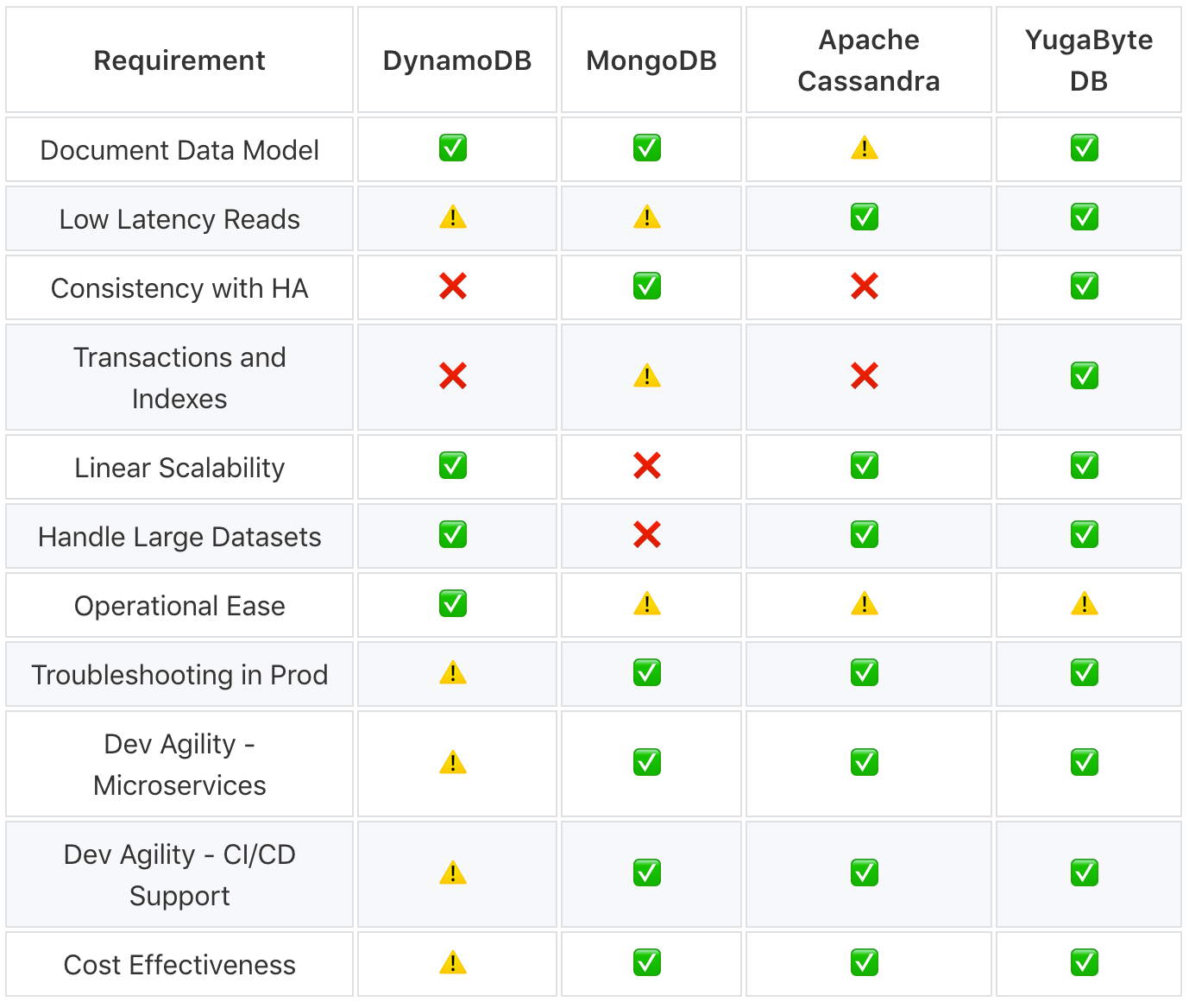
Getting Started with Falco Runtime Security and Cloud Native Distributed SQL on Google Kubernetes Engine
Falco is an incubating CNCF project that provides cloud native, open source runtime security for applications running in Kubernetes environments. Falco monitors process behaviors to detect anomalous activity and help administrators gain deeper insights into process execution. Behind the scenes, Falco leverages the Linux-native extended Berkeley Packet Filter (eBPF) technology to analyze network traffic and audits a system at the most fundamental level, the Linux kernel. Falco then enriches this data with other input streams,
…