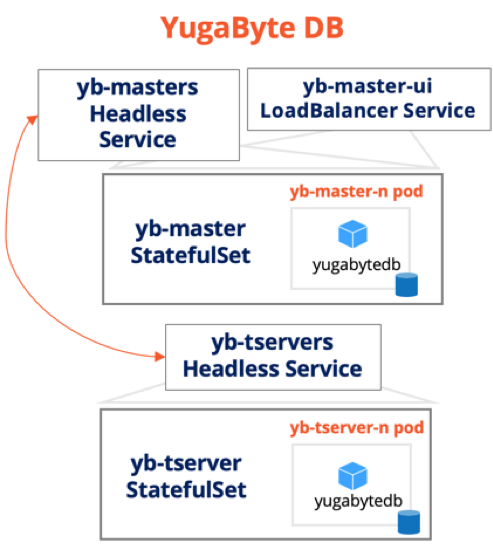
YugabyteDB on Kubernetes
YugabyteDB is modeled in K8S using two statefulsets. Note that the same yugabyte/yugabytedb container image is used in both the statefulsets.
yb-tserverstatefulset and its headless service to model the data nodes of the distributed SQL database.yb-masterstatefulset and its headless service to model the system coordinator nodes of the distributed SQL database.
Spring Boot App on Kubernetes
The Spring Boot IoT app is modeled in K8S using a single yb-iot deployment and its loadbalancer service. Note that the yb-iot pod runs with the same container instantiated twice — once as the spring app and once as the event producer (for the cp-kafka statefulset). The latter container instance acts as a load generator for the local cluster deployment — this instance will not be present in a real-world deployment since events will be produced by IoT sensors embedded in the physical devices. Review the networking best practices section to understand how to configure the producers to Kafka communication.

The Full Picture
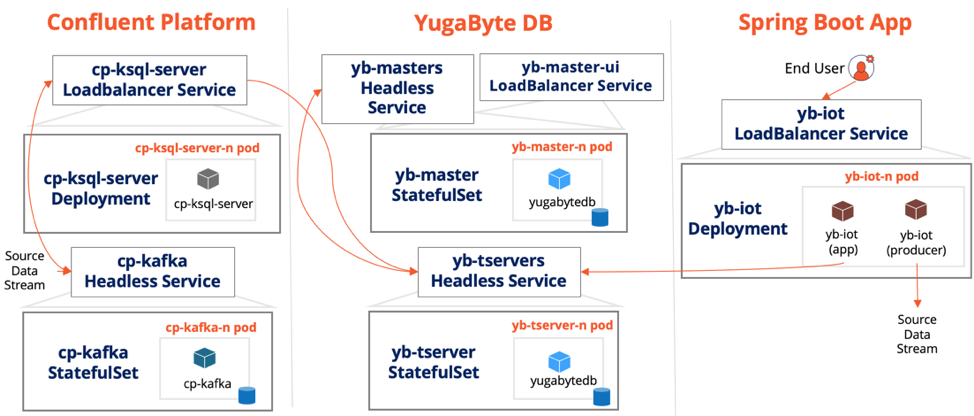
The above figure shows all the components necessary to run the end-to-end IoT app on K8S (note that the cp-zookeeper statefulset has been dropped for the sake of simplicity). The yb-iot-fleet-management GitHub repo has the steps to deploy the app onto a minikube local cluster by bringing together the Helm Charts of each of the components. The number of replicas for each component can be increased in a real-world multi-node Kubernetes cluster. The repo also has the source code for the overall application. Note that the integration between YugabyteDB and Confluent Kafka is based on the open source Kafka Connect YugabyteDB Sink Connector.
Summary
Streaming apps are a unique breed of stateful apps given their need to continuously manage ever-growing streams of data. Given Kubernetes roots as the orchestration layer for stateless containerized apps, running streaming apps on Kubernetes used to be a strict no-no until recently. Over the last few releases, Kubernetes has made rapid strides in supporting high-performance stateful apps through the introduction of StatefulSets controller, local persistent volumes, pod anti-affinity, multi-zone HA clusters and more. This post highlights some of the key challenges as well as four best practices to consider when deploying streaming apps on Kubernetes. It does so using an open source sample app yb-iot-fleet-management which is built on Confluent Kafka, KSQL, Spring Data and YugabyteDB.
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.

")
