Recapping YugaByte’s 2018 Milestones and a Preview of the 2019 Roadmap
January 8, 2019
After launching YugabyteDB in November 2017, Team YugaByte celebrated 2018 as its first full year in the market as a cloud native, transactional database company. Exhilarating is the one word that best summarizes our 2018 experience. From a product and engineering standpoint, we launched two major releases (and tens of minor releases) and saw users adopt each of the releases at an amazing pace. This story of exceeded expectations repeated itself at every other function in the company whether it be sales, marketing or recruiting. We are often told that building a database company is hard, but it certainly gets easier with our community’s passionate support and our customers’ unwavering trust.
Still on the sidelines wondering if YugabyteDB is the right choice for your application? Try it out on your own. For functional testing, we recommend installing a local cluster using either Docker or minikube/Kubernetes or simply macOS/Linux binaries. For performance testing, install a true multi-node cluster on AWS or Google Cloud and you are off to the races!
As you complete the installation steps above, review this post to learn about our top accomplishments in 2018, as well as what we have in store for you in 2019.
Critical Milestones
Two Major Releases
We announced the general availability of YugabyteDB 1.0 in May 2018 at KubeCon + CloudNativeCon Europe. Kannan, our Co-Founder & CEO, highlighted all that went into the release along with the inspiration behind creating YugabyteDB in “Announcing YugabyteDB 1.0!” . Up until the 1.0 release, smart engineers used to remind us that our vision of combining the best of NoSQL and SQL in a single transactional database designed to run on a shared-nothing architecture was very ambitious and the technology path was quite treacherous. We were able to put these concerns to rest by highlighting how we shaped our road to the 1.0 release (see the figure below). We essentially took a big hairy problem, broke it into coherent phases and then executed each phase with careful design and meticulous implementation.
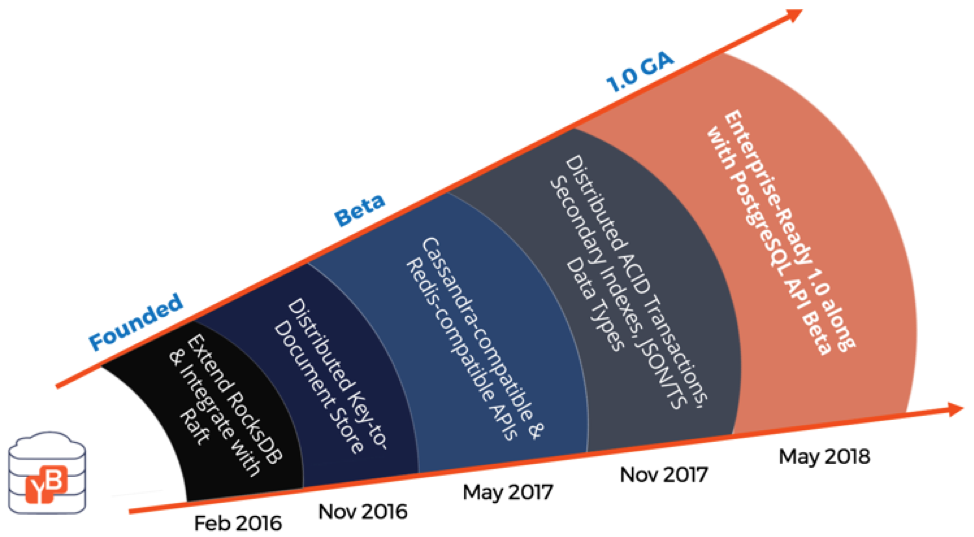
The Road to YugabyteDB 1.0
The YugabyteDB 1.1 release in September 2018 was a continuation of the work we had initiated in the 1.0 release. While we made major improvements in our two transactional NoSQL APIs, the highlight of the 1.1 release was the formal introduction of YSQL, our PostgreSQL-compatible Distributed SQL API. If making NoSQL transactional is challenging (and that’s what we achieved in the 1.x releases), then making SQL distributed is certainly a grade higher in the challenge scale. We cannot be more excited about the upcoming 2019 releases that will battle-harden YSQL and make it ready for production!
Customer Case Studies
Customer case studies are the fuel that drive the adoption of a product to the next level. We were super-excited to see multiple customers not only deploy YugabyteDB to production for business-critical use cases but even able to clearly quantify their benefits in terms of either application agility or infrastructure/labor cost reduction or both. Check out four such case studies from Narvar (a leader in post-purchase retail experience), Turvo (a next-generation logistics platform), Xignite (reliable APIs for financial market data) and CipherTrace (real-time cryptocurrency trust platform). Many more are in the pipeline, so keep an eye out at the Customers page to get continuously updated.
$16M Funding Announcement
In June 2018, we announced $16M in additional funding in a round led by Dell Technologies Capital and our previous investor Lightspeed Venture Partners. That brought our total funding till date to $24M. We are immensely grateful to the direction and support provided by Ravi Mhatre from Lightspeed Venture Partners over the last three years. Deepak Jeevankumar from Dell Technologies Capital has been an absolute pleasure to work with since joining our board. Armed with the new funding and the guidance of such visionary investors, we have been increasing our investment across all the functions of the company and in the process, bringing a truly best-in-class transactional database to users.
Benchmarks
As with any new transactional database, users want to understand the performance and correctness characteristics in fair amount of detail. To serve this purpose, we have been using YCSB for performance benchmarking and Jepsen for correctness benchmarking.
YCSB for Performance
Yahoo Cloud Serving Benchmark (YCSB) is a suite of single-key workloads that test throughput and latency in NoSQL databases. YugabyteDB 1.1 showed a 30% improvement in throughput on average compared to YugabyteDB 0.9 (released Dec 2017) as measured by YCSB operations per second across the various workload types (with 10 Million keys as the data volume). Note that short range scans improved by 80% due to a number of optimizations. We also compared the performance of YugabyteDB 1.1 with Apache Cassandra 3.11 using the YCSB benchmark. The results are even more exciting — YugabyteDB 1.1 on an average is more than 2.5x faster than Apache Cassandra 3.11.
Jepsen for Correctness
The Jepsen framework developed by Kyle Kingsbury is widely considered as the gold standard for testing correctness in distributed databases. We have been running DIY Jepsen tests against YugabyteDB for a long time now. As part of our Jepsen test suite, we run different workloads such as single key updates, single row ACID transactions and multi-row ACID transactions under a number of failures scenarios. The failure scenarios include process failures, network partitions and clock skew. For the current Jepsen tests we have tested in a loop, there are no correctness failures detected by Jepsen! Details are posted on our “Jepsen Testing on YugabyteDB” post.
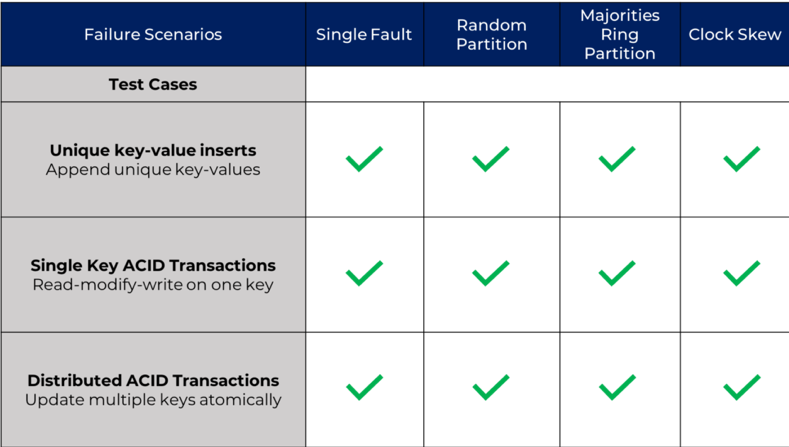
DIY Jepsen Testing Results for YugabyteDB 1.1
Community Events
We evangelized the business and technical benefits of cloud native, transactional data architectures through various community events. 2018 took us to 7 industry conferences and 12 local meetups. We even hosted 3 of these meetups at our Sunnyvale HQ.
Conferences
- KubeCon + CloudNativeCon Europe
- DockerCon North America
- Google Cloud Next
- SpringOne Platform
- PostgresConf Silicon Valley
- AWS re:Invent
- KubeCon + CloudNativeCon North America
Meetups
- Bay Area Kubernetes at NetApp HQ
- Microservices & Cloud-Native Apps at AWS Palo Alto
- Data Riders at YugaByte HQ
- NorCal Database Symposium at Oracle HQ
- Data Riders at Hacker Dojo Santa Clara
- SF Bay Cloud Native Open Infra at Oracle HQ
- Microservices Day at YugaByte HQ
- Bay Area Kubernetes at Pivotal Palo Alto
- NYC Cloud Foundry at Pivotal NYC
- Bay Area Apache Kafka at Menlo Park
- Silicon Valley Kubernetes and Cloud Native at Google Cloud HQ
- Production Ready Containers Meetup at YugaByte HQ
Videos & Slides
Videos from the above events as well as other technical content can be found on Vimeo. Slides are available at our Slideshare page.
Ecosystem Integrations
A system-of-record database such as YugabyteDB never gets deployed in a silo of its own but is rather a part of a broader business-critical data infrastructure portfolio. We developed deep integrations with other popular solutions as listed below.
- Apache Kafka & KSQL – YugabyteDB as a reliable, elastic, long-term persistent store for streaming data managed by Apache Kafka and analyzed by KSQL.
- Apache Spark – Real-time analytics using Spark Streaming & Spark SQL on top of data persisted in YugabyteDB.
- JanusGraph – YugabyteDB as the backing store for the popular graph database API.
- KairosDB – YugabyteDB as the backing store for the popular time series database API.
- Presto – Ad-hoc analytics using SQL for data stored in YugabyteDB.
- Metabase – Visualizing data stored in YugabyteDB interactively using the popular BI tool.
Real-World Sample Apps
We open sourced 3 real-world examples of fully-functioning apps that highlight how best to leverage YugabyteDB for different use cases.
- Yugastore ECommerce app – A distributed E-Commerce app built using ReactJS, NodeJS Express and YugabyteDB’s YCQL and YEDIS APIs.
- IoT Fleet Management app – A real-time fleet-management app built using Confluent Kafka, KSQL, Apache Spark, Spring Boot and YugabyteDB’s YCQL API.
- Retail ad-hoc analytics app – Ad-hoc analytics of Retail sales data using YugabyteDB’s YSQL API.
Top Blog Posts
We published 53 blog posts in 2018 covering a wide array of topics. The topics ranged from market trends to product updates to database internals. We highlighted how YugabyteDB works or how we think about a particular problem. We also had to respond a few times to FUD (Fear, Uncertainty, Doubt) against us from competition. Amid this backdrop, we have to come to believe that the only feedback that matters is that of our users and that feedback has been consistent — users tell us that, in a very short time The YugaByte Database Blog has become a trusted resource to learn about accelerating application agility through transactional, cloud native database architectures.
Following are the top 2 blogs for the top 5 categories.
Database Market Trends
- “Docker, Kubernetes and the Rise of Cloud Native Databases”
- “Why are NoSQL Databases Becoming Transactional?”
NoSQL Competitive Comparisons – Amazon DynamoDB & MongoDB
- “11 Things You Wish You Knew Before Starting with DynamoDB”
- “Are MongoDB’s ACID Transactions Ready for High Performance Applications?”
ACID Transactions & Distributed SQL
- “Yes We Can! Distributed ACID Transactions with High Performance”
- “YSQL Architecture: Implementing Distributed SQL in YugabyteDB”
YugabyteDB’s Architectural Inspiration from Google Spanner
- “Implementing Distributed Transactions the Google Way: Percolator vs. Spanner”
- “Google Spanner vs. Calvin: Is There a Clear Winner in the Battle for Global Consistency at Scale?”
Databases and Stateful Apps on Kubernetes
- “Orchestrating Stateful Apps with Kubernetes StatefulSets”
- “Understanding How YugabyteDB Runs on Kubernetes”
Looking Forward to 2019
The public cloud revolution officially kicked off in 2006 with the launch of AWS. The first decade of this revolution was dominated by enterprises using public cloud primarily as rented data centers for their existing monolithic apps that they could lift-and-shift from their private (and expensive) data centers. We are now well into the second decade of the revolution where multiple microservices (rather a single monolith) are now being built on day-1 to exploit the public cloud’s horizontal scalability, multi-region deployability and multitude of compute/storage options. At the same time, the shared and unreliable infrastructure powering the public clouds makes these microservices inherently prone to failures such as network, disk, node and more. This means microservices now have to be also architected on day-1 with extreme resilience in mind. It’s easy to argue the second decade is less about public clouds but is more about such cloud native architectural patterns that help us build and deploy microservices reliably and at scale on any platform of our choice. Tools like Docker, Kubernetes and Prometheus help in this goal but they cannot change the fundamental limitations of monolithic data architectures that slow down microservices development and deployment.
Our most important 2019 goal is simple — we want to accelerate the adoption of cloud native app and data architectures. Here are a few concrete items that we believe will make this happen.
- General availability of YSQL, the highest performance distributed SQL offering in the market.
- Additional feature depth for YCQL and YEDIS, our two transactional NoSQL offerings.
- Formal Jepsen certification – an engagement with Kyle Kingsbury, the creator of Jepsen, is in the works. This will formally certify YugabyteDB with Jepsen beyond the DIY test results we published previously.
- Managed YugabyteDB – we expect to launch a fully managed YugabyteDB service on major public cloud platforms that provides our users with the highest operational excellence possible.
- More case studies, sample apps, ecosystem integrations, blogs, community office hours and meetups/conferences with the goal of giving you more examples of how to build transactional, high-performance, ultra-resilient apps.
It’s an exciting time to be in software! However, the true promise of a software-defined business can be realized only when developers build business-critical apps on a transactional database that can stand the test of time. We believe we are creating such a once-in-a-generation technology and product in YugabyteDB. If our mission and our accomplishments thus far excite you, join us so that we can build the future together and faster.
What’s Next?
- Compare YugabyteDB in depth to databases like Amazon DynamoDB, MongoDB and Google Cloud Spanner.
- Get started with YugabyteDB on macOS, Linux, Docker and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


