Announcing YugabyteDB 2.0 GA: Jepsen Tested, High-Performance Distributed SQL
September 17, 2019
We are excited to announce the general availability of YugabyteDB 2.0! The highlight of this release is that it delivers production readiness for Yugabyte SQL (YSQL), our high-performance, fully-relational distributed SQL API. For those of you new to distributed SQL, YugabyteDB is a Google Spanner-inspired, cloud-native distributed SQL database that is 100% open source. It puts a premium on high performance, data resilience, geographic distribution while ensuring PostgreSQL compatibility.
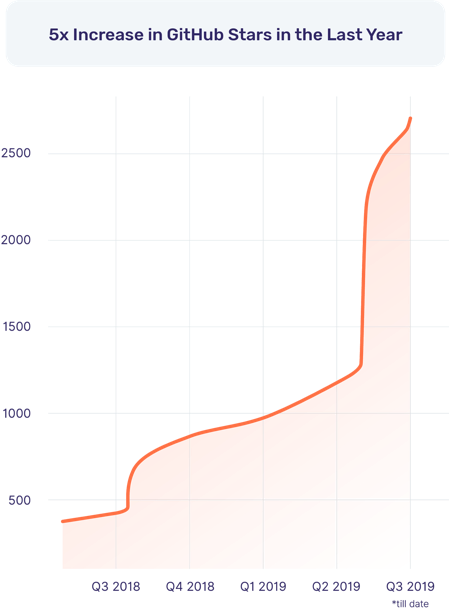
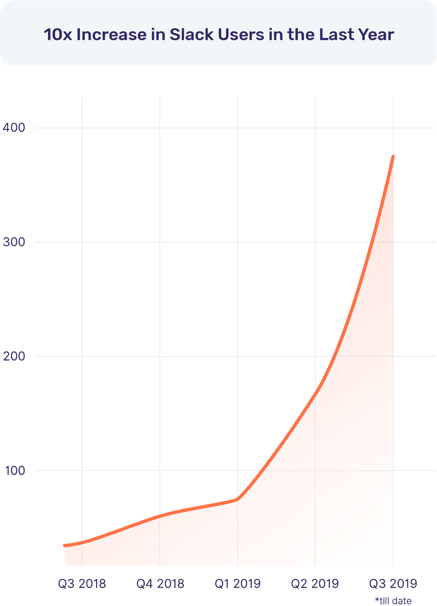
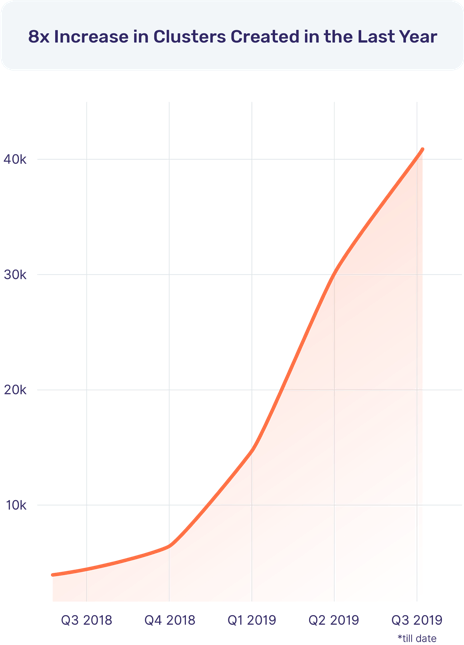
The operational DBMS industry trend over the last few years has been the increasing momentum of the distributed SQL revolution. Unlike specialized databases, distributed SQL appeals broadly to both startups and large enterprises looking to adopt cloud-native technologies for their entire software stack which includes database infrastructure. Application development and operations teams are excited that they no longer give up the data modeling flexibility and transactional capabilities of SQL in the process of going cloud native. From our vantage point, YugabyteDB’s GitHub stars have grown 5x and community Slack users have grown 10x in the last year alone. And these users have created 8x more clusters in the same period. We attribute this explosive growth to distributed SQL getting widely recognized as the next “big thing” in RDBMS technology, YugabyteDB going 100% open source as well as the eagerly-awaited YugabyteDB 2.0 release reaching GA.
“We are evolving the technology stack at Kroger to meet the transformational needs of the business– to become a true omni-channel retailer in the food/grocery space,” said Sriram Samu, VP Engineering, Customer Technology at Kroger. “Our stack has been redesigned to be cloud-native, microservices based and running both on-premises and on public clouds. We have been testing and evaluating YugabyteDB as the distributed SQL database running natively inside Kubernetes to power the business-critical apps that require scale and high availability. We have been very impressed with its SQL feature depth and wire compatibility with Postgres.”
In this post we’ll highlight what’s new in 2.0, performance benchmarks, Jepsen test results, plus a preview upcoming features currently in Beta.
The Most Powerful, PostgreSQL-Compatible Distributed SQL
Thanks to the many passionate users who have tested the multiple beta releases starting May 2018, YSQL has matured into arguably the most powerful distributed SQL database on the market today. Below are just a few of its PostgreSQL-compatible features.
- All simple and complex PostgreSQL data types – including Arrays, User Defined Types and Range
- Built-in functions and expressions
- Distributed transactions with serializable and snapshot Isolation levels
- Indexes – including partial indexes
- Foreign keys for enforcing referential integrity
- Views and subqueries for accelerating application development
- Role based access control (RBAC) for securing data access
- Advanced functionality such as stored procedures and triggers are supported out-of-the box
For a more in-depth tour check out the “PostgreSQL Compatibility in YugabyteDB 2.0” blog post.
Building a YSQL-powered application is easier than ever before with quickstarts and client drivers for the most popular languages including:
High Performance Meets Cloud-Native
YSQL is not only PostgreSQL compatible and Jepsen tested, but is also blazing fast! The latest SQL benchmarks on AWS demonstrated that YSQL is 10x more scalable than the maximum throughput possible with Amazon Aurora. Additionally, inserting 50M unique rows using prepared-bind INSERT statements with 256 threads operating in parallel, YSQL achieved a write throughput of 45k operations with a latency of mere 4.5ms! Compared to other distributed SQL offerings on similar hardware profiles, this throughput was nearly 2x that of AWS Aurora (at 2x lower latency) and almost 5x of CockroachDB (at 8x lower latency). Yugabyte CQL (YCQL) API achieves 3x higher throughput at 3x lower latency compared to Aurora.
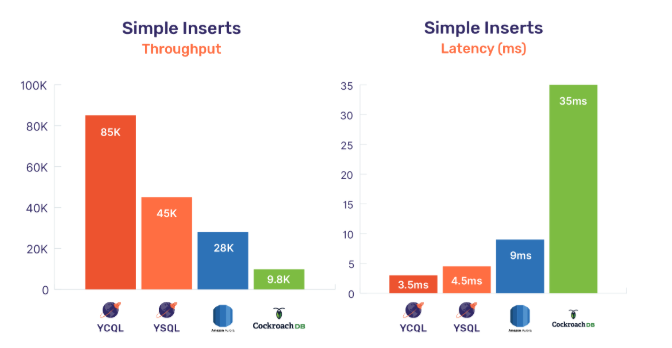
For more details on these benchmarks including distributed transaction performance, check out the 2.0 performance benchmarks blog.
Extreme Resilience, Backed by Official Jepsen Tests
The 1.2 release from earlier this year shipped with Jepsen verification of the Cassandra Query Language-inspired, semi-relational Yugabyte Cloud QL (YCQL) API. Given that DocDB, YugabyteDB’s underlying distributed document store, is common across both the YCQL and YSQL APIs, YSQL too passed official Jepsen safety tests [Edit] (with the exception of transactional DDL support, which almost no other distributed SQL database vendor supports, and we plan to support soon. The real-world impact of this open issue is really small as it is limited to cases where DML happens before DDL has fully finished).
The primary focus of the YSQL Jepsen testing this go around was to test the new serializable isolation level for distributed transactions where isolation stands for the “I” in ACID. As a fully-relational SQL API, YSQL supports both serializable and snapshot isolation while the semi-relational YCQL API supports only the snapshot isolation level.
You can learn more about the YSQL Jepsen results and our broader failure testing initiative by reviewing “YugabyteDB’s Distributed SQL API Jepsen Test Results” or by joining us on Oct 16 for the “Reviewing Jepsen Test Results for Correctness in YugabyteDB 2.0” webinar with Kyle Kingsbury, the creator of the Jepsen framework.
Online Migration from Traditional RDBMS & NoSQL with Blitzz
Enterprises can now achieve a zero-downtime migration from a variety of databases like Oracle, SQL Server, MySQL, MongoDB, DynamoDB, Apache Cassandra, PostgreSQL to YugabyteDB using Blitzz, a distributed data replication software. Blitzz plugs into the CDC stream of the source databases to automatically migrate not only the table data but also the associated metadata (definitions of tables, indexes and views).
The Road Ahead
What can you look forward to beyond YugabyteDB 2.0? Let’s take a look at some of the features currently in Beta.
Change Data Capture
Change Data Capture (CDC) allows external clients to subscribe to modifications happening to the data in a database. This is a critical feature in a number of use cases, including the implementation of an event-driven architecture which uses a message bus (such as Apache Kafka) to propagate changes across multiple microservices. YugabyteDB’s CDC design is the first of its kind in the realm of distributed databases. Why? Because YugabyteDB permits the continuous streaming of data without compromising on the foundational “global consistency” benefit that enables any node to process writes independent of other nodes and that too with full ACID guarantees. Instructions on how to stream data out to Apache Kafka or a local file from a YugabyteDB 2.0 cluster can be found in the official documentation.
Two Region Multi-Master & Master-Follower Clusters
By default, multi-region clusters in a Google Spanner-inspired, globally-consistent database architecture have their data automatically distributed across nodes across three or more regions. The obvious benefits include native region-level failover and repair, as well as the ability to serve low latency reads from the nearest region. However, the laws of physics mandate that write requests incur Wide Area Network (WAN) latency and the associated unpredictability. This being the case, what if you want horizontal write scalability, native zone failover and repair, plus high performance, all within a single master region? Also, what if you also have a secondary region acting as a failover/follower region for disaster recovery? What if you also want the secondary region to act as another master for the same data? The prerequisite here is that the application has to be architected to handle the downsides of unavailability of recently committed data in the master-follower configuration as well as account for potentially conflicting writes in the master-master configuration.
The mandatory “three or more regions” requirement inherent to Spanner-inspired databases has meant that the above-mentioned two-region deployments with master-follower and multi-master configurations are considered impossible. The impossible has now become possible with the YugabyteDB 2.0 release. Both multi-master and master-follower configurations are now supported. While the nodes in “master” clusters use Raft-based synchronous replication, the above cross-region configurations use asynchronous replication that builds on top of the CDC capabilities discussed earlier. Detailed architectural overview and documentation are now available to help you get started with this new feature.
Deep Ecosystem Integrations
No mission-critical software lives in a world of its own. Fortunately, YugabyteDB 2.0 is compatible with and integrates with many popular technologies developers are already familiar with. A key benefit of YugabyteDB leveraging PostgreSQL’s mature query layer is that extensions, tools and sample databases work out-of-the-box. Following are a few examples.
PostgreSQL Extensions
The following extensions are officially tested to work with YugabyteDB 2.0.
Note that since YugabyteDB’s storage architecture is not the same as that of native PostgreSQL, PostgreSQL extensions especially those that interact with the storage layer are not expected to work as-is on YugabyteDB. We intend to incrementally develop support for as many extensions as possible.
New Cluster-Aware JDBC Driver
As an attempt to simplify things even further, we’re working on a cluster-aware version of the standard JDBC driver, called Yugabyte JDBC. This driver can connect to any one node of the cluster and “discover” all the other nodes from the cluster membership that is automatically maintained by YugabyteDB.
Events such as node additions, removals and failures are asynchronously pushed to this client driver, resulting in the applications staying up-to-date with cluster membership changes. Operations engineers neither have to update the list of nodes behind the load-balancer manually nor have to manage the lifecycle of a load-balancer, thus making database infrastructure simpler and agile.
Database Visualization Tools
Following database visualization tools have been tested to work with the 2.0 release.
Sample Datasets
Following sample datasets have been tested to work with the 2.0 release.
Spring Application Framework for Java
The Spring application development framework is easily the most popular framework among enterprise Java developers. As highlighted in “Spring Data REST Services Powered By Distributed SQL – A Hands-on Lab”, YSQL already integrates with Spring Data JDBC and JPA using the PostgreSQL client drivers. However, continuing to depend on PostgreSQL client drivers as-is means that YSQL constructs (such as cluster-aware and topology-aware client drivers and ability to specify hash or range sharding) that extend PostgreSQL, cannot be introduced to developers without additional friction. To solve this problem, we are introducing the Spring Data for YugabyteDB module. The module currently supports both JDBC and JPA modes and is currently being enhanced to support the Reactive Relational Database Connectivity (R2DBC) approach. R2DBC is founded on Reactive Streams providing a fully reactive non-blocking API for SQL databases, something not possible with the blocking nature of JDBC.
Powering Scalable GraphQL Apps the Easy Way
Modern consumer apps have users and data that are distributed all over the world. Cloud-native patterns allow developers to even spread compute infrastructure globally. However, building these applications involves putting together a lot of different tools which makes it hard to move fast and slows down delivery. GraphQL has been gaining massive developer traction over the last couple years given that it simplifies such cloud-native application development. When a GraphQL engine is powered by a geo-distributed SQL database like YugabyteDB, developing massively-scalable, highly-resilient, low-latency, cloud-native applications is easier than ever before.
Here’s the step-by-step instructions on how to get started with YugabyteDB and two popular GraphQL projects, Hasura or Prisma.
Rook Kubernetes Operator
Rook is a Kubernetes-native storage orchestrator that turns distributed storage systems like YugabyteDB into self-managing, self-scaling, self-healing storage services. It automates the tasks of a storage administrator: deployment, bootstrapping, configuration, provisioning, scaling, upgrading, migration, disaster recovery, monitoring, and resource management.
YugabyteDB’s Rook operator is now available on rook.io as well as on Github. The operator extends the Rook storage operator as a custom resource, as well as provides an additional way to easily create, natively view and manage YugabyteDB within a Kubernetes cluster.
Community Momentum
Deep community engagement is the hallmark of any thriving open source project. The sense of belonging that users get by learning, sharing and contributing their knowledge to the benefit of their fellow users is a unique feeling that proprietary products can never achieve. As highlighted by the metrics below, we are pleased to report that the YugabyteDB community is experiencing phenomenal growth. We anticipate that the momentum will continue to accelerate in the coming months as more users get to experience the benefits of a 100% open source, cloud-native, high-performance distributed SQL database that is now production ready even for fully-relational applications.
GitHub Stars
Slack Users
Clusters Created
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.

 in YSQL")
