Oracle vs PostgreSQL: First Glance – Testing YugabyteDB’s Compatibility
May 14, 2020
Roland Takacs recently wrote an interesting blog post titled Oracle vs PostgreSQL: First Glance. The genesis for his blog post was that he was in the middle of migrating his current Oracle tech stack to Python, parquet files, and PostgreSQL. As such, Roland thought it might be a good exercise to document the various Oracle features he was accustomed to and figure out what the equivalent functionality was in PostgreSQL. In his post, Roland walked us through 15 different Oracle features and their PostgreSQL equivalents.
Seeing that YugabyteDB is a PostgreSQL-compatible, distributed SQL database (in fact it reuses PostgreSQL’s native query layer), I thought it would be an interesting exercise to verify which of the “Oracle functional equivalents” in PostgreSQL that Roland highlighted would also work in YugabyteDB. YugabyteDB supports more SQL features than any other distributed SQL database, including CockroachDB. In this post I’ll walk you through each of the features from Roland’s post so we can see how YugabyteDB stacks up on the “PostgreSQL compatibility” vector.
What’s YugabyteDB? It is an open source, high-performance distributed SQL database built on a scalable and fault-tolerant design inspired by Google Spanner. Yugabyte’s SQL API (YSQL) is PostgreSQL wire compatible.
If you’d like to follow along and test the exercises against YugabyteDB, you can either install a cluster locally or sign up for a free cluster of YugabyteDB Managed.
DUAL Table
Oracle
Oracle ships with a table called DUAL which can be thought of as a dummy table with a single record that can be used for selecting when you’re not actually interested in the data, but instead want the results of some system function in a SELECT statement. For example:
SELECT 1*3 FROM dual;
PostgreSQL
The DUAL table doesn’t exist in PostgreSQL, but you can achieve similar results by excluding the FROM clause.
SELECT 1*3;
YugabyteDB
YugabyteDB doesn’t have a DUAL table either, but supports the same functionality as PostgreSQL.
SELECT 1*3;
Result:
3
String Concatenation
Oracle
'Concat with ' || NULL
Result:
Concat with
PostgreSQL
To achieve the same Oracle functionality in PostgreSQL, we’ll need to use the concat function:
SELECT concat('Concat with ', NULL);
Result:
Concat with
YugabyteDB
YugabyteDB can perform string concatenation just like PostgreSQL.
SELECT concat('Concat with ', NULL);
Result:
Concat with
ROWNUM and ROWID
Oracle
ROWNUM is a pseudocolumn which indicates the row number in a result set retrieved by a SQL query. Likewise, ROWID is a pseudocolumn that returns the address of the row.
SELECT rowid,
rownum,
country
FROM country
WHERE rownum <= 5;
PostgreSQL
In PostgreSQL, you can execute something like this:
SELECT ctid AS rowid,
row_number() OVER(ORDER BY country) AS rn,
country
FROM country
LIMIT 5;
YugabyteDB
In YugabyteDB (as in PostgreSQL), the ROW_NUMBER() function is a window function that assigns a sequential integer to each row in a result set. We can perform a similar query on the us_states table in the Northwind sample database and get the same results.
SELECT row_number() OVER(ORDER BY state_name) AS rn,
state_name
FROM us_states
LIMIT 5;
Result:
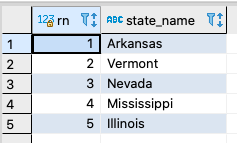
YugabyteDB currently doesn’t expose a PostgreSQL system column like ctid, so for now, Oracle’s ROWID functionality is not supported.
IF EXISTS for DDL Operations
PostgreSQL
With the IF EXISTS statement in Oracle you can check whether or not a database object exists before running a DDL operation on it. In PostgreSQL this can be achieved with statements like the ones shown below:
CREATE TABLE IF NOT EXISTS table_name (...); DROP TABLE IF EXISTS table_name; ALTER TABLE IF EXISTS table_name RENAME TO new_name; ALTER TABLE table_name DROP COLUMN IF EXISTS column_name;
YugabyteDB
Let’s put these IF EXISTS PostgreSQL statements into practice against YugabyteDB.
Example Query:
CREATE TABLE IF NOT EXISTS account( user_id serial PRIMARY KEY, username VARCHAR (50) UNIQUE NOT NULL, password VARCHAR (50) NOT NULL, email VARCHAR (355) UNIQUE NOT NULL, created_on TIMESTAMP NOT NULL, last_login TIMESTAMP );
Result:
Table creation succeeds.
Example Query:
ALTER TABLE account DROP COLUMN IF EXISTS email;
Result:
The email column in the account table is successfully dropped.
Example Query:
ALTER TABLE IF EXISTS account RENAME TO customers;
Result:
The accounts table is successfully renamed to customers.
Example Query:
DROP TABLE IF EXISTS customers;
Result:
The table is successfully dropped.
Outer Join Using (+)
Oracle
SELECT * FROM countries c, locations l WHERE c.country_id = l.country_id (+);
PostgreSQL
In PostgreSQL you can’t use (+) inside a query to force an outer join. As Roland points out, instead you’ll need to do something like this:
SELECT * FROM countries c LEFT OUTER JOIN locations l ON c.country_id = l.country_id;
YugabyteDB
We can perform a similar outer join against the Northwind sample database. Doing an outer join will get us all customers and orders for customers that have placed orders.
SELECT * FROM customers LEFT OUTER JOIN orders ON customers.customer_id = orders.customer_id;
We can also add a WHERE and IS NULL to the query to only return those customers who have not placed orders.
SELECT * FROM customers LEFT OUTER JOIN orders ON customers.customer_id = orders.customer_id WHERE orders.customer_id IS NULL;
Result:
This query returns the two customers who have not placed orders.

UPDATE Using Another Table
Oracle
In Oracle you can use a subquery to update values in a table depending on values in another table.
UPDATE countries SET country_name = upper(country_name) WHERE country_id IN (SELECT country_id FROM locations);
PostgreSQL
In PostgreSQL you can achieve similar results with the following statement:
UPDATE city SET city = upper(city) FROM country WHERE city.country_id = country.country_id;
YugabyteDB
YugabyteDB currently does not support a FROM clause in an UPDATE. You can track the resolution of this issue on GitHub, which is slated to be resolved in the upcoming 2.2 release.
DELETE Using Another Table
Oracle
Similar to the previous example, sometimes you want to DELETE values that match another table.
DELETE FROM locations WHERE country_id in (SELECT country_id FROM countries);
PostgreSQL
DELETE FROM city USING country WHERE city.country_id = country.country_id;
YugabyteDB
YugabyteDB currently does not support a USING clause in a DELETE. You can track the resolution of this issue on GitHub, which is slated to be resolved in the upcoming 2.2 release.
MERGE (UPSERT)
Oracle
In Oracle you can use a MERGE statement to insert or update data depending on its existence. Put another way, if the data exists, the columns are updated, if not, a new record is inserted.
MERGE INTO customers a
USING suppliers b
ON (a.name = b.name)
WHEN MATCHED THEN
UPDATE SET a.email = b.email
WHEN NOT MATCHED THEN
INSERT (name, email)
VALUES (b.name, b.email);
PostgreSQL
INSERT INTO customers (name, email)
VALUES ('Somebody', 'somebody@email.com')
ON CONFLICT (name)
DO UPDATE
SET email = customers.email;
YugabyteDB
Out of the box, YugabyteDB supports all the upsert functionality you’ll find in PostgreSQL.
Below is an example of “on conflict do nothing”. In this case, we don’t need to specify the conflict target.
INSERT INTO sample(id, c1, c2)
VALUES (3, 'horse' , 'pigeon'),
(4, 'cow' , 'robin')
ON CONFLICT
DO NOTHING;
In this next example we have a real “upsert”. In this case, we need to specify the conflict target. Notice the use of the EXCLUDED keyword to specify the conflicting rows in the to-be-upserted relation.
INSERT INTO sample(id, c1, c2)
VALUES (3, 'horse' , 'pigeon'),
(5, 'tiger' , 'starling')
ON CONFLICT (id)
DO UPDATE SET (c1, c2) = (EXCLUDED.c1, EXCLUDED.c2);
We can also make the “update” happen only for a specified subset of the excluded rows. We illustrate this by attempting to insert two conflicting rows (with id = 4 and id = 5) and one non-conflicting row (with id = 6). And we specify that the existing row with c1 = ‘tiger’ should not be updated with “WHERE sample.c1 <> ‘tiger'”.
INSERT INTO sample(id, c1, c2)
VALUES (4, 'deer' , 'vulture'),
(5, 'lion' , 'hawk'),
(6, 'cheetah' , 'finch')
ON CONFLICT (id)
DO UPDATE SET (c1, c2) = (EXCLUDED.c1, EXCLUDED.c2)
WHERE sample.c1 <> 'tiger';You can check out more examples of upserts in the YugabyteDB documentation.
Table Inheritance
In PostgreSQL, tables can inherit the data and structure from an existing table. Oracle table inheritance doesn’t exist in this form.
YugabyteDB
The INHERITS command is currently not supported in YugabyteDB, but you can track the progress of the issue on GitHub.
Copying Tables
Oracle
In Oracle you can create a table without additional objects like indexes or constraints. And depending on your SELECT condition, your table may or may not populate with data.
CREATE TABLE country_2 AS SELECT * FROM country;
To create the table without data, you can execute:
CREATE TABLE country_2 AS SELECT * FROM country WHERE 1=0;
PostgreSQL
To copy both table structure and data:
CREATE TABLE new_table AS TABLE existing_table;
YugabyteDB
The PostgreSQL example above works in YugabyteDB as expected, for example:
CREATE TABLE employees2 AS TABLE employees; SELECT * FROM employees2 limit 5;
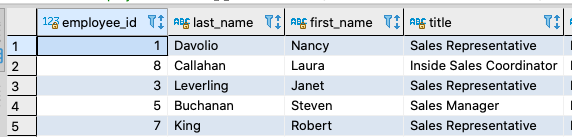
PostgreSQL
To copy only the table structure you can execute the following:
CREATE TABLE new_table AS TABLE existing_table WITH NO DATA;
YugabyteDB
This works in YugabyteDB as expected, for example:
CREATE TABLE employees3 AS TABLE employees WITH NO DATA; SELECT * FROM employees3 limit 5;
TRUNCATE
As Roland points out, unlike Oracle, TRUNCATE operations are transaction-safe in PostgreSQL. This means that if you place a TRUNCATE within the transaction statements such as a BEGIN and ROLLBACK, the truncation operation will be rolled back safely.
YugabyteDB
Currently, TRUNCATE is not transaction-safe in YugabyteDB. However, the feature is actively being worked on and can be tracked on GitHub here.
Hierarchical Queries
CONNECT BY-START WITH-PRIOR clauses from Oracle don’t exist in PostgreSQL. At least not by default. Roland recommends installing the tablefunc extension to get similar capabilities. He also points out that in PostgreSQL you can use recursive Common Table Expressions (CTE) to achieve the same result.
YugabyteDB
In YugabyteDB you can install the tablefunc extension by issuing:
CREATE EXTENSION tablefunc;
YugabyteDB also supports CTEs (documentation is in progress), if you want to go that route.
Partition Handling
Oracle and PostgreSQL allow for table partitioning in similar ways. Note that partitioned tables in these single-node databases enable a single table to be broken into multiple child tables so that these child tables can be stored on separate disks (tablespaces). Serving of the data however is still performed by a single node.
Following is an example of partition by list.
Oracle
CREATE TABLE sales (
salesman_id INTEGER PRIMARY KEY,
salesman_name VARCHAR2(30),
sales_region VARCHAR2(30),
sales_date DATE,
sales_amount INTEGER
)
PARTITION BY LIST (sales_region)
(
PARTITION p_asia VALUES ('INDIA','CHINA'),
PARTITION p_euro VALUES ('FRANCE','UK'),
PARTITION p_america VALUES ('USA','CANADA'),
PARTITION p_rest VALUES (DEFAULT)
);
PostgreSQL
CREATE TABLE sales (
salesman_id INTEGER,
salesman_name VARCHAR(30),
sales_region VARCHAR(30),
sales_date DATE,
sales_amount INTEGER
)
PARTITION BY LIST (sales_region);
CREATE TABLE sales_p_asia PARTITION OF sales FOR VALUES IN ('INDIA','CHINA');
CREATE TABLE sales_p_euro PARTITION OF sales FOR VALUES IN ('FRANCE','UK');
CREATE TABLE sales_p_america PARTITION OF sales FOR VALUES IN ('USA','CANADA');
CREATE TABLE sales_p_rest PARTITION OF sales DEFAULT;
YugabyteDB
Because YugabyteDB is a distributed SQL system vs a monolithic one like Oracle and PostgreSQL, partitioning means distributing data across multiple nodes of a cluster and is for the most part handled automatically by the database to create optimum availability and performance characteristics for the data. At a high-level, YugabyteDB’s design in this respect is inspired by Google Spanner.
In YugabyteDB, a SQL table is decomposed into multiple sets of rows according to a specific sharding strategy. Each of these sets of rows is called a shard. These shards are distributed across multiple server nodes (containers, VMs, bare metal) in a shared-nothing architecture. This ensures that the shards do not get bottlenecked by the compute, storage, and networking resources available at a single node. High availability is achieved by replicating each shard across multiple nodes. However, the application interacts with a SQL table as one logical unit and remains agnostic to the physical placement of the shards. YugabyteDB supports both HASH and RANGE sharding (partitioning.) For more information, check out the documentation on the subject.
Note that the PostgreSQL feature of partitioning a single table’s data into multiple disks is also automatic in YugabyteDB since you can attach as many disks you need to YugabyteDB nodes and data will remain auto balanced across them. Therefore, YugabyteDB intends reuse and extend PostgreSQL’s table partitioning SQL syntax for row-level geo-partitioning which allows specific rows to be pinned to specific regions of a geo-distributed/multi-region cluster. The cluster can now serve transactional reads and writes for users local to a given region without incurring any cross-region latency. You can learn more about row-level geo-partitioning on GitHub and track the feature here.
Block Structure
Oracle
In Oracle you can organize your code into blocks, procedures, or functions. For example:
DECLARE ... variables BEGIN ... code to be executed EXCEPTION ... exception handling END;
PostgreSQL
The functional equivalent in PostgreSQL would look like this:
DO $ DECLARE ... variables BEGIN ... code to be executed EXCEPTION .. exception handling END $;
YugabyteDB
YugabyteDB supports PostgreSQL procedures and functions out of the box and should as expected. For example:
CREATE OR REPLACE PROCEDURE transfer(INT, INT, DEC) LANGUAGE plpgsql AS $ BEGIN -- subtracting the amount from the sender's account UPDATE accounts SET balance = balance - $3 WHERE id = $1; -- adding the amount to the receiver's account UPDATE accounts SET balance = balance + $3 WHERE id = $2; COMMIT; END; $;
Packages
As Roland points out, there is no functional equivalent in PostgreSQL for Oracle Packages. You can use naming conventions to try and organize your procedures into something that might appear like an Oracle package, but in reality, the functionality that an Oracle DBA would expect just won’t be there. YugabyteDB is no different than PostgreSQL in this respect.
Conclusion
As you can see from the examples, YugabyteDB is highly compatible with PostgreSQL and, in turn, Oracle. YugabyteDB already supports 10 of 15 features highlighted in Roland’s post with most of the missing features becoming available in the next release. So, if your organization is executing on a strategy to use less, not more Oracle in the future and are looking at PostgreSQL as a database technology to help you get there, you should be considering YugabyteDB. With YugabyteDB you get automatic geo-distribution, continuous availability, and open source licensing, all without sacrificing on SQL feature depth, performance, or ACID compliance.


