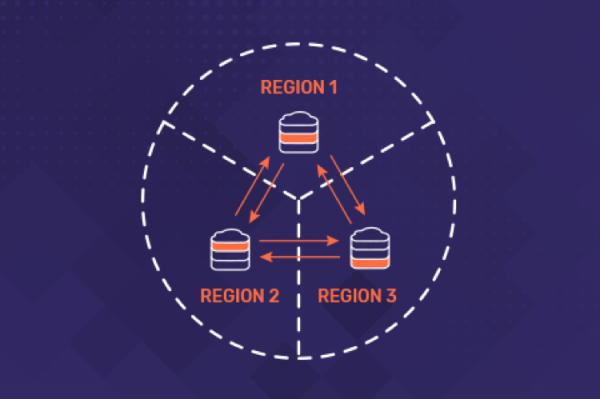
PostgreSQL vs. Distributed SQL: Understanding Behavior Differences
Distributed SQL offers greater scalability, availability, and geo-distribution of data compared to PostgreSQL, but it is important to understand the differences in behaviors between the two systems in order to make the most of your distributed SQL database.