Best Practices for Deploying Confluent Kafka, Spring Boot & Distributed SQL Based Streaming Apps on Kubernetes
In our previous post “Develop IoT Apps with Confluent Kafka, KSQL, Spring Boot & Distributed SQL”, we highlighted how Confluent Kafka, KSQL, Spring Boot and YugabyteDB can be integrated to develop an application responsible for managing Internet-of-Things (IoT) sensor data. In this post, we will review the challenges and best practices associated with deploying such a stateful streaming application on Kubernetes.
Challenges of Streaming Apps
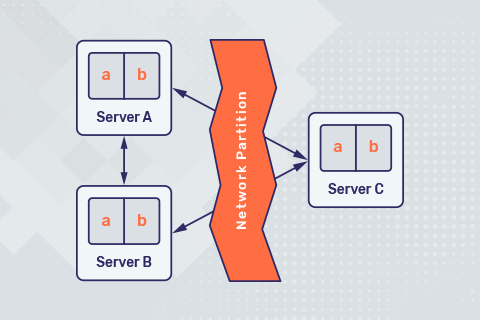
Streaming apps are inherently stateful in nature given the large volume of data managed and that too continuously.
…