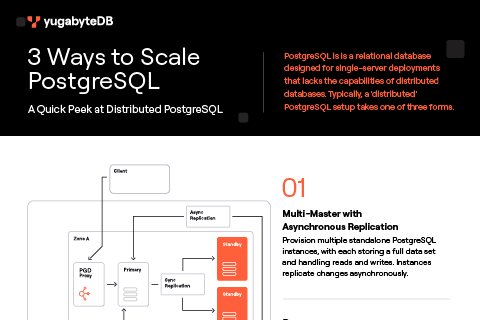
How We Test Distributed PostgreSQL Performance and Scalability
Conducting extensive and diverse performance and scalability testing ensures that YugabyteDB remains a reliable and high-performance distributed PostgreSQL database, ideal for handling mission-critical, global-scale, applications. This blog gives a deep dive into our comprehensive testing framework.